Download as PDF, PPTX




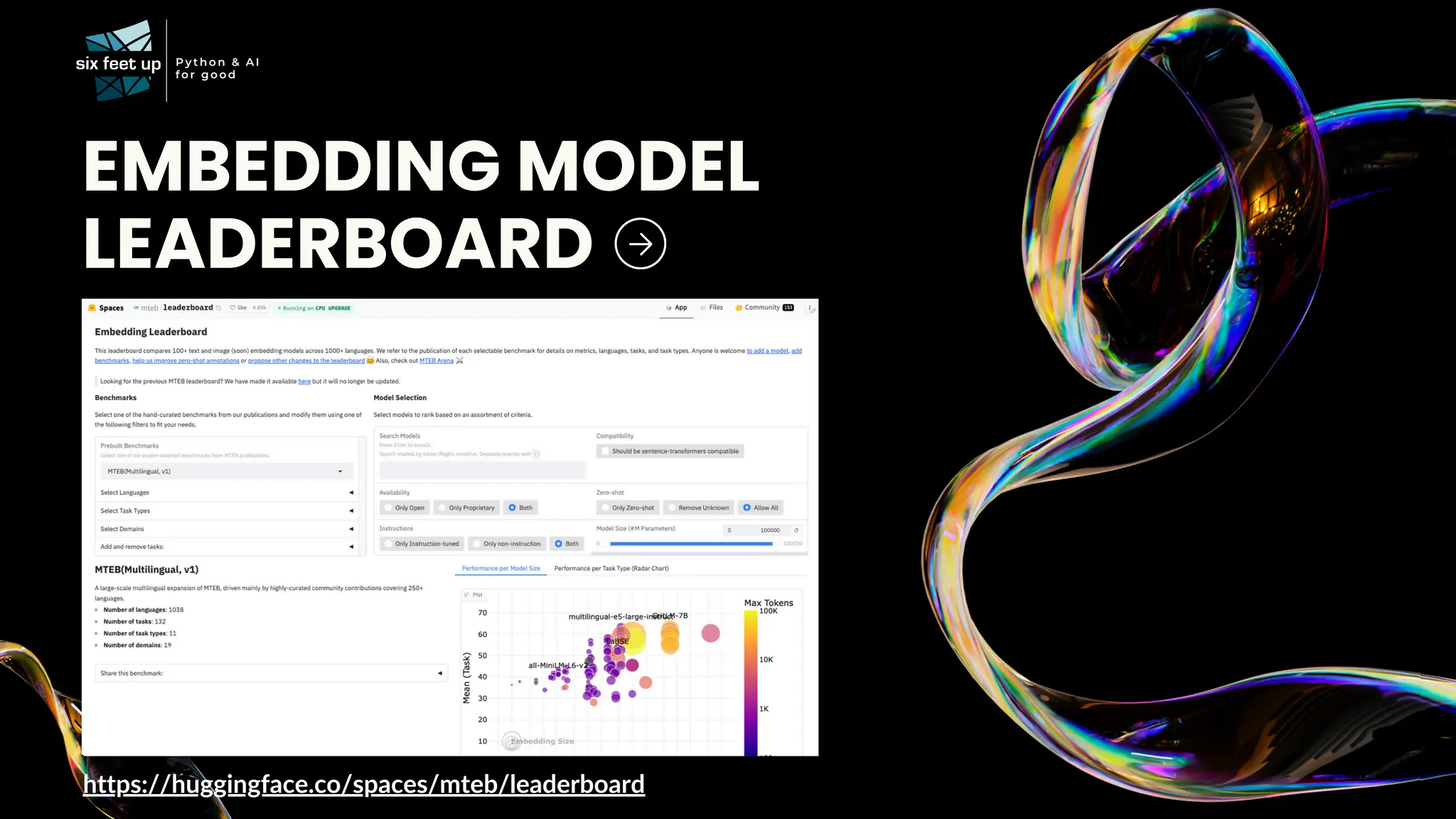
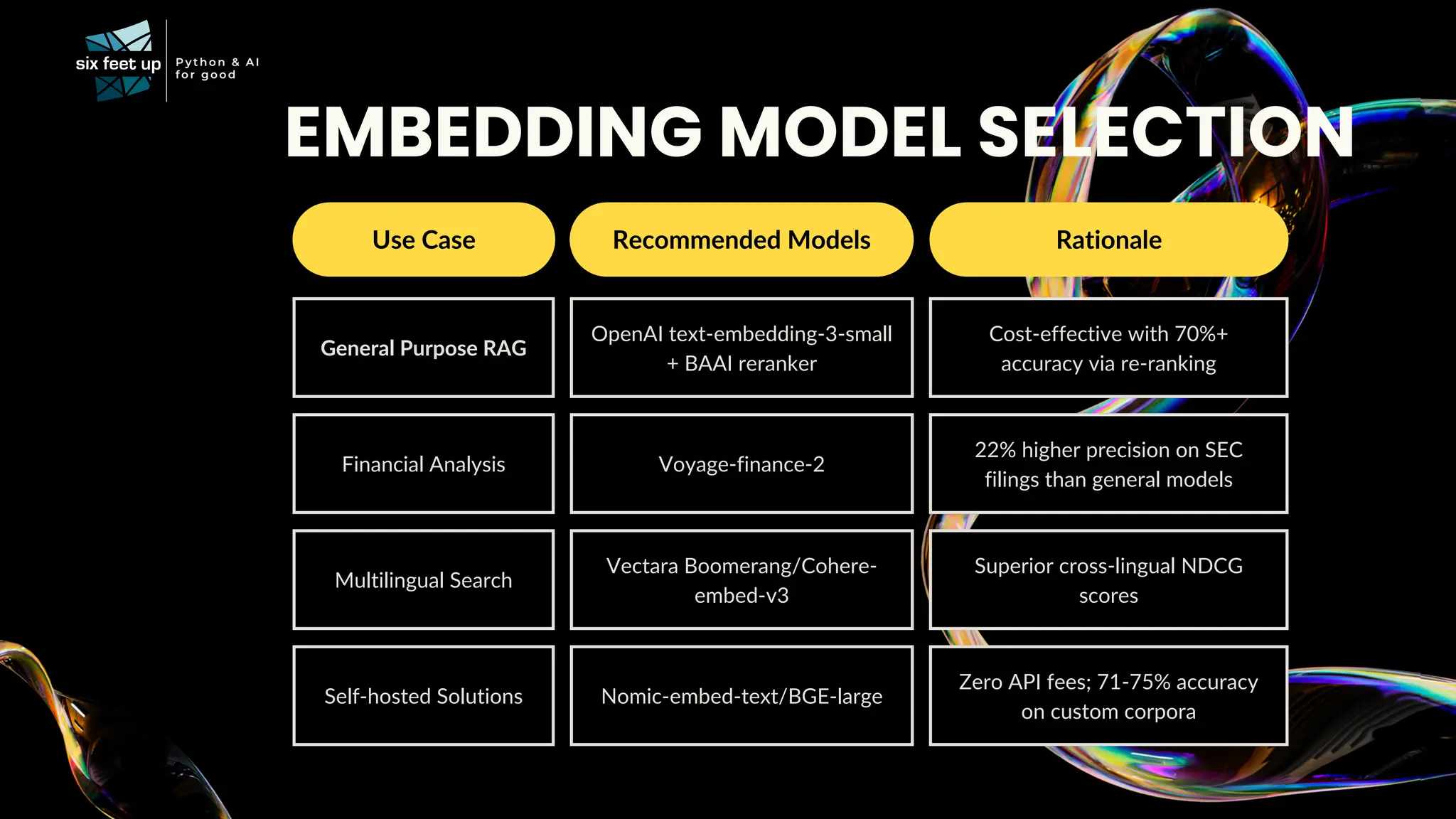








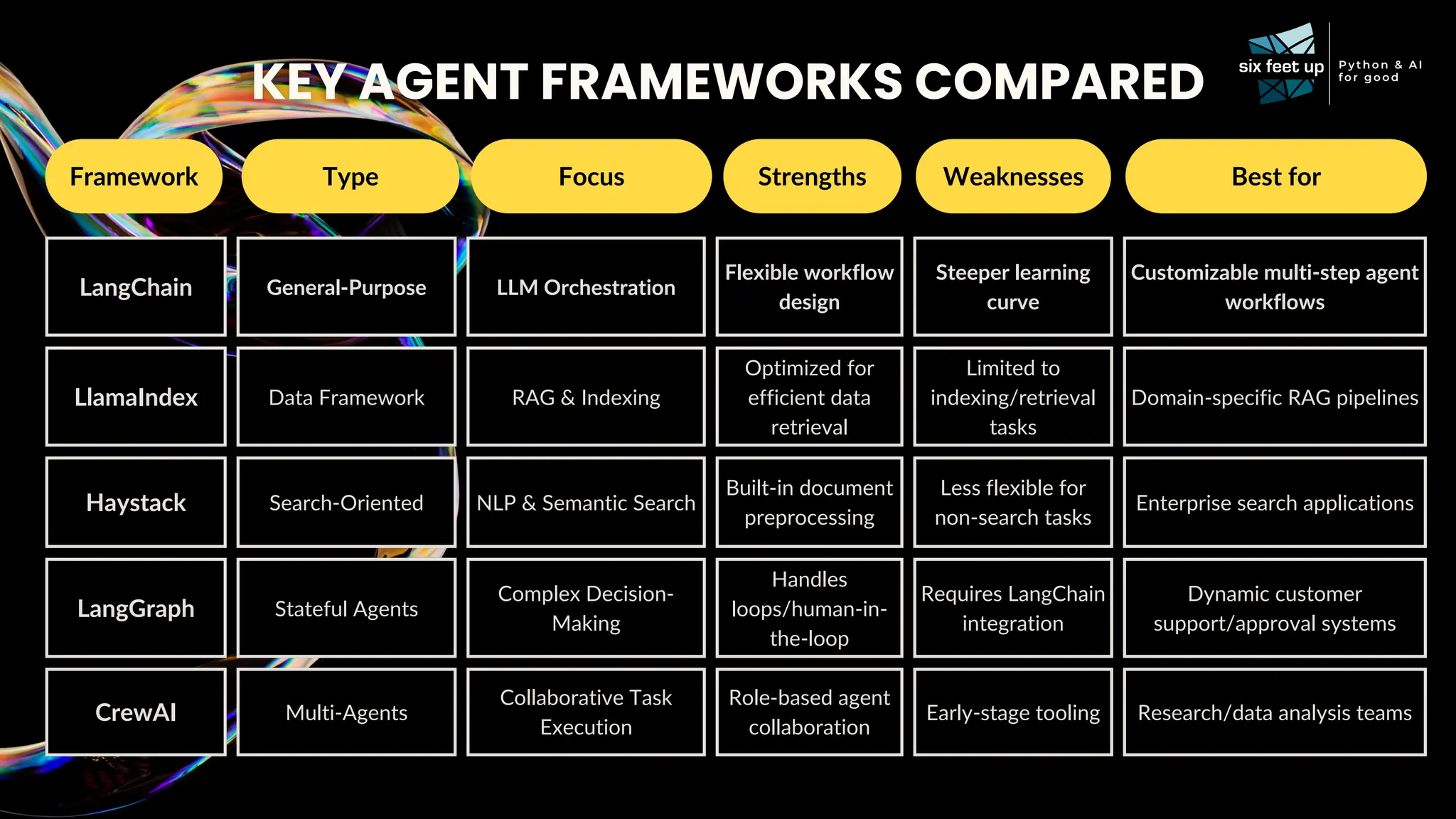


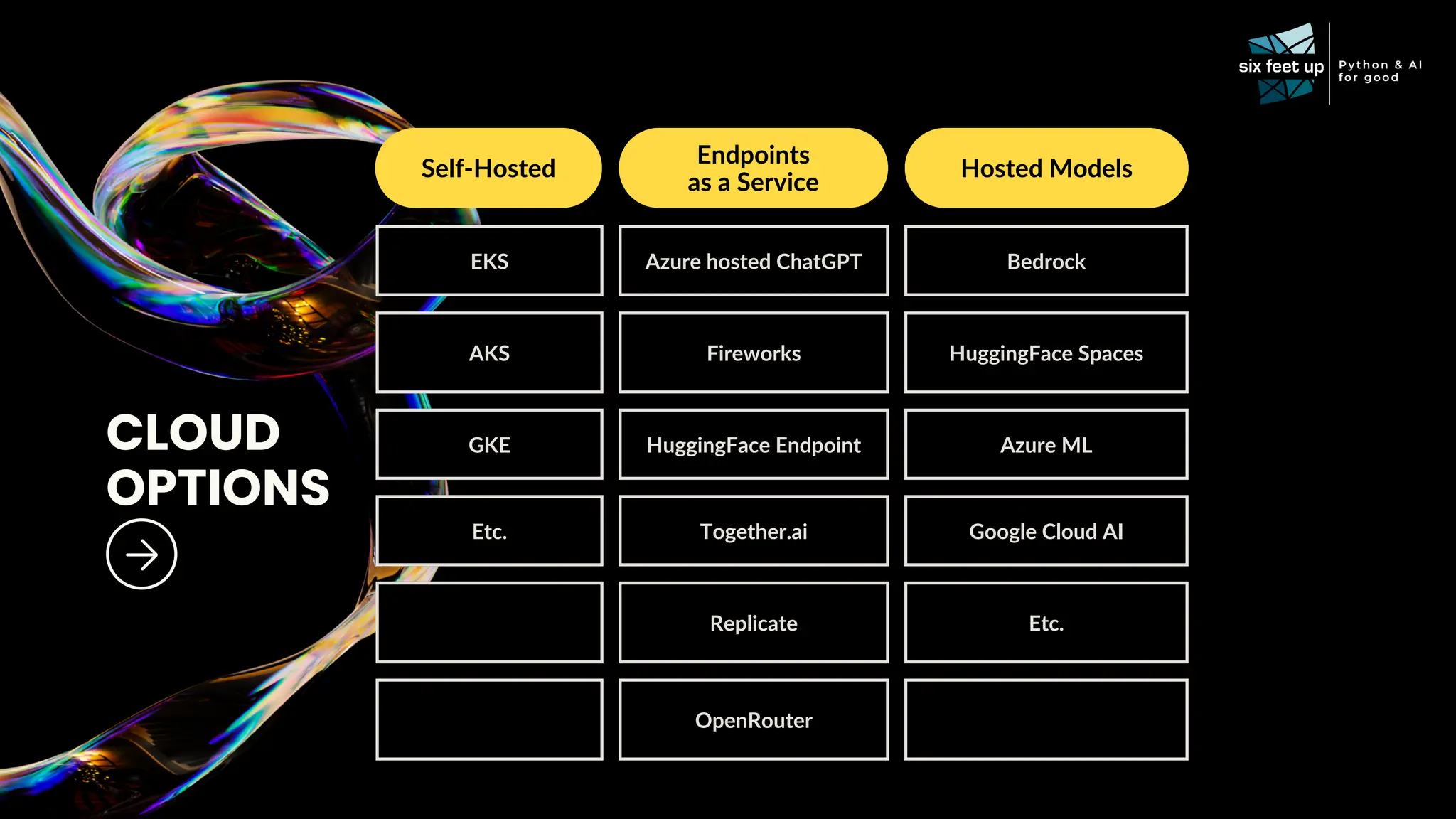

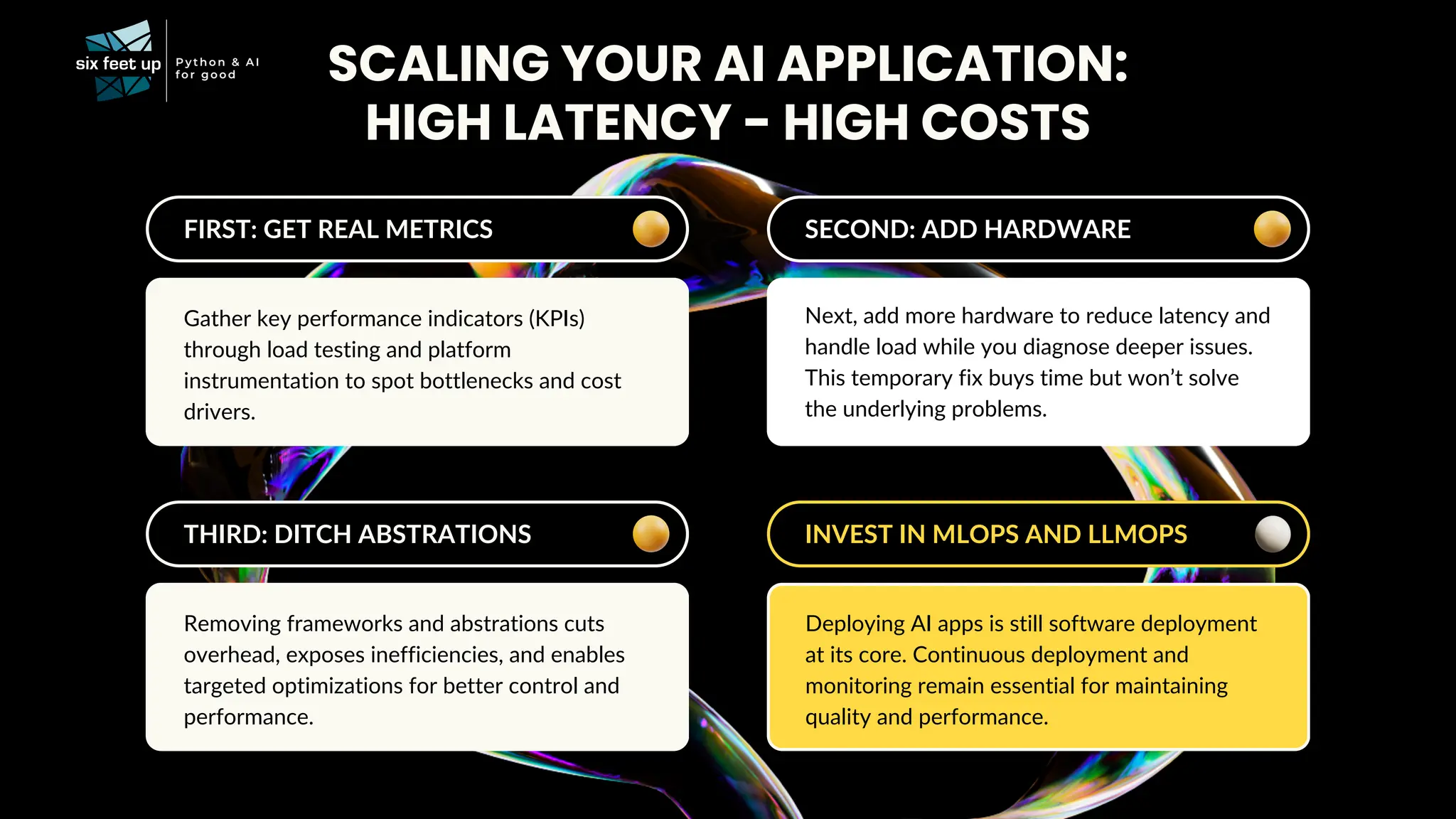


























C-level executives, directors, and product managers face the complex task of integrating AI into existing systems while addressing challenges related to data quality, scalability, interoperability, ethics, skill gaps, and security compliance. Join Calvin Hendryx-Parker — AWS Hero and CTO of Six Feet Up, the premier AI and Python agency in the U.S. — for this interactive talk exploring generative AI technologies. You’ll gain ready-to-use resources and a clear understanding of how to roll out AI in your organization. What You’ll Learn: AI Implementation Strategies: Get practical tips on evaluating and integrating open source and closed AI models, addressing governance, compliance, and scalability. Real-Case Demo: Explore what it takes to leverage generative AI technology using RAG. Team Enablement: Discover how other companies are fostering innovation internally. Walk away with the tools and insights you need to confidently lead your organization’s AI journey.



















































![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)




