Downloaded 31 times





















































This document discusses implementing a parallel merge sort algorithm using MPI (Message Passing Interface). It describes the background of MPI and how it can be used for communication between processes. It provides details on the dataset used, MPI functions for initialization, communication between processes, and summarizes the results which show a decrease in runtime when increasing the number of processors.
Introduction to MPI for parallel algorithms, overview of the presentation content.
Introducing the team members involved in the project.
Analysis objectives for merge sort using MPI, including installation and performance measures.
Required programming languages and a detailed introduction to MPI and its components.
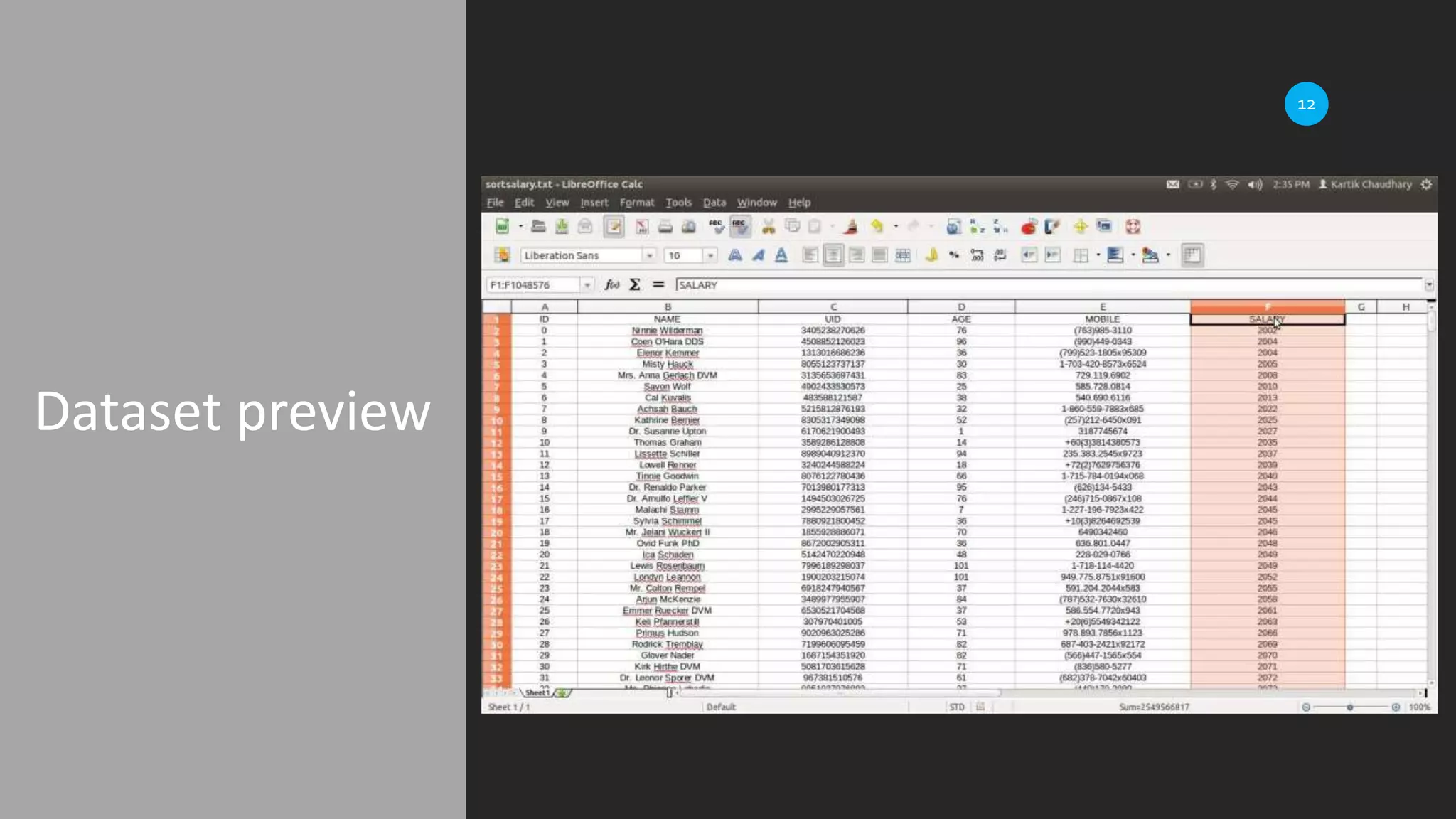
Details on dataset generation using Python's Faker library, including attributes like name and email.
