Download to read offline

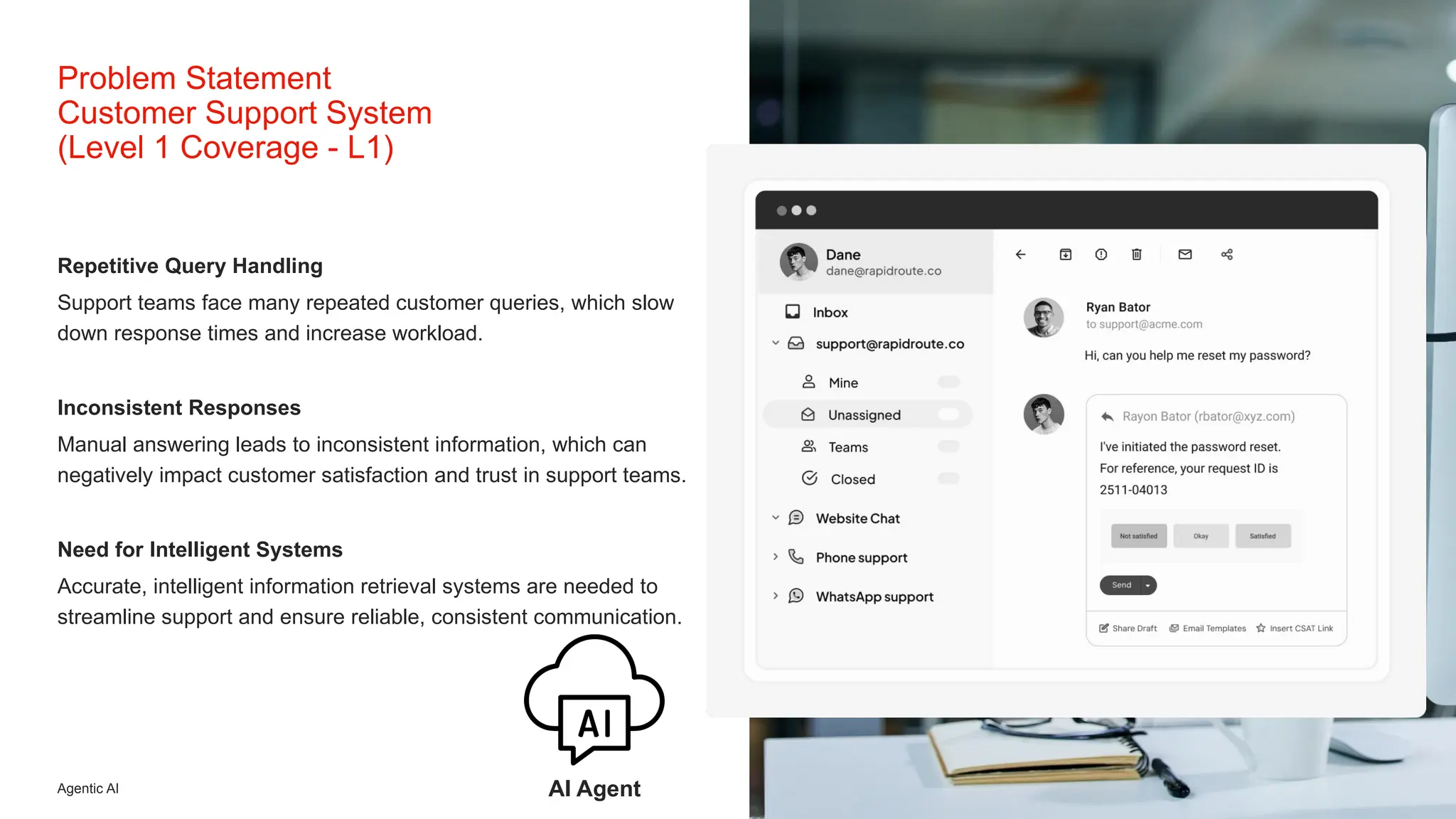
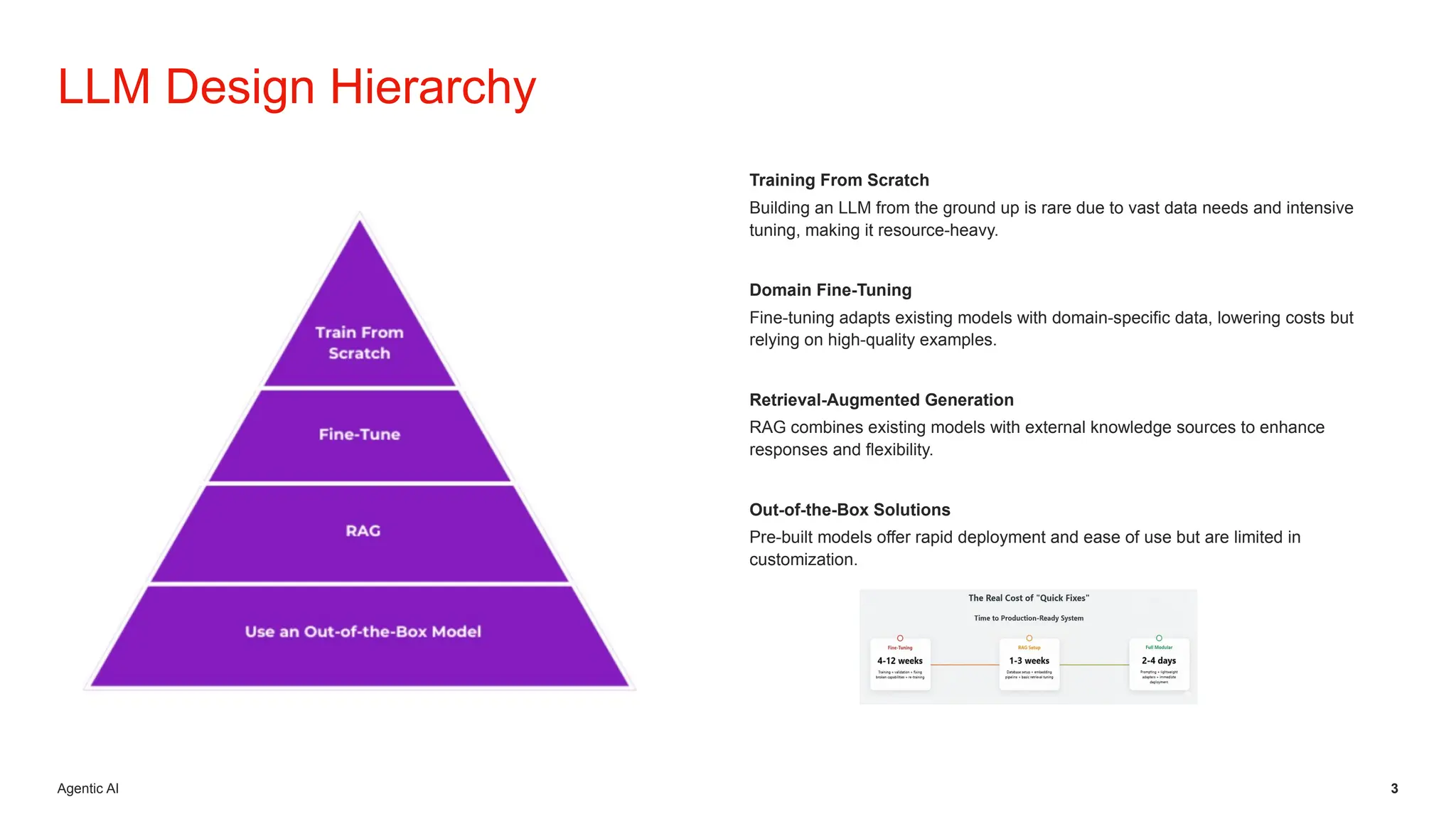
