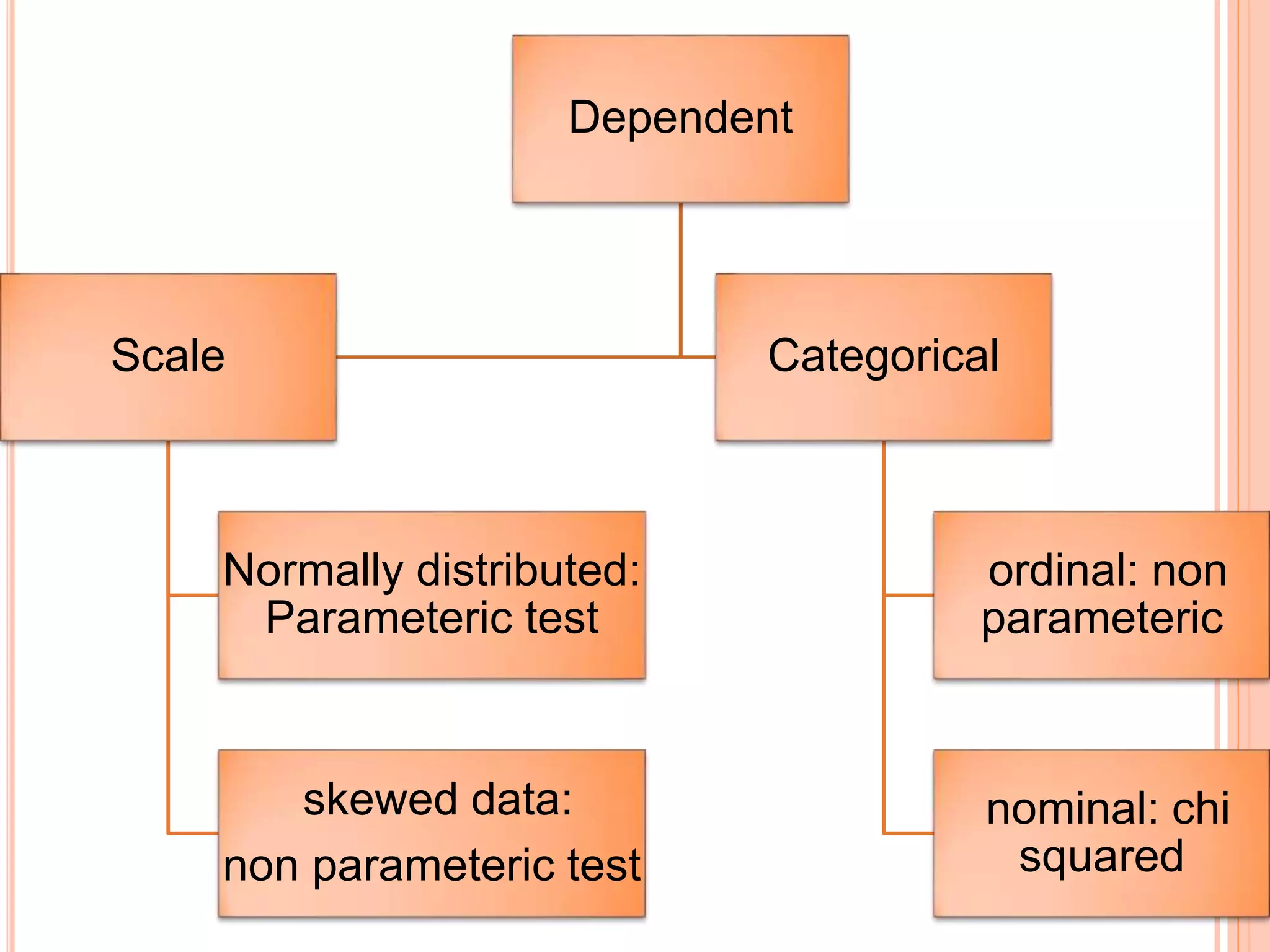