Detailed explanation of MPI, including communication modes, data types, and initialization routines.
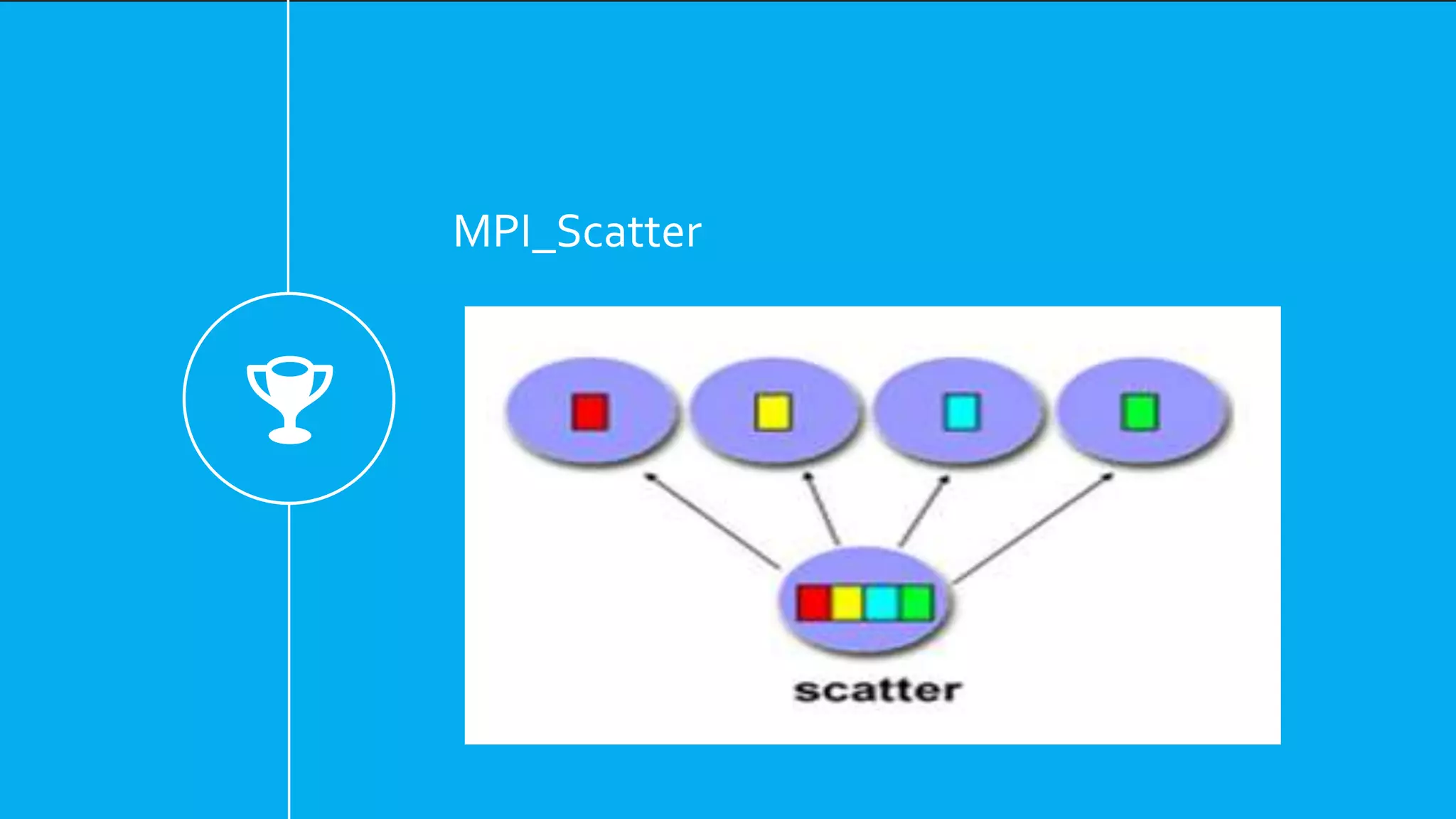
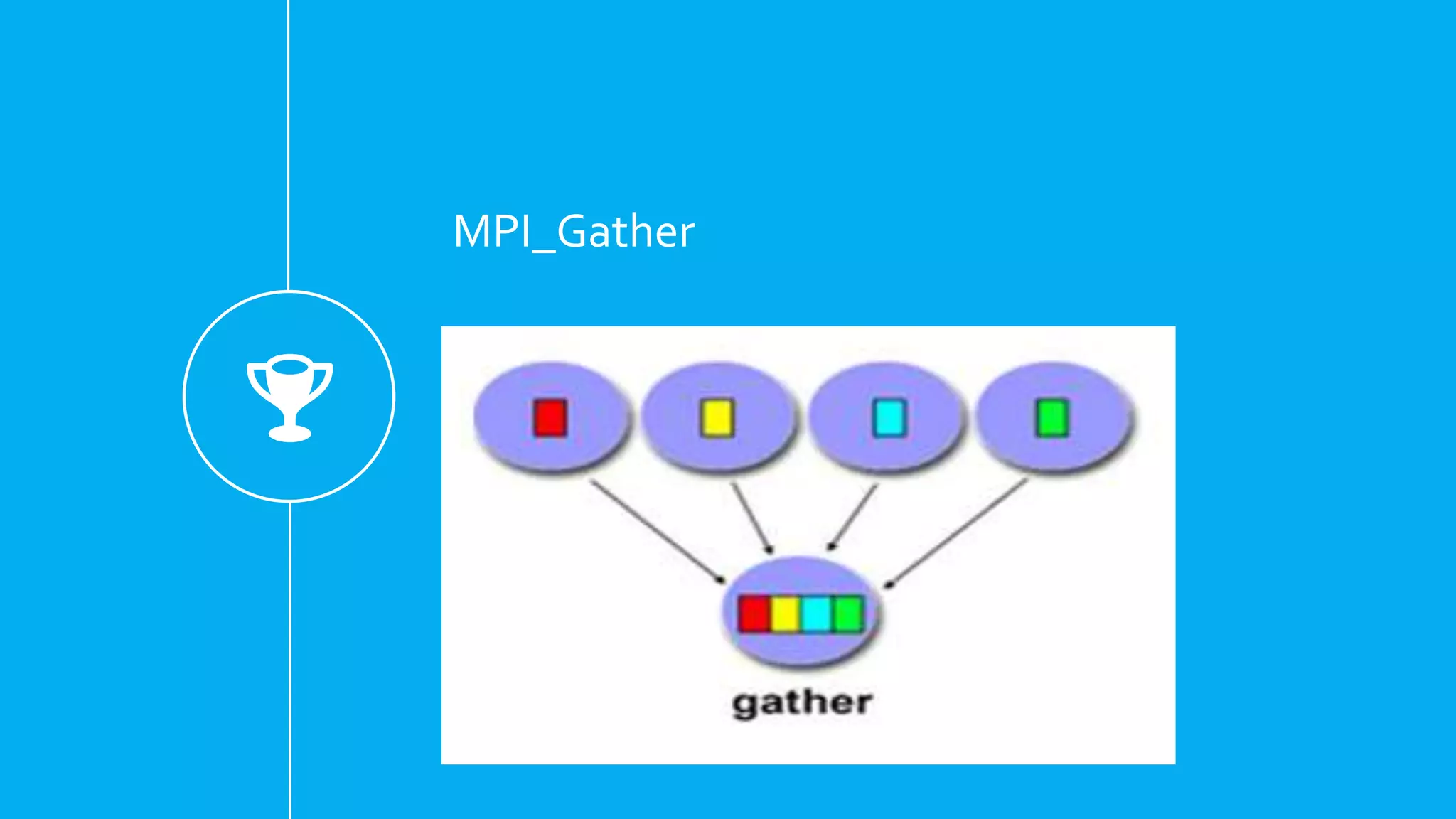
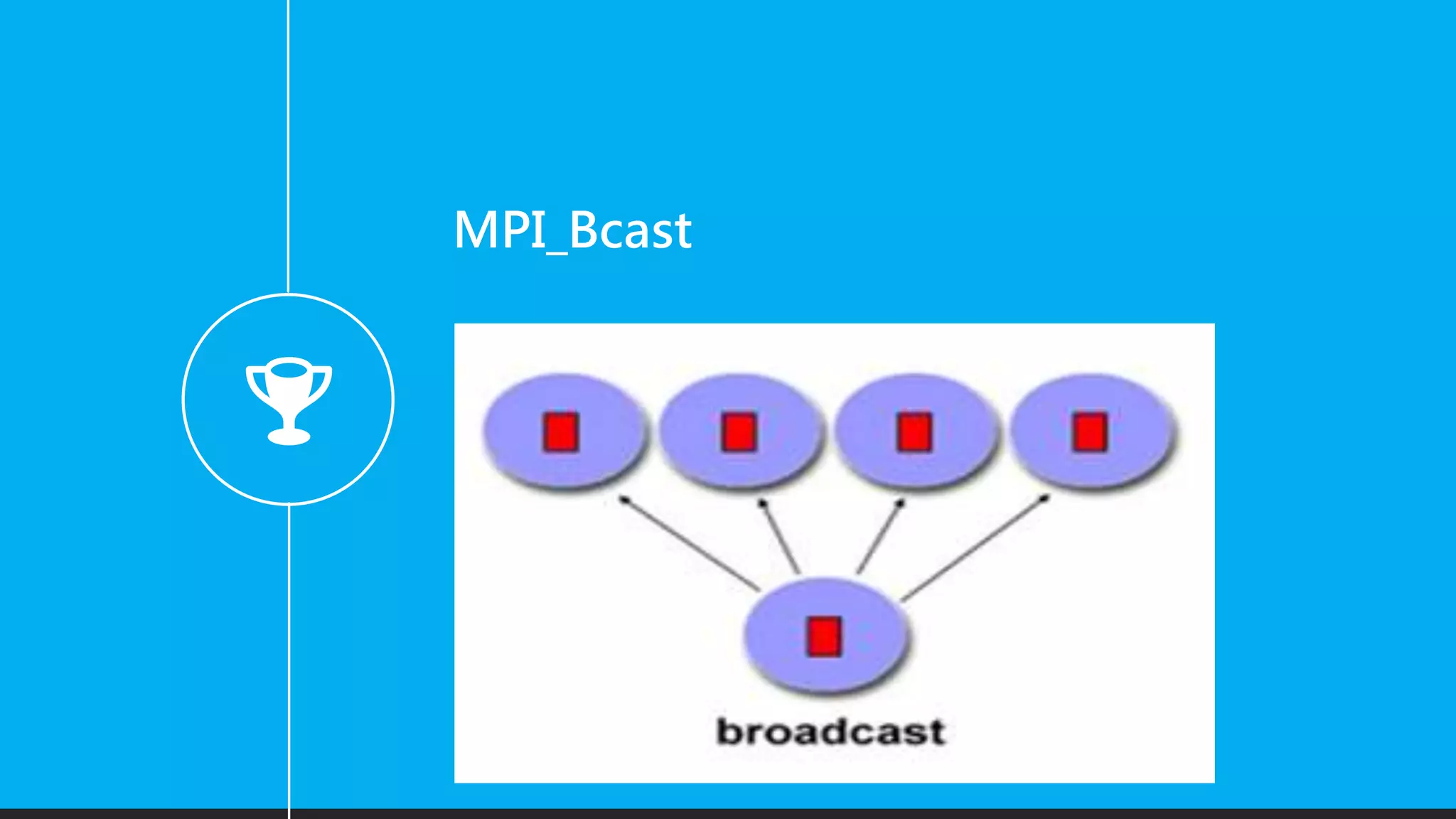
Functions for communication in MPI, including MPI_Init, MPI_Finalize, Scatter, Gather, and Broadcast.
