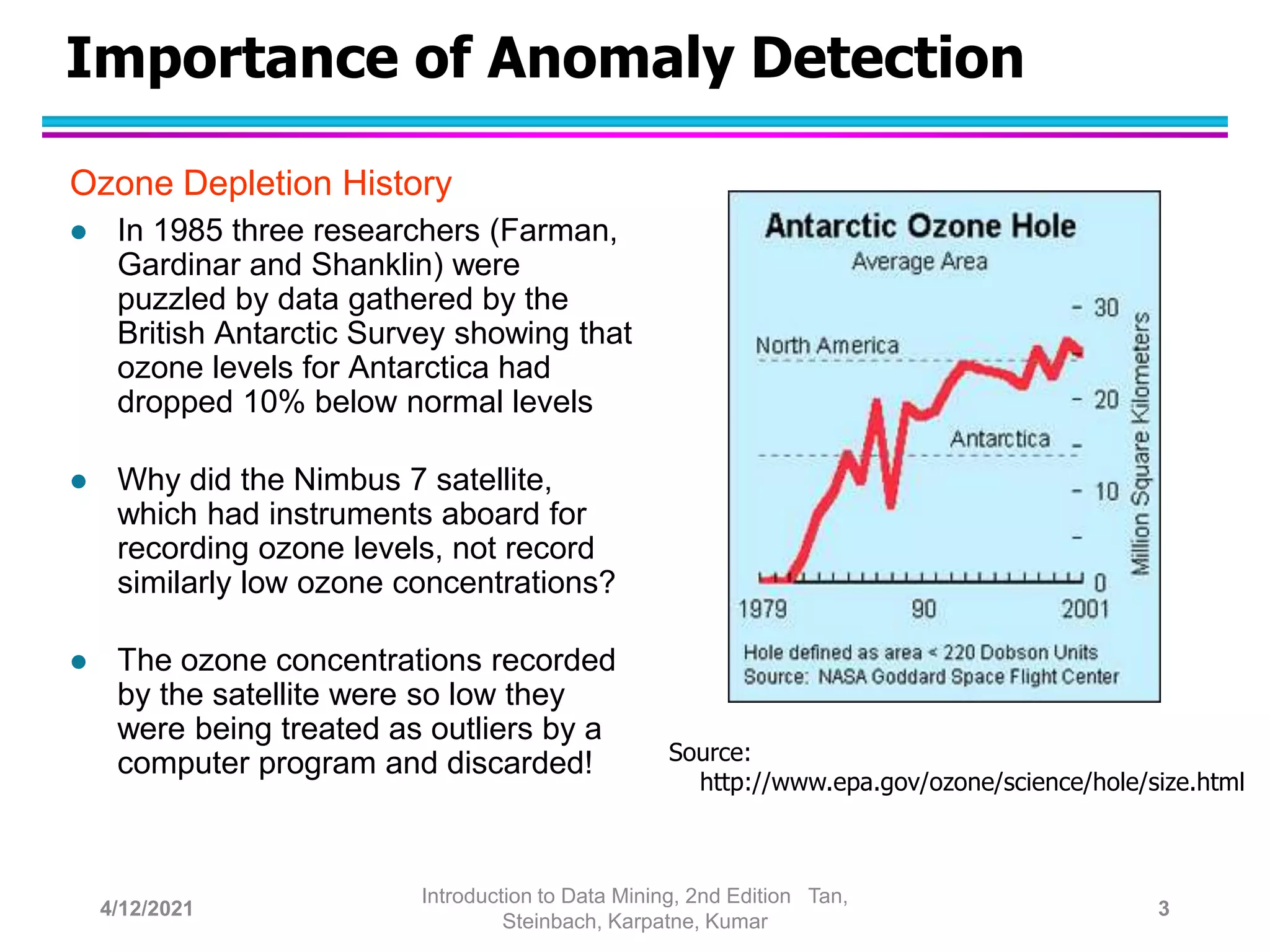
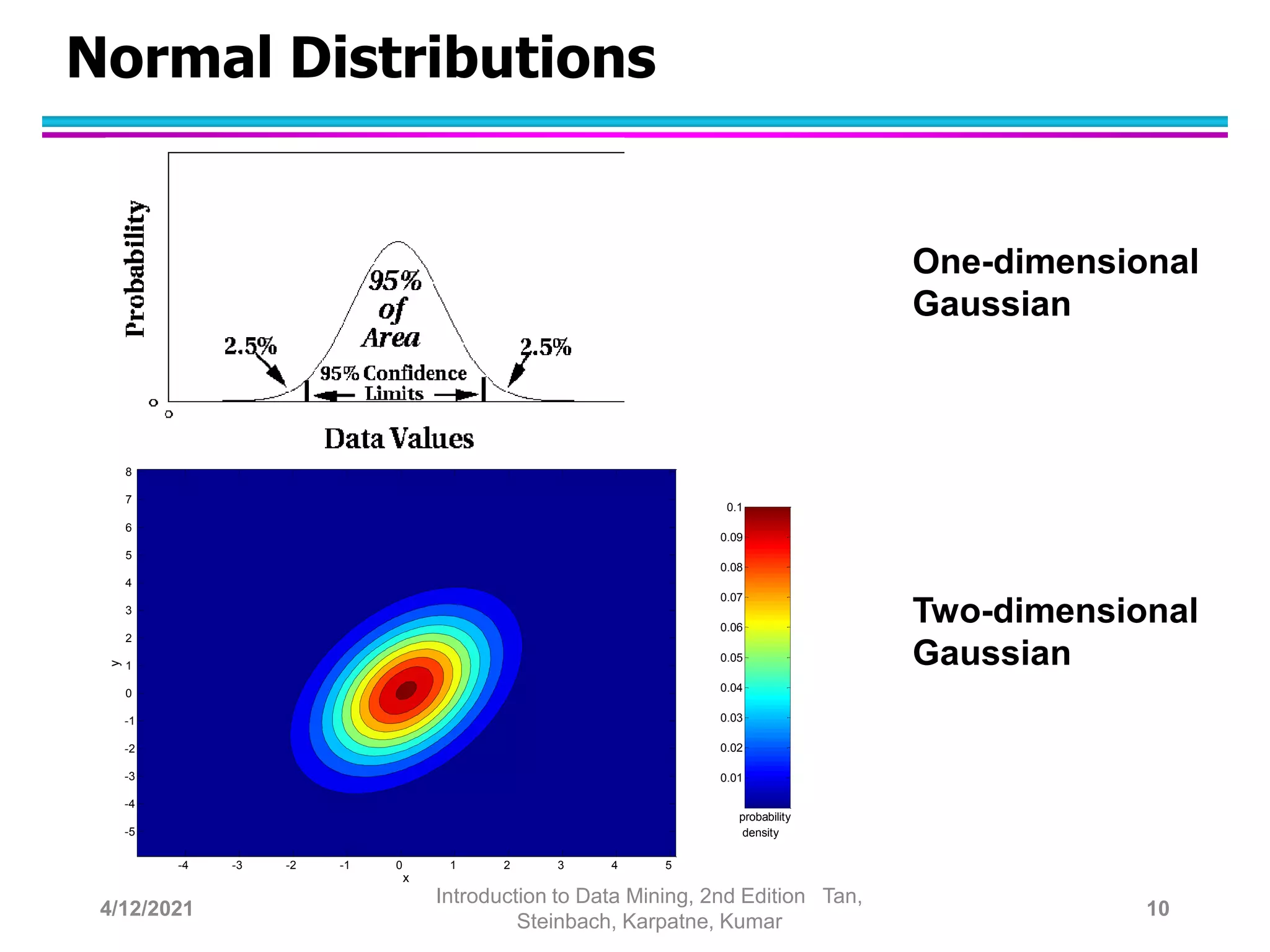
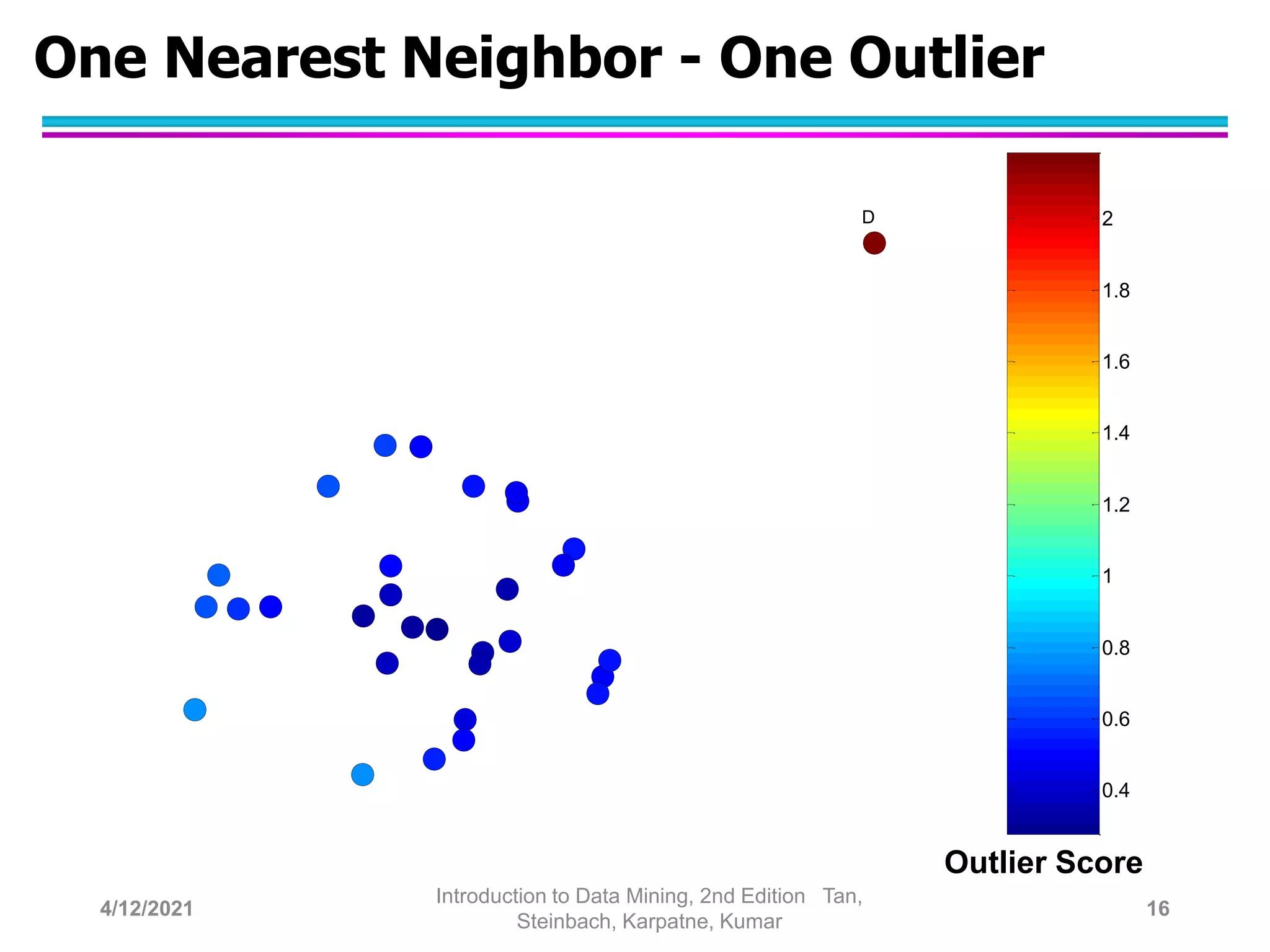
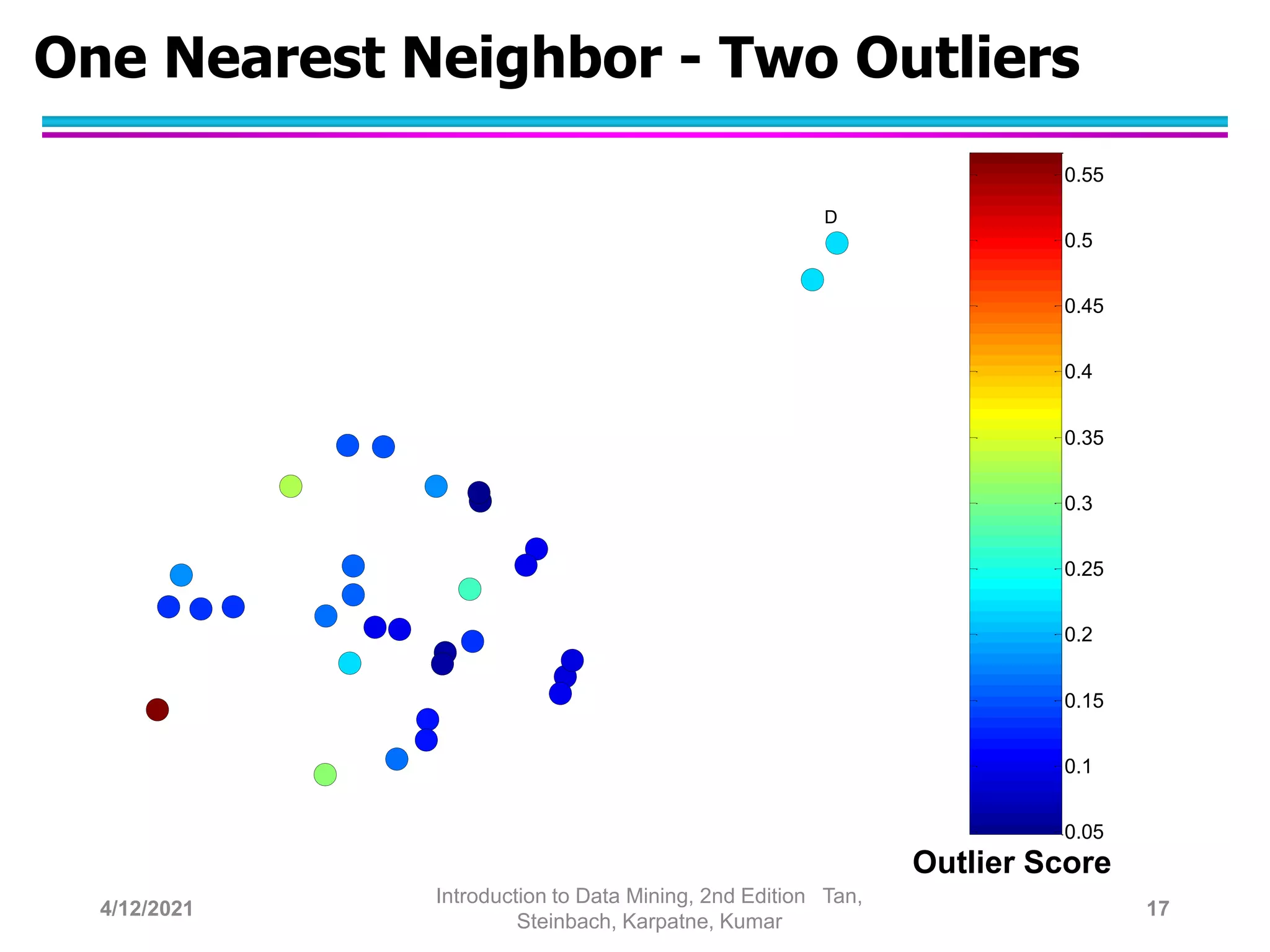