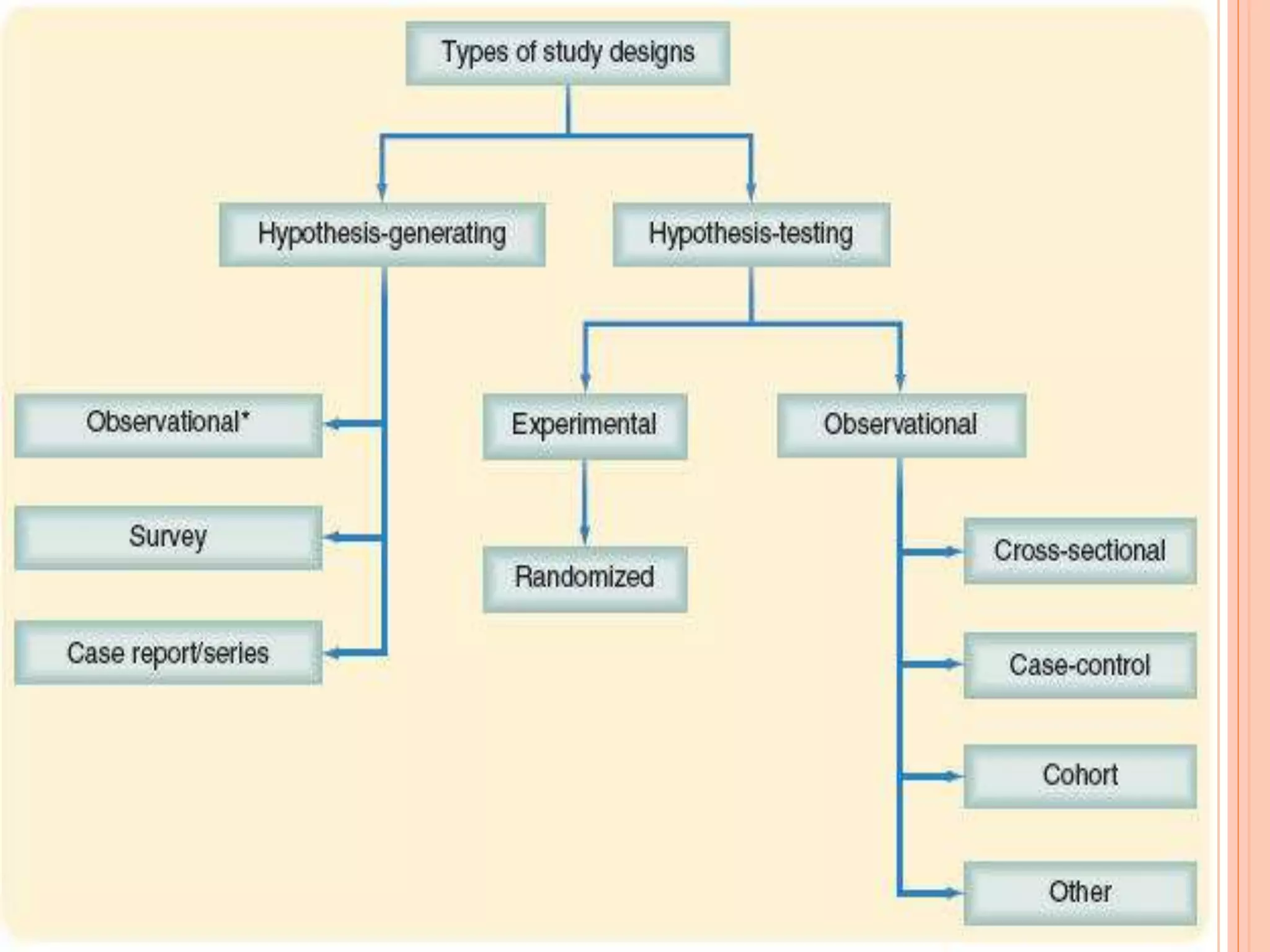