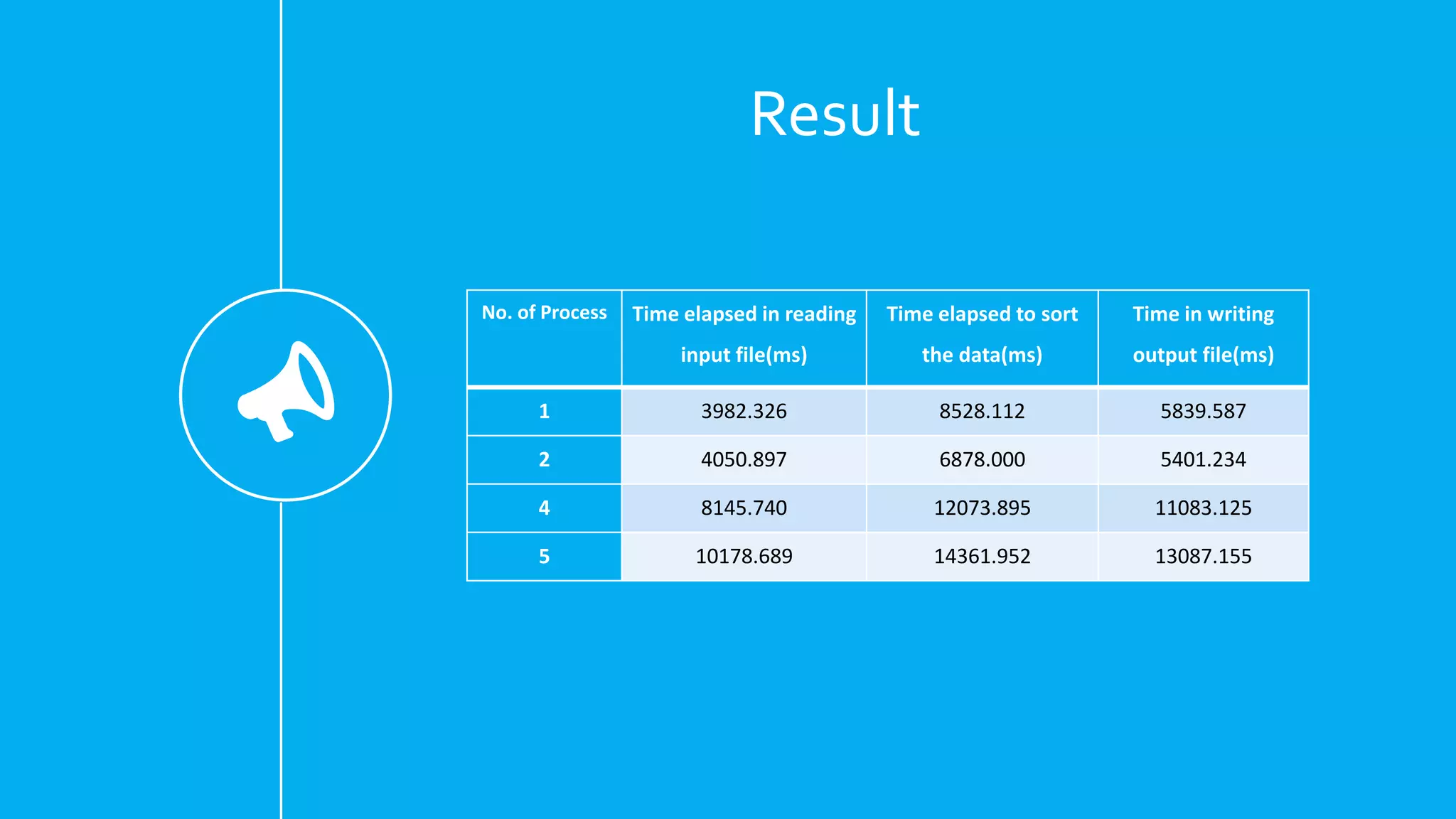
Description of the parallel merge sort implementation and performance results across different processors.
Summary of findings from using MPI for parallel processing and appreciation for the audience.



































