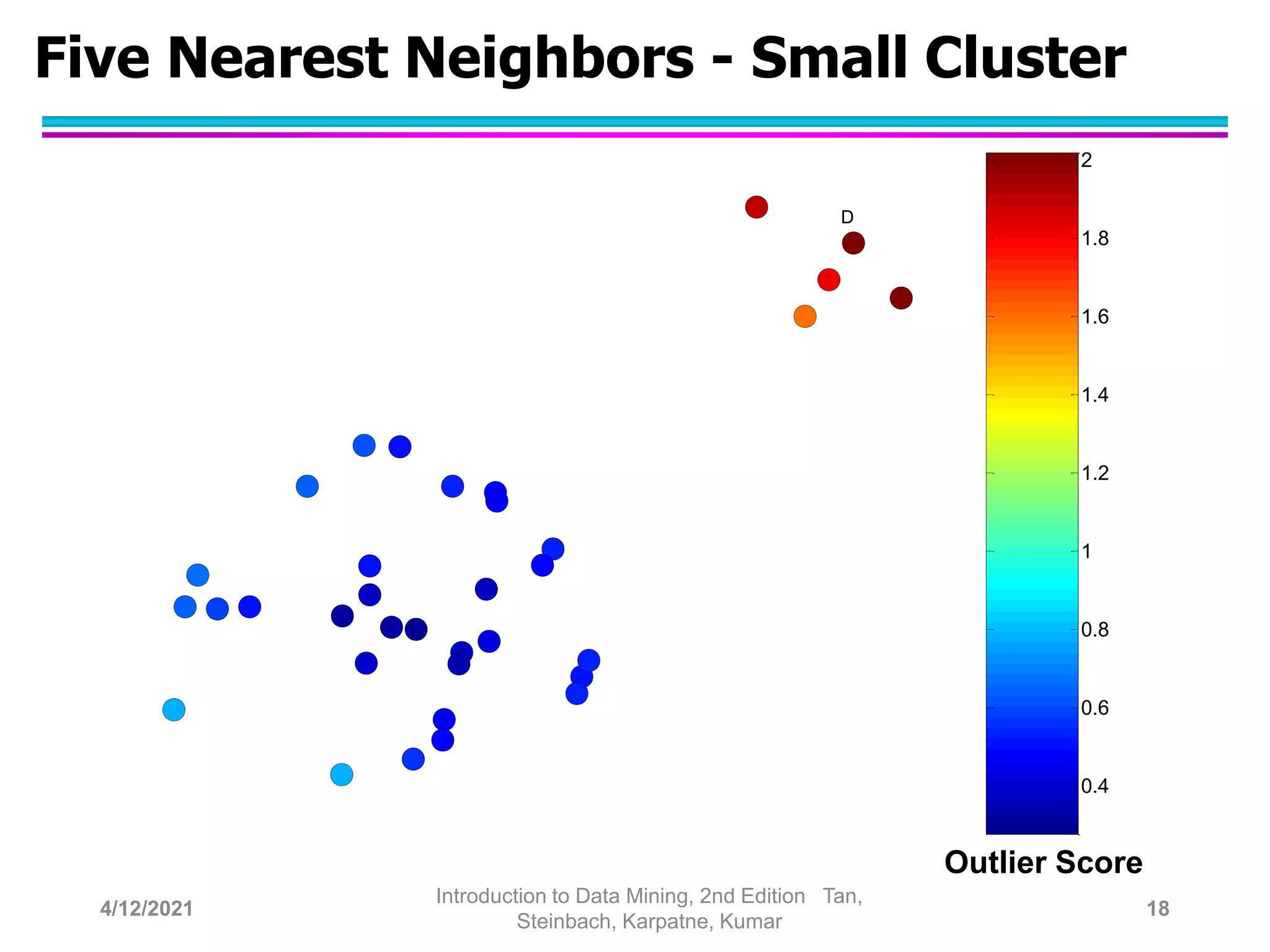
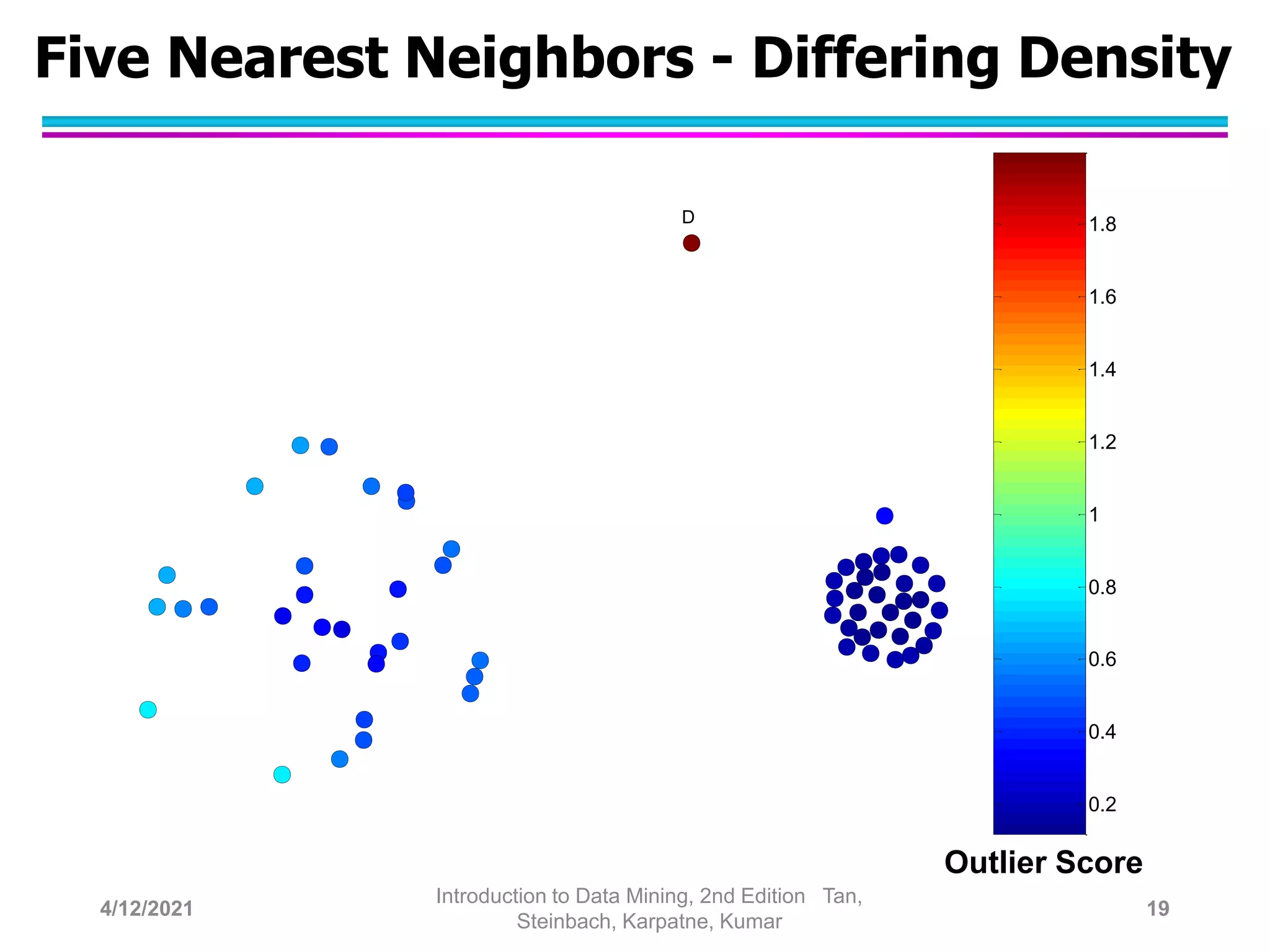
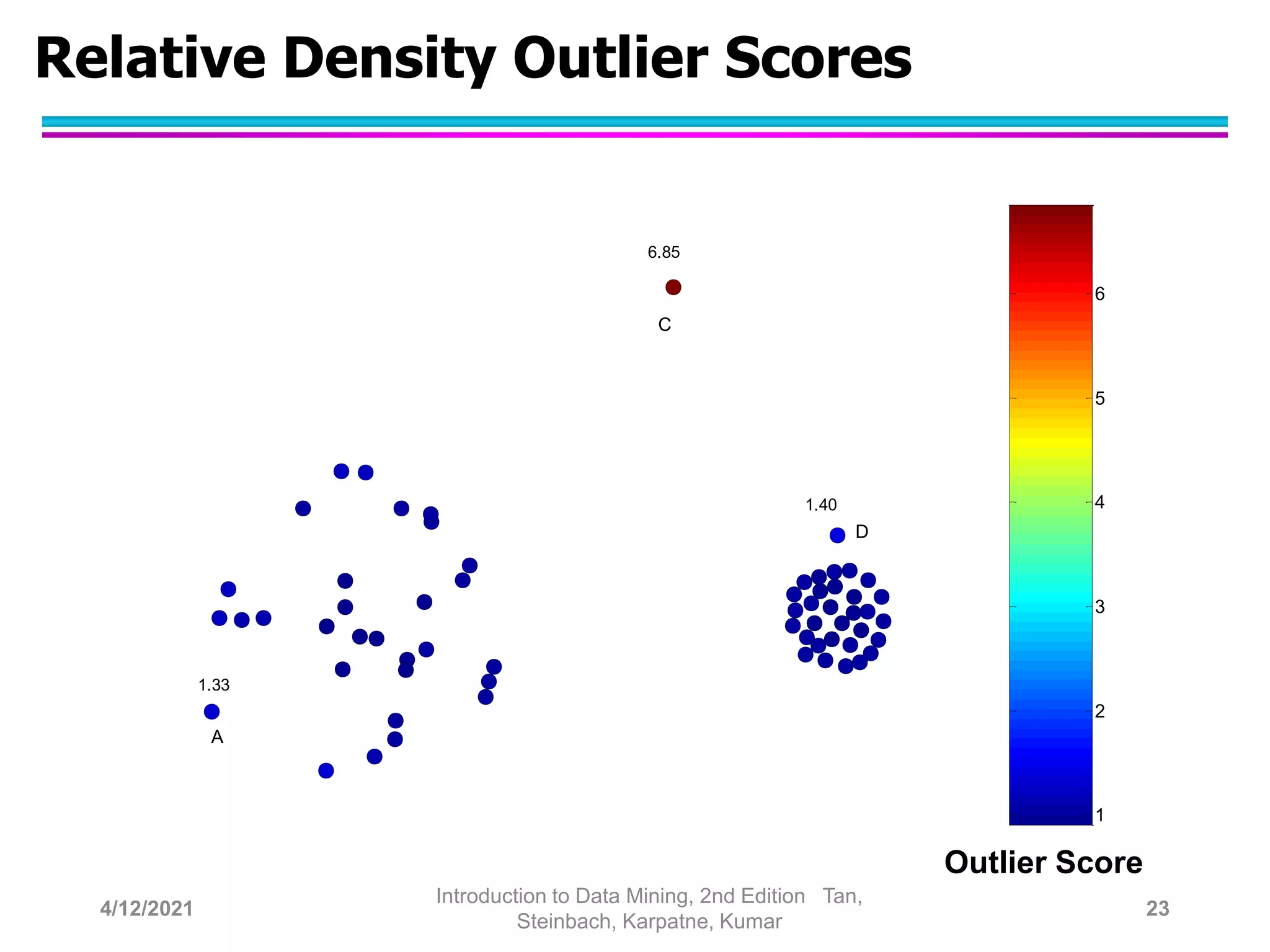
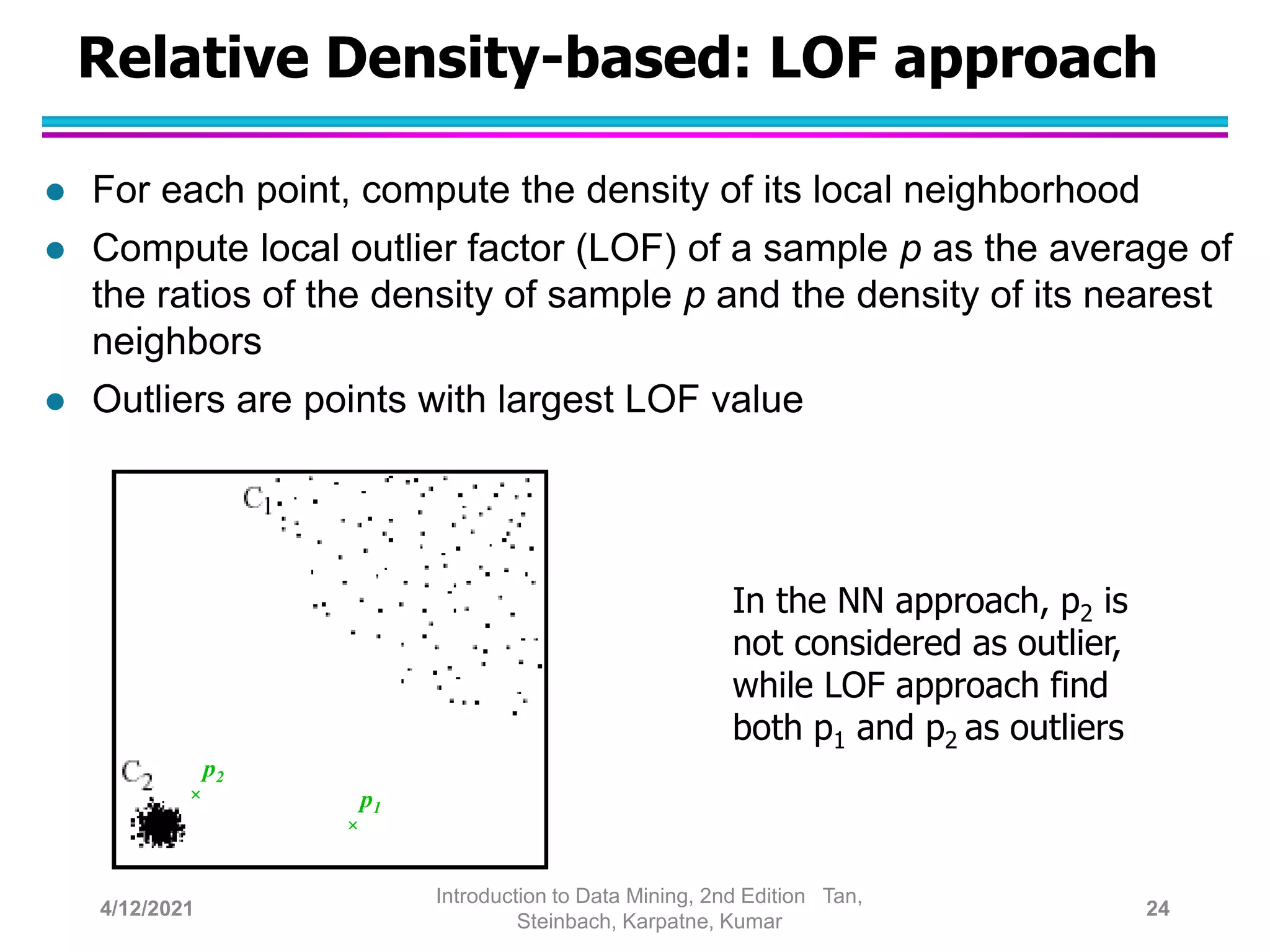
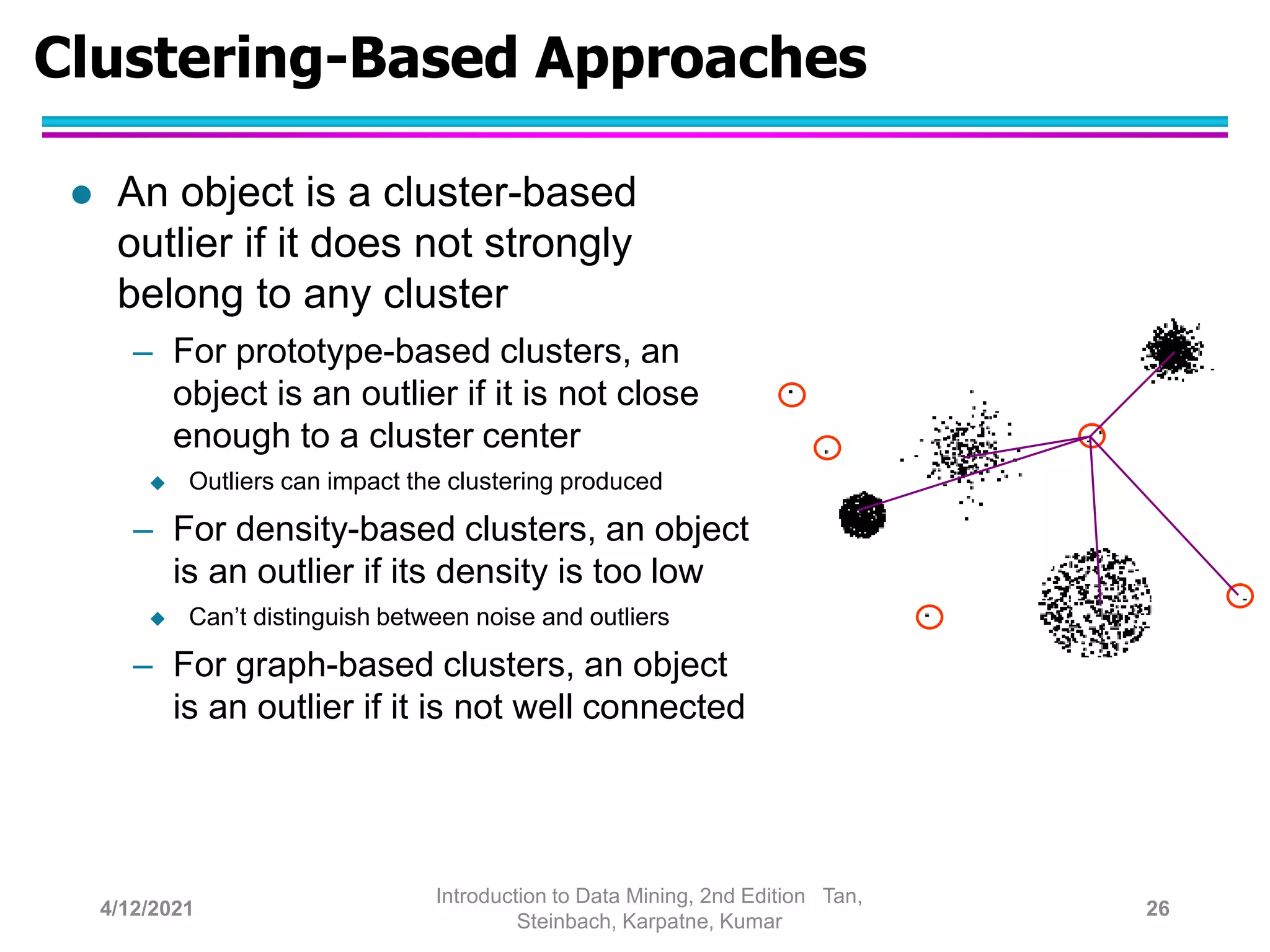