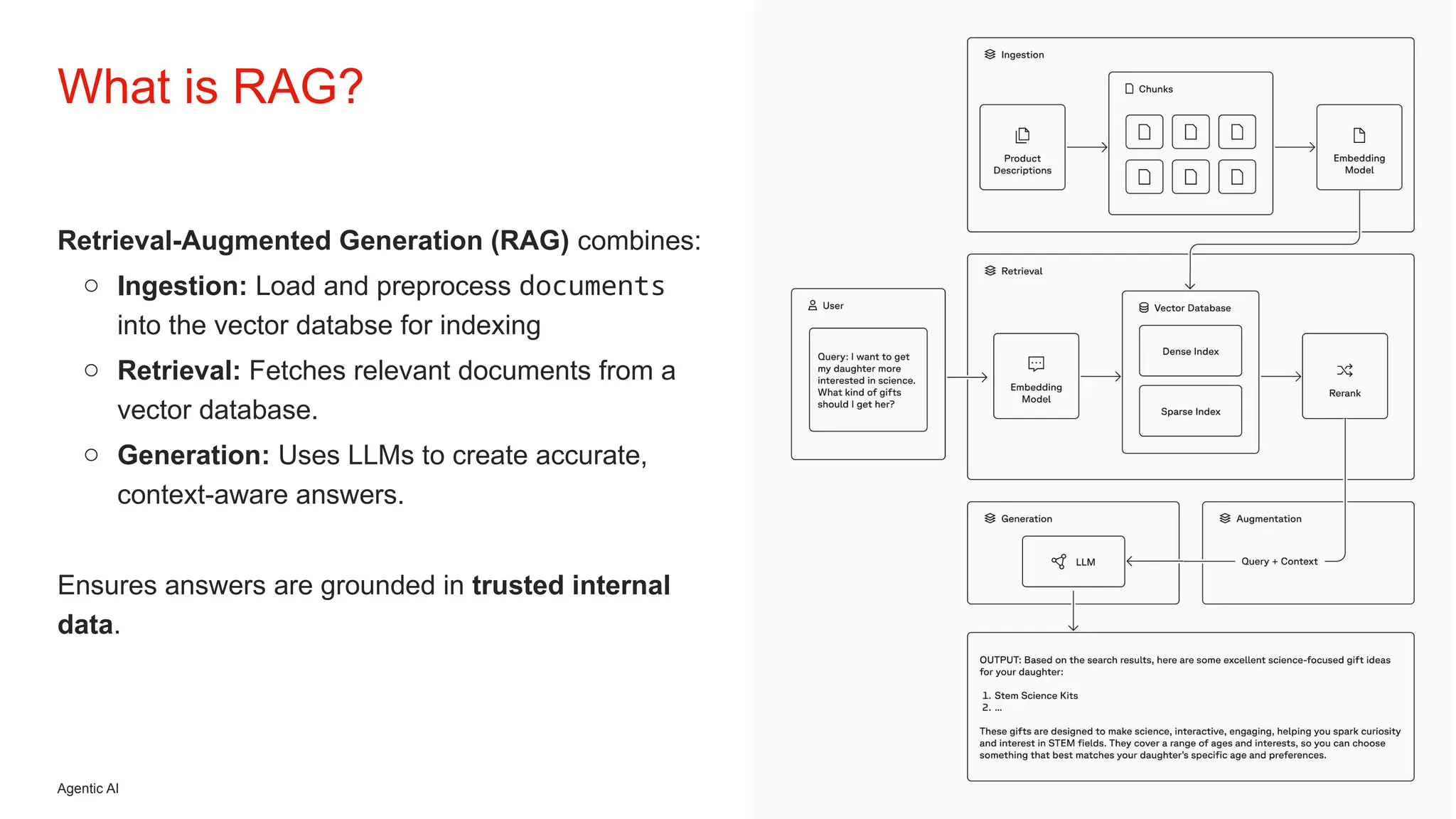

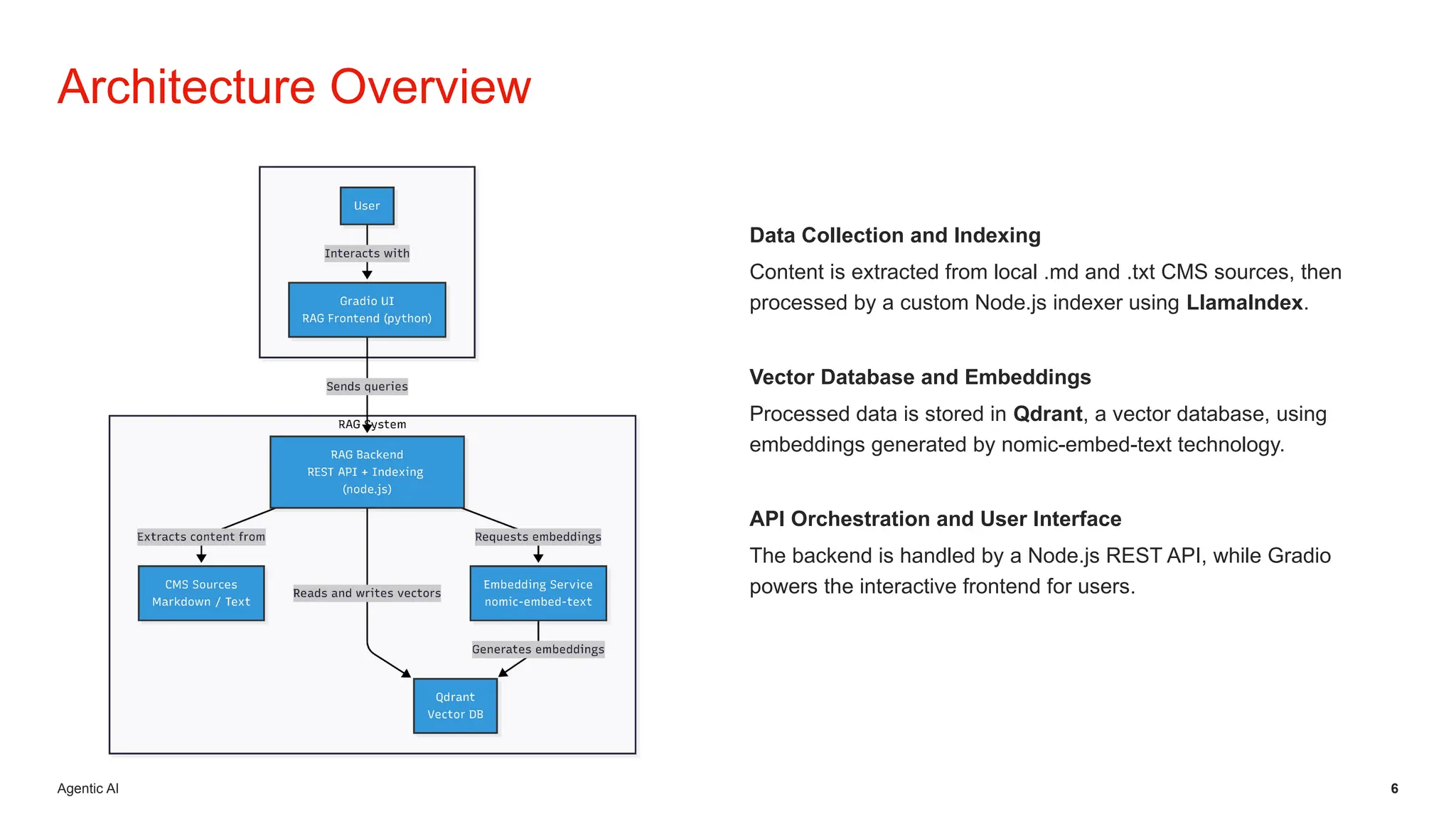





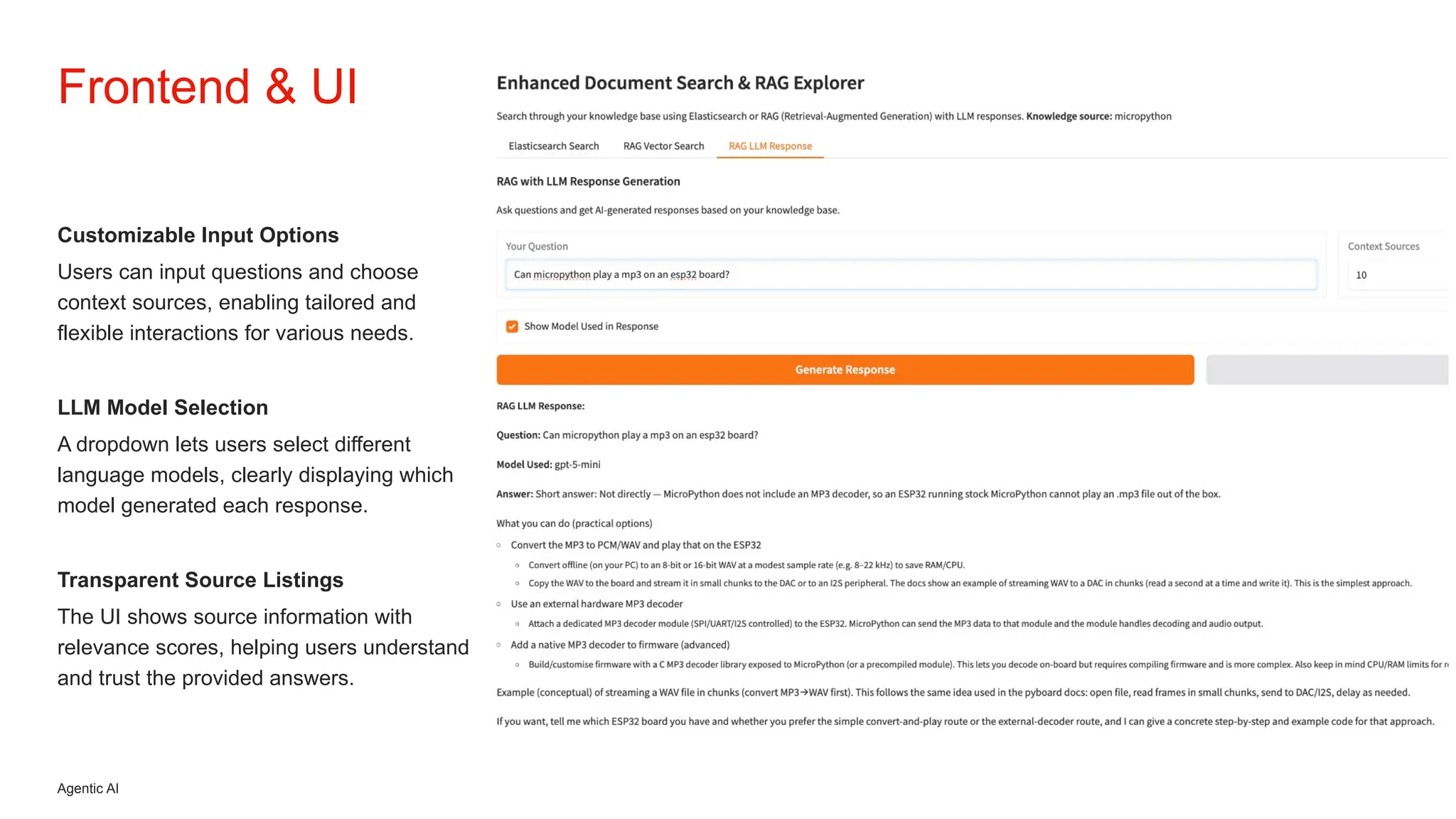




