Downloaded 185 times

















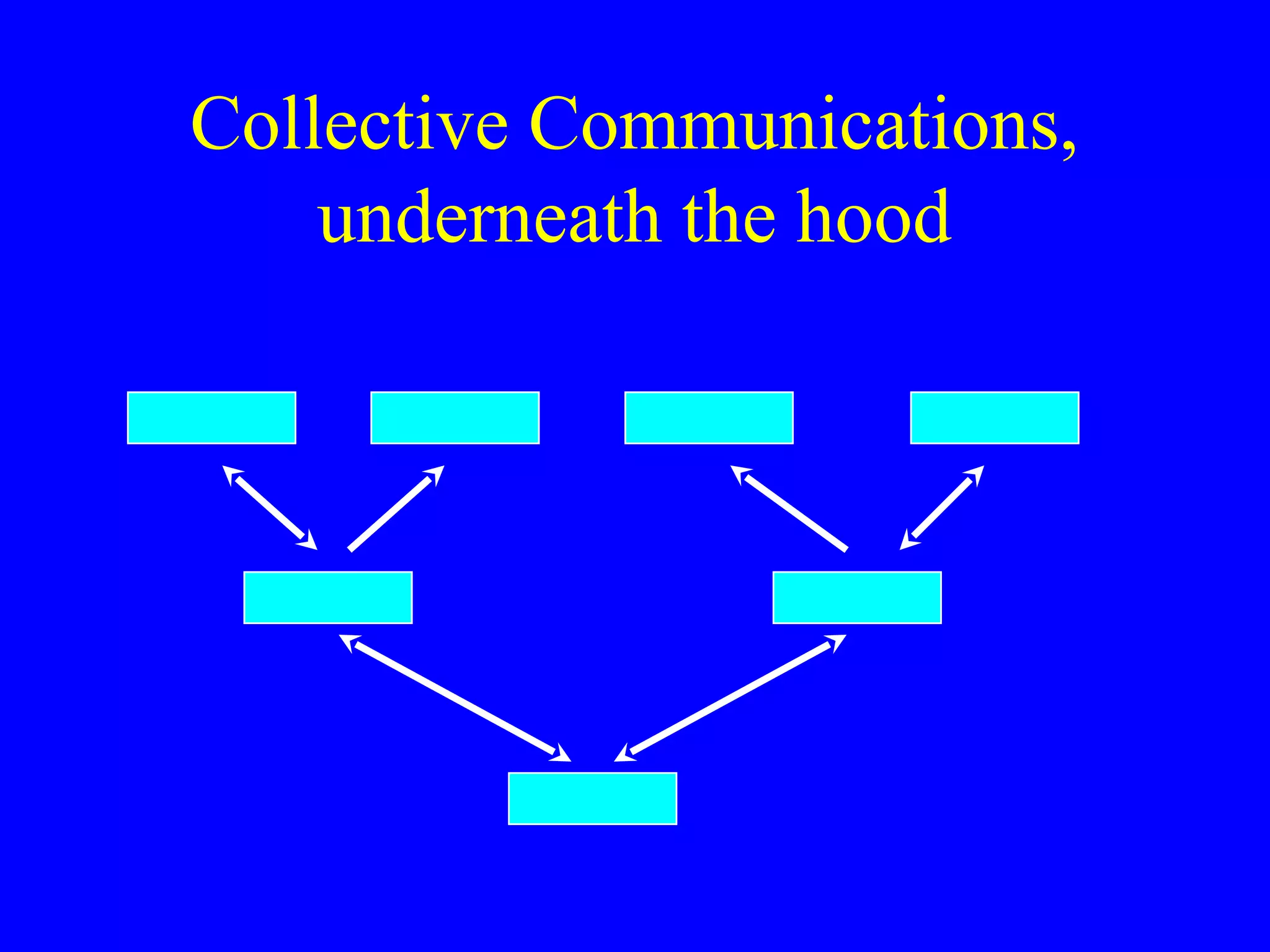



























MPI provides point-to-point and collective communication capabilities. Point-to-point communication includes synchronous and asynchronous send/receive functions. Collective communication functions like broadcast, reduce, scatter, and gather efficiently distribute data among processes. MPI also supports irregular data packaging using packing/unpacking functions and derived datatypes.
Introduction to MPI communications types: Point to Point, Collective Communication, Data Packaging.
Details of point-to-point communication including send and receive protocols: synchronous, buffered, asynchronous operations, and implementation dependencies.
Asynchronous send and receive using MPI_Isend and MPI_Irecv. Detection of message completion with MPI_Wait and MPI_Test.
Types of collective communications: Broadcast, Scatter, Gather, Reduce, emphasizing synchronous communication across multiple nodes.
Data packaging techniques in MPI for non-contiguous data include MPI_Pack for sending and MPI_Unpack for receiving.





































































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)