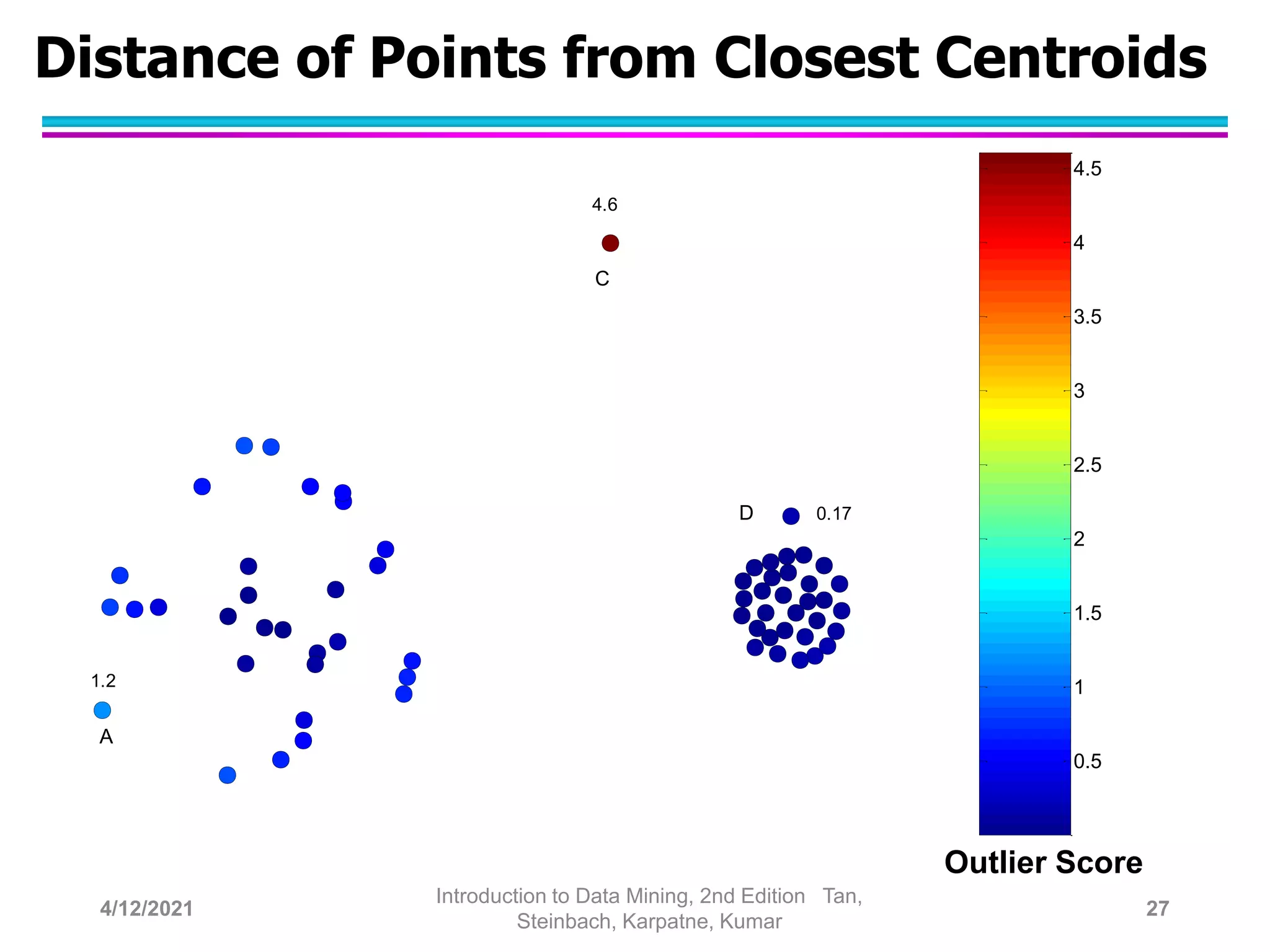
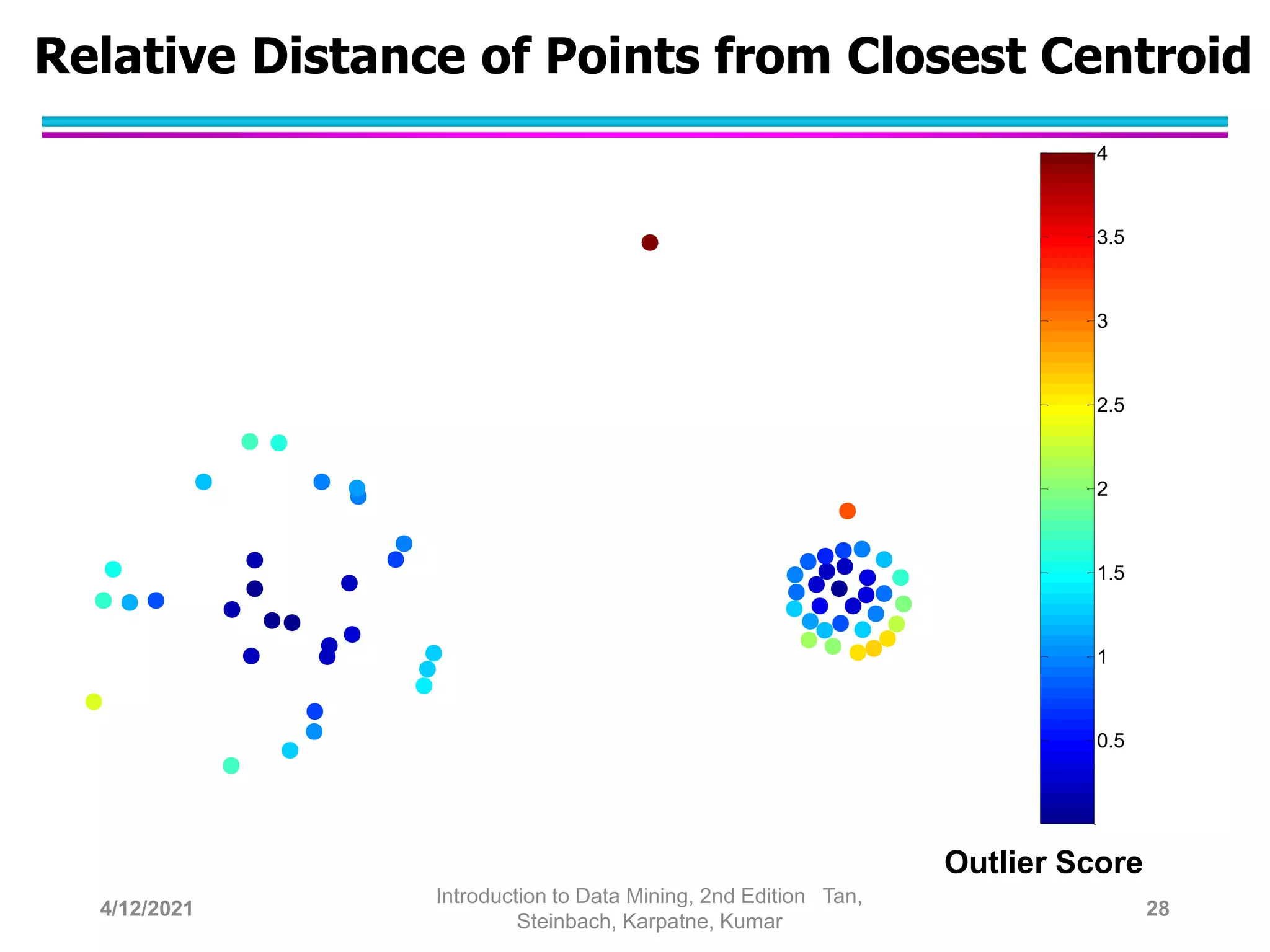
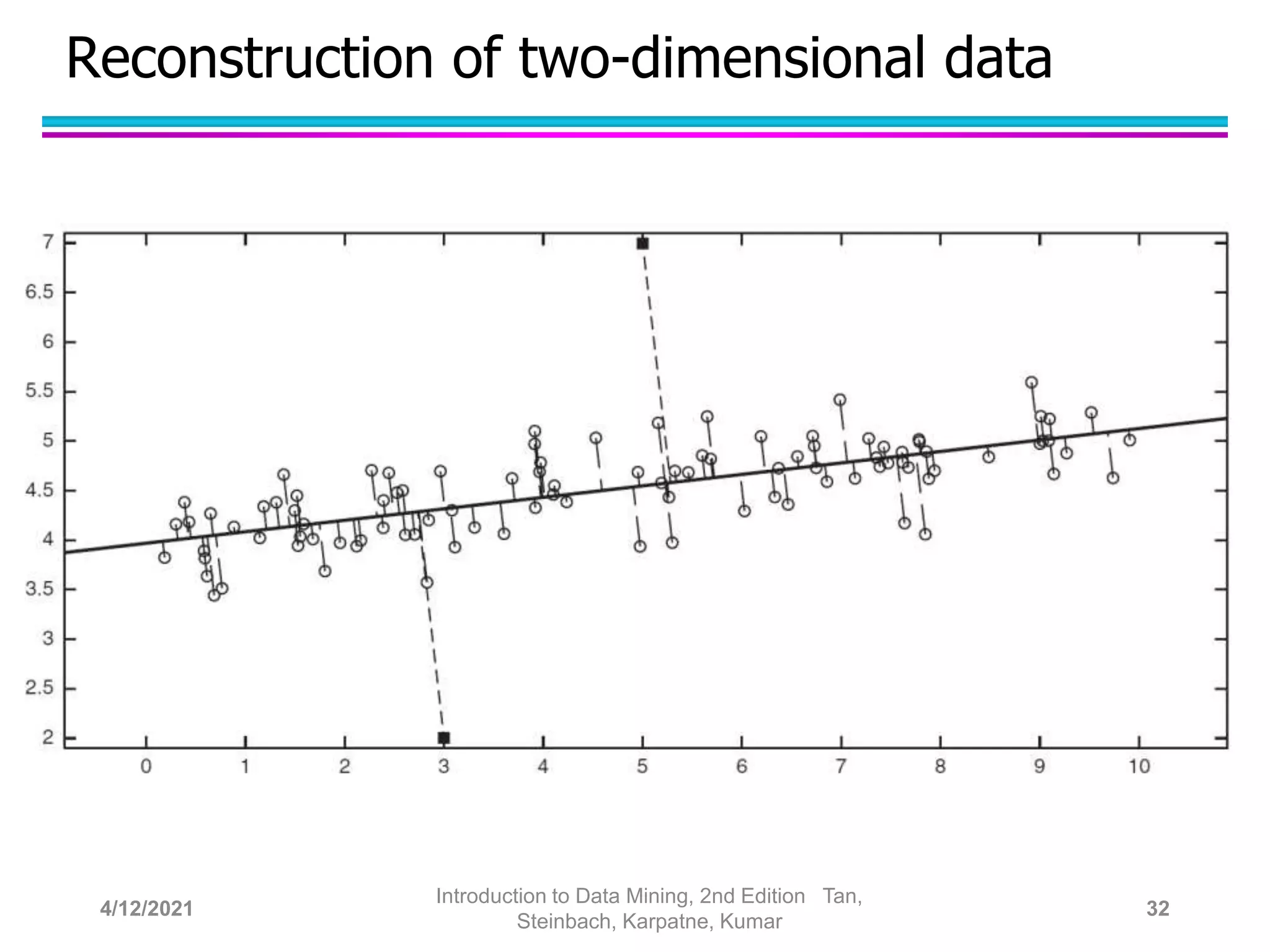
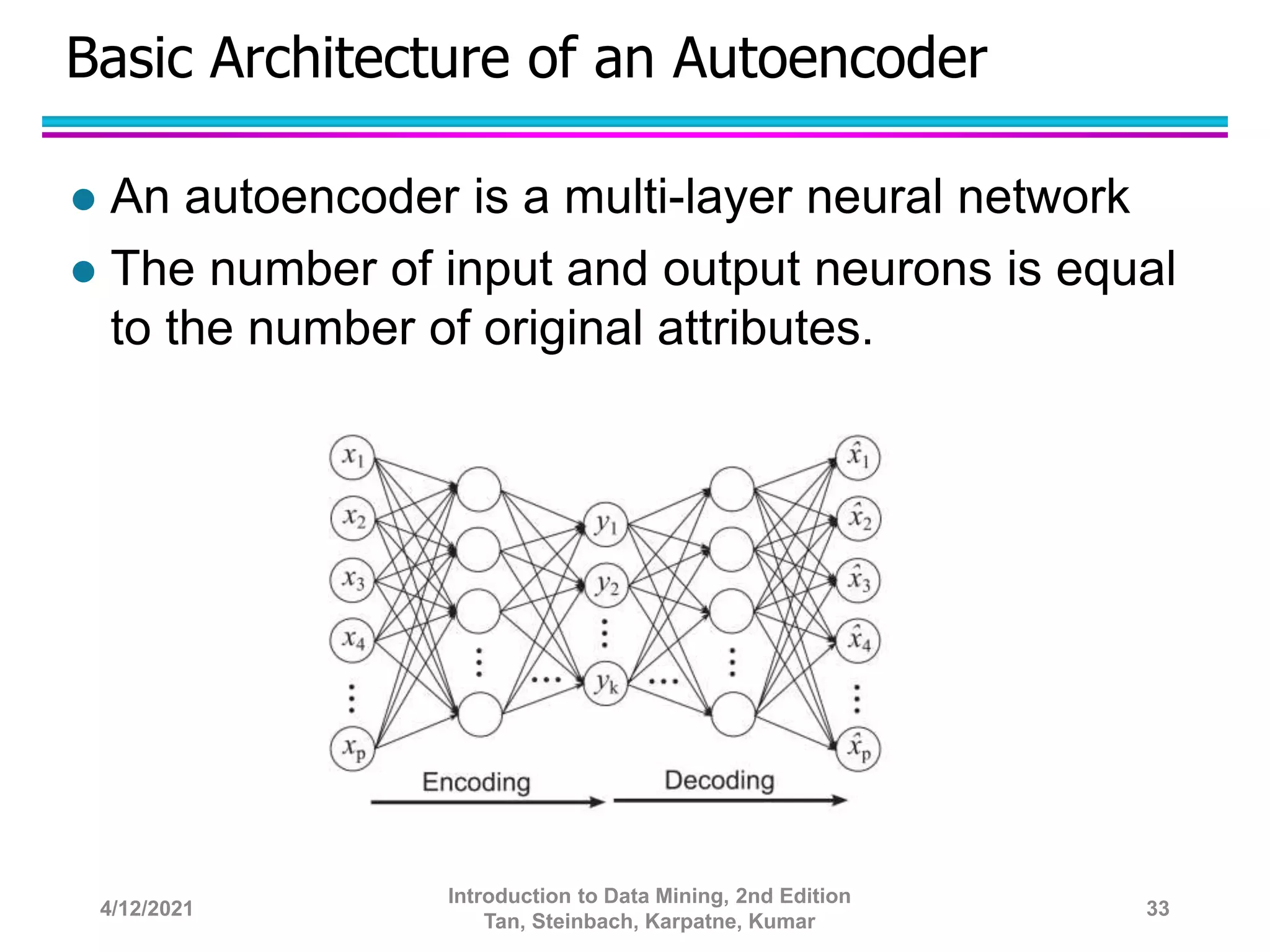