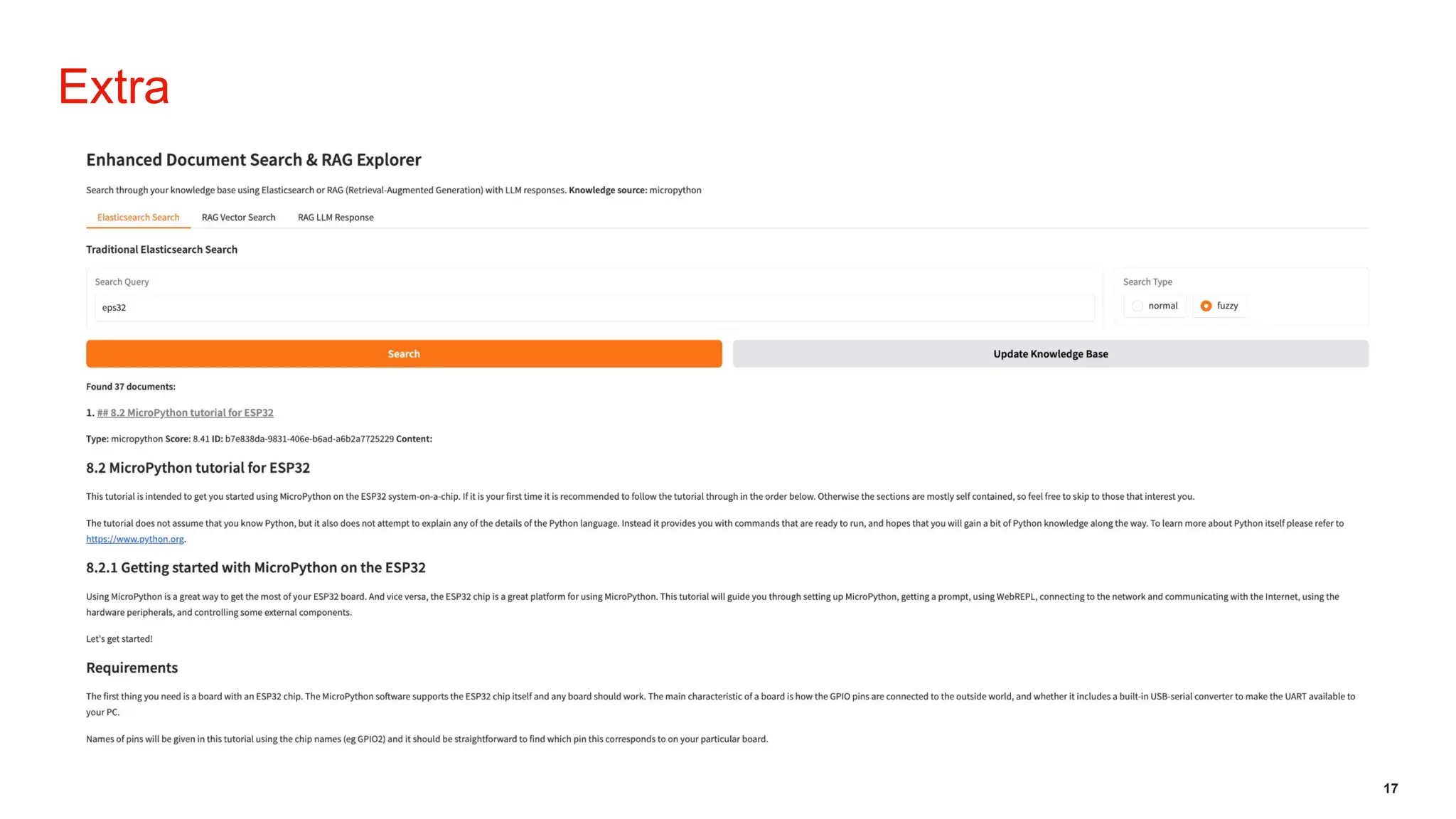
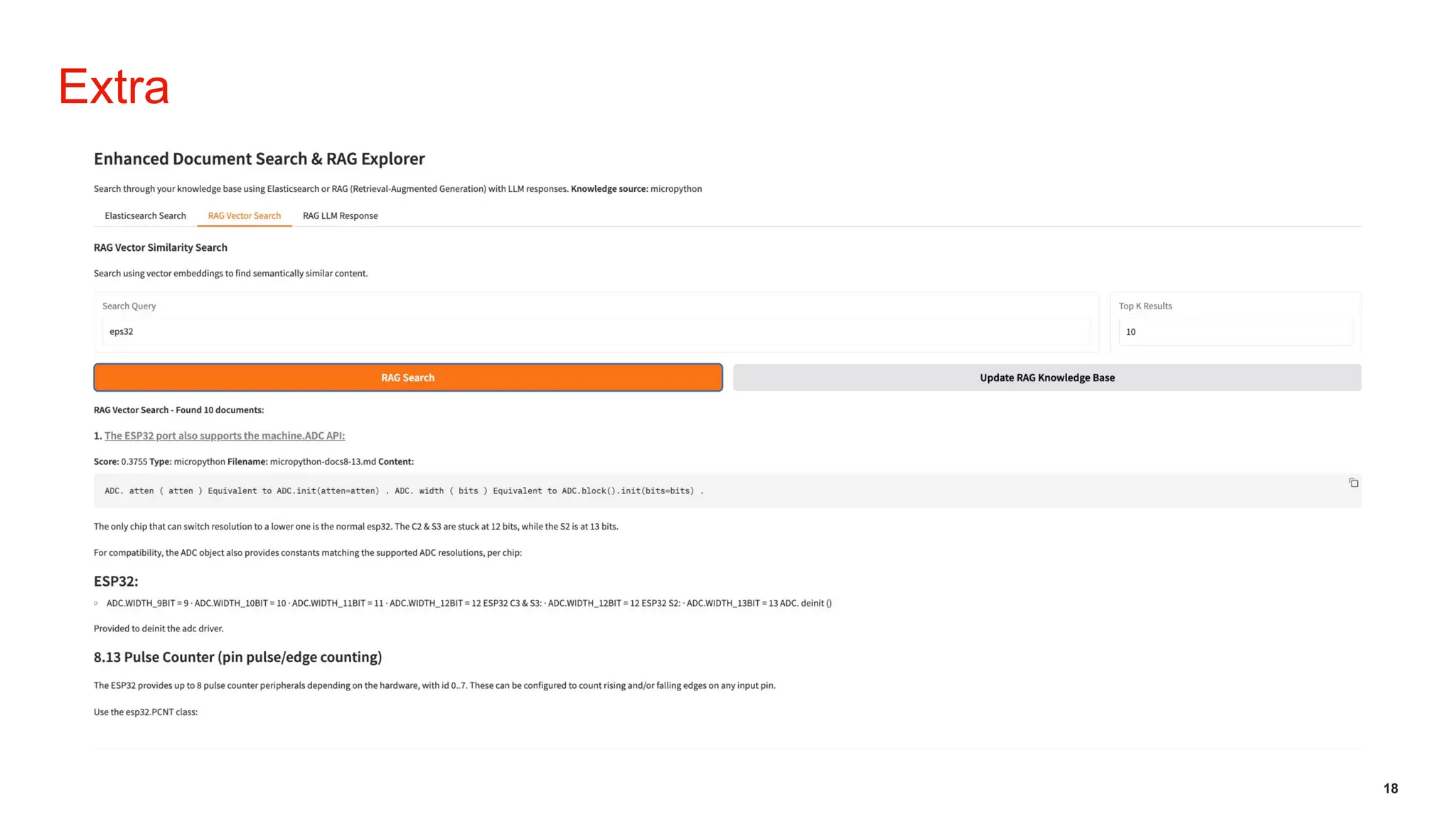