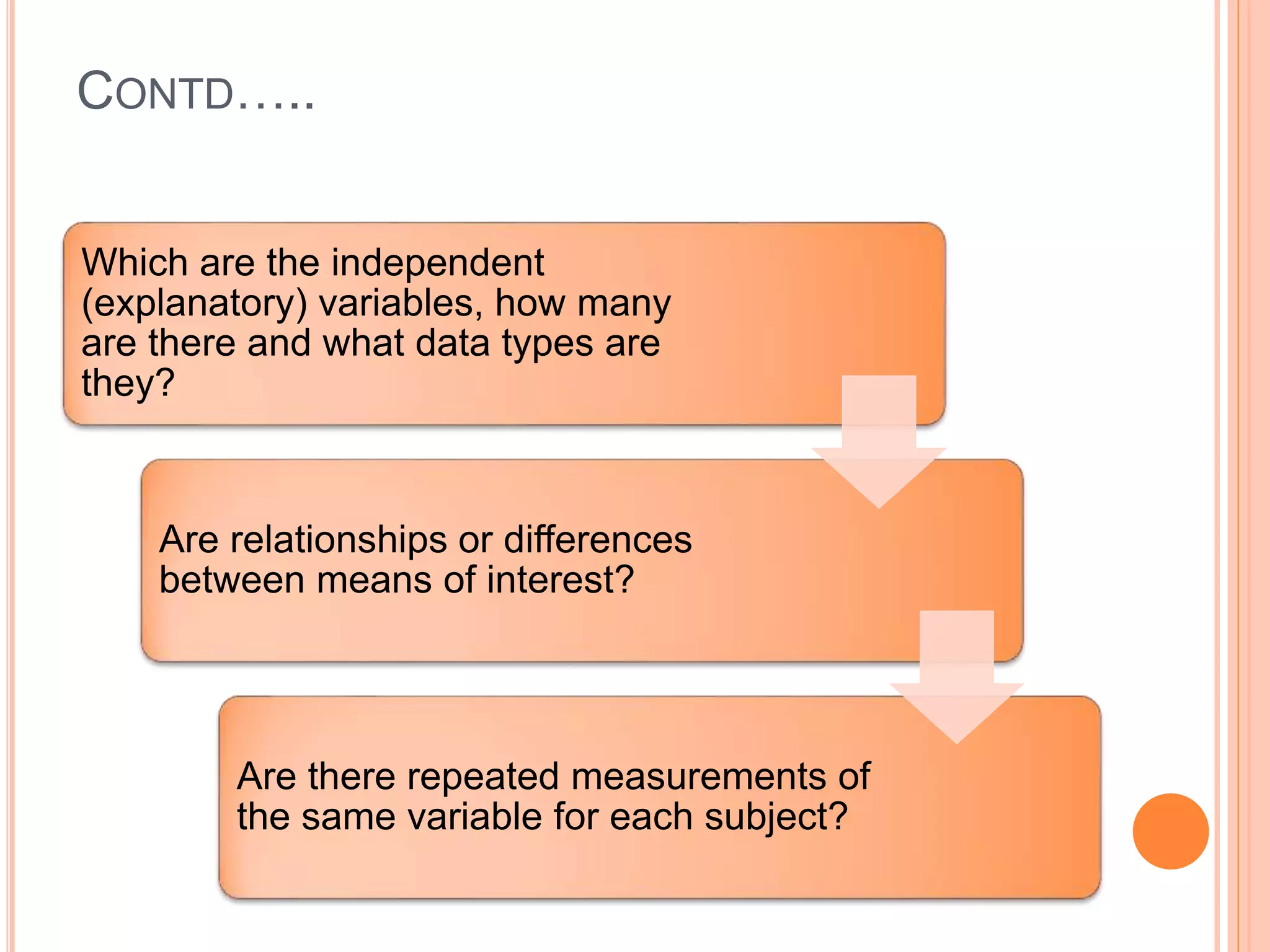