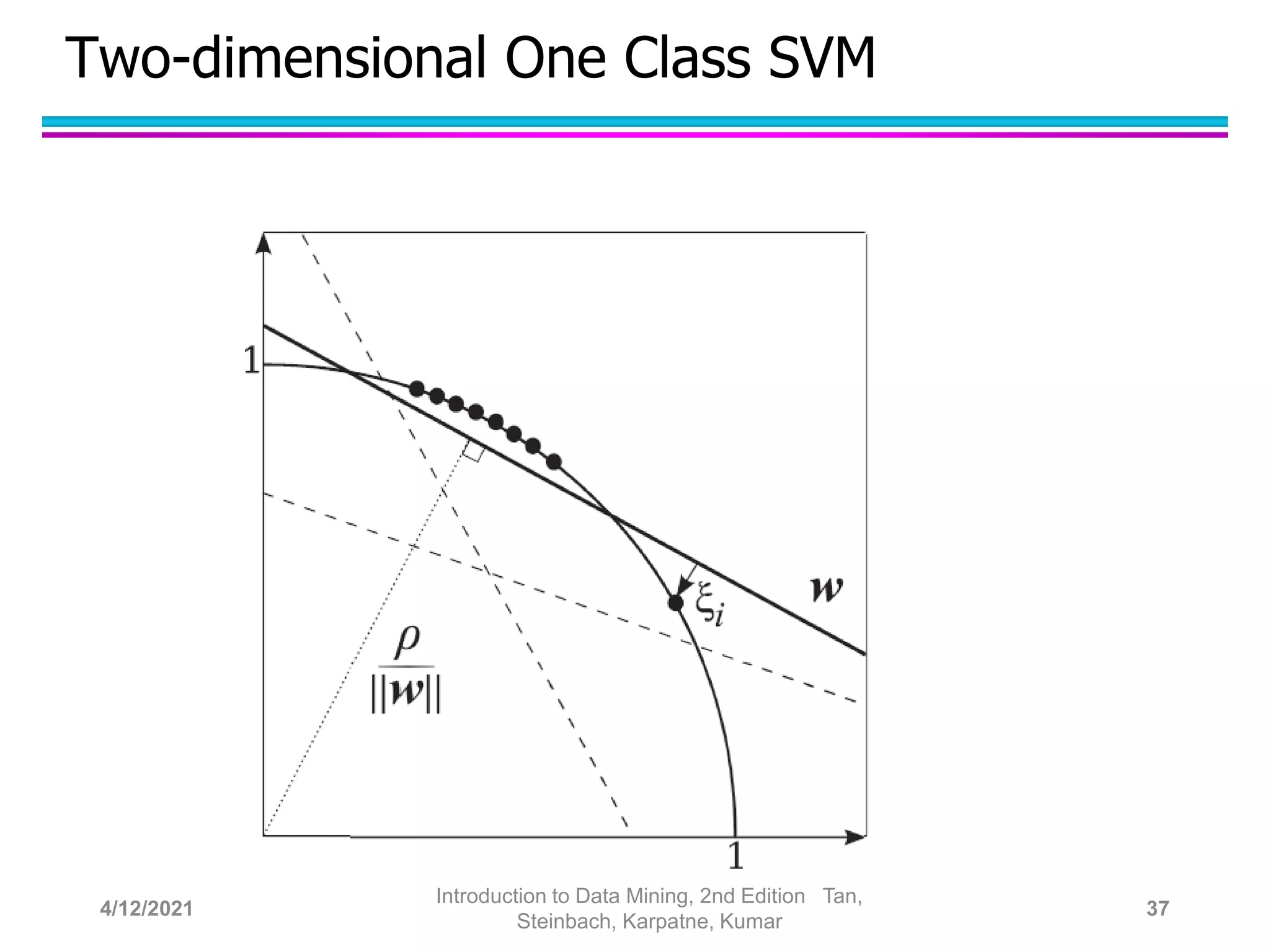
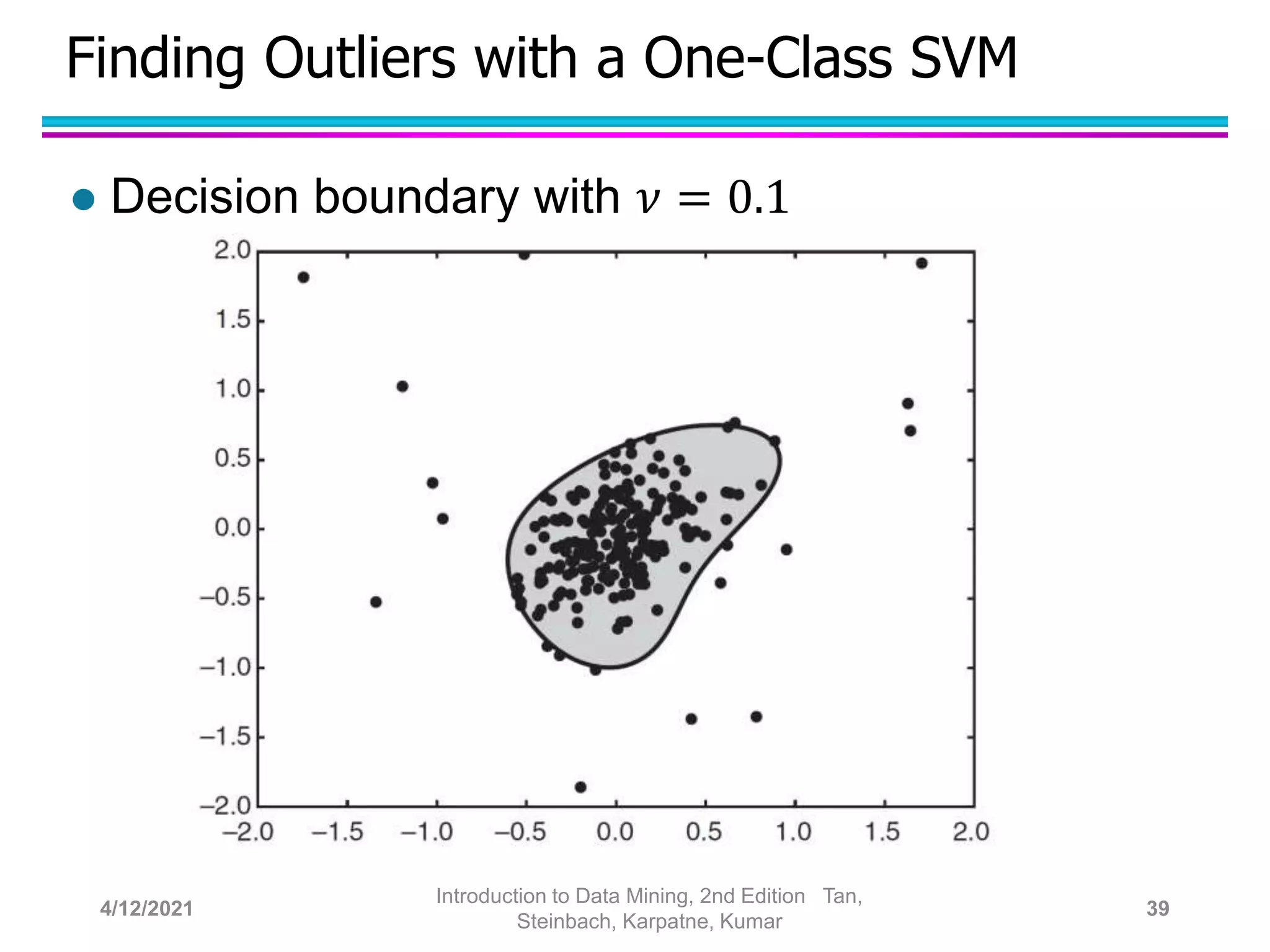
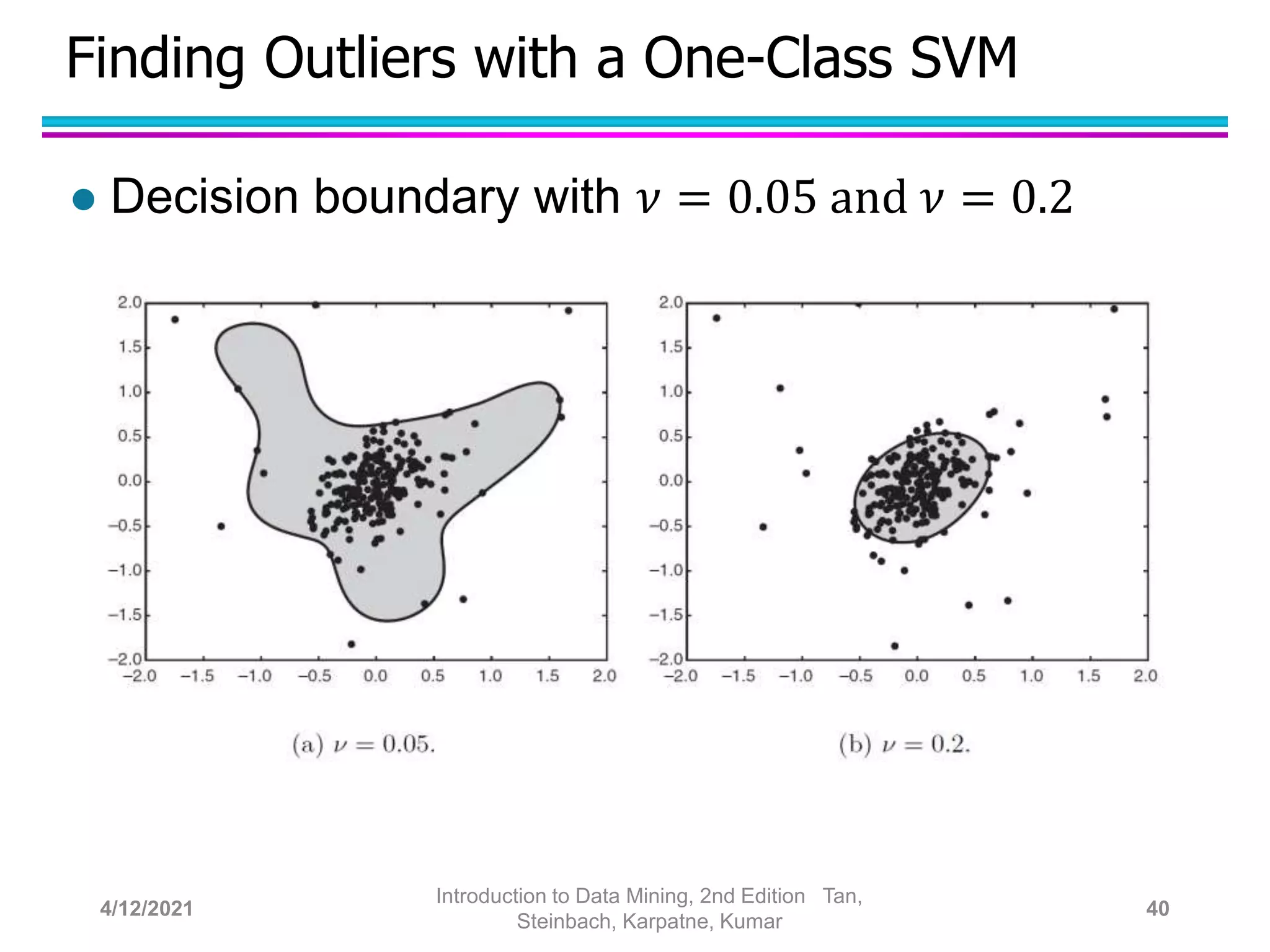
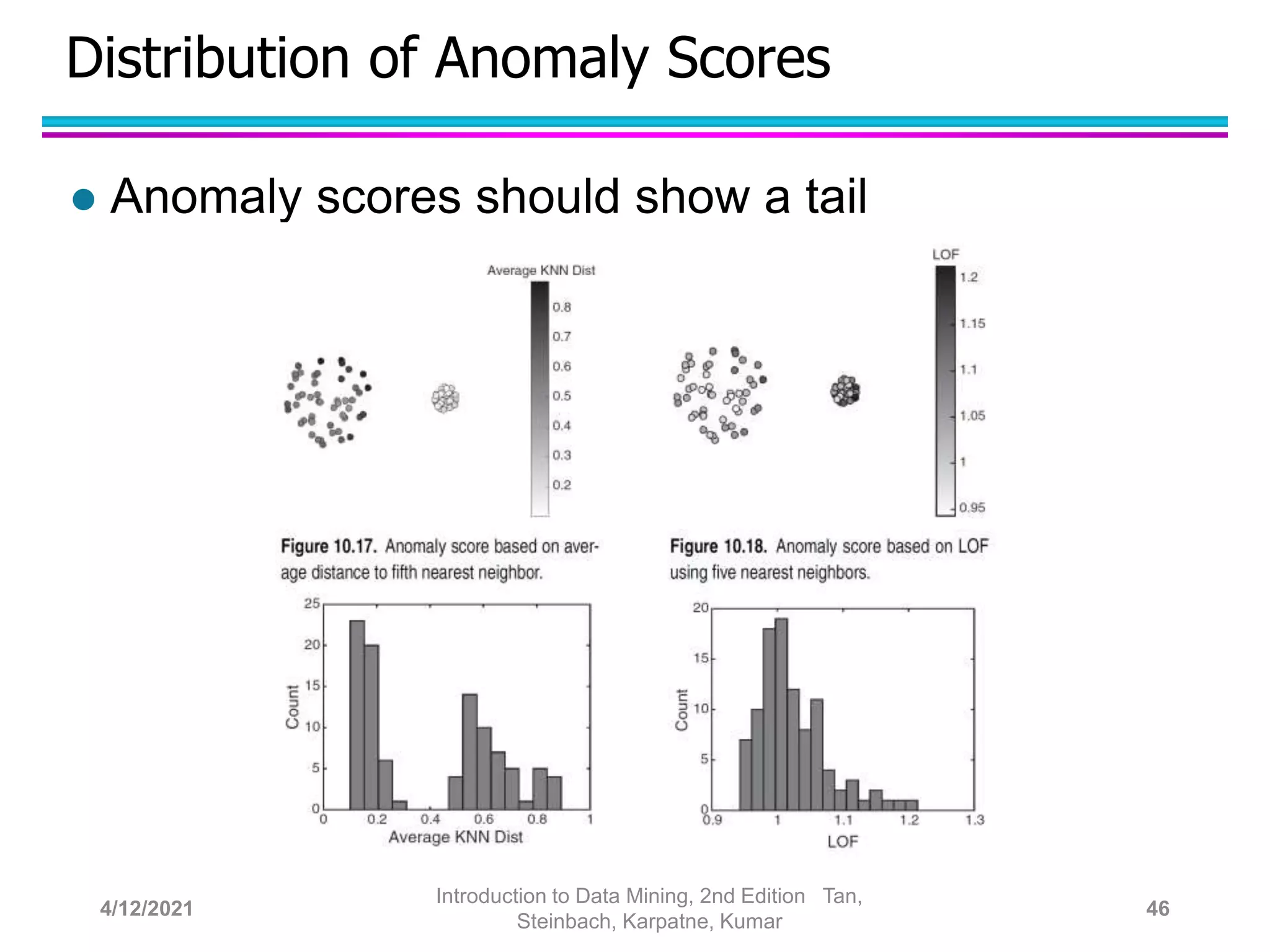
This document provides an overview of anomaly detection techniques. It defines anomalies as data points that are considerably different from most other points. Several causes of anomalies are discussed, including errors in data collection. Both model-based and model-free approaches to anomaly detection are described. Specific techniques covered include statistical approaches that assume a probability distribution for the data, distance-based approaches that measure distances to nearest neighbors, density-based approaches that measure local densities, and clustering-based approaches that identify outliers as points far from cluster centers. Strengths and weaknesses of each type of technique are also summarized.