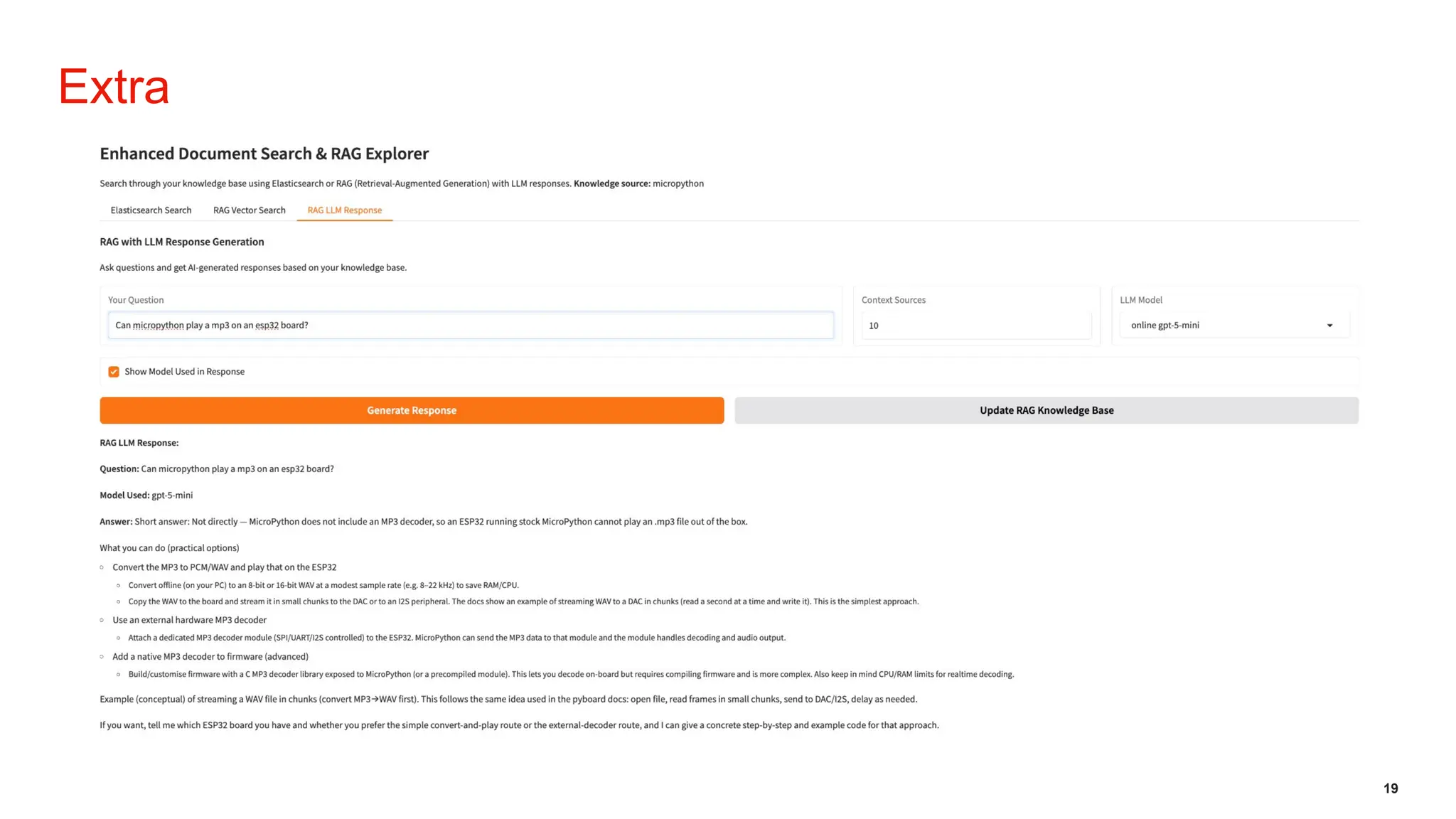




















Initiative outlines the development of a Retrieval-Augmented Generation (RAG) system to enhance Level 1 customer support operations by addressing inefficiencies related to repetitive queries and inconsistent information. The architecture employs a local, self-hosted deployment utilizing Ollama for LLM execution, Qdrant as the vector database, and Node.js orchestration, ensuring data privacy, predictable costs, and improved accuracy grounded in verified CMS knowledge sources















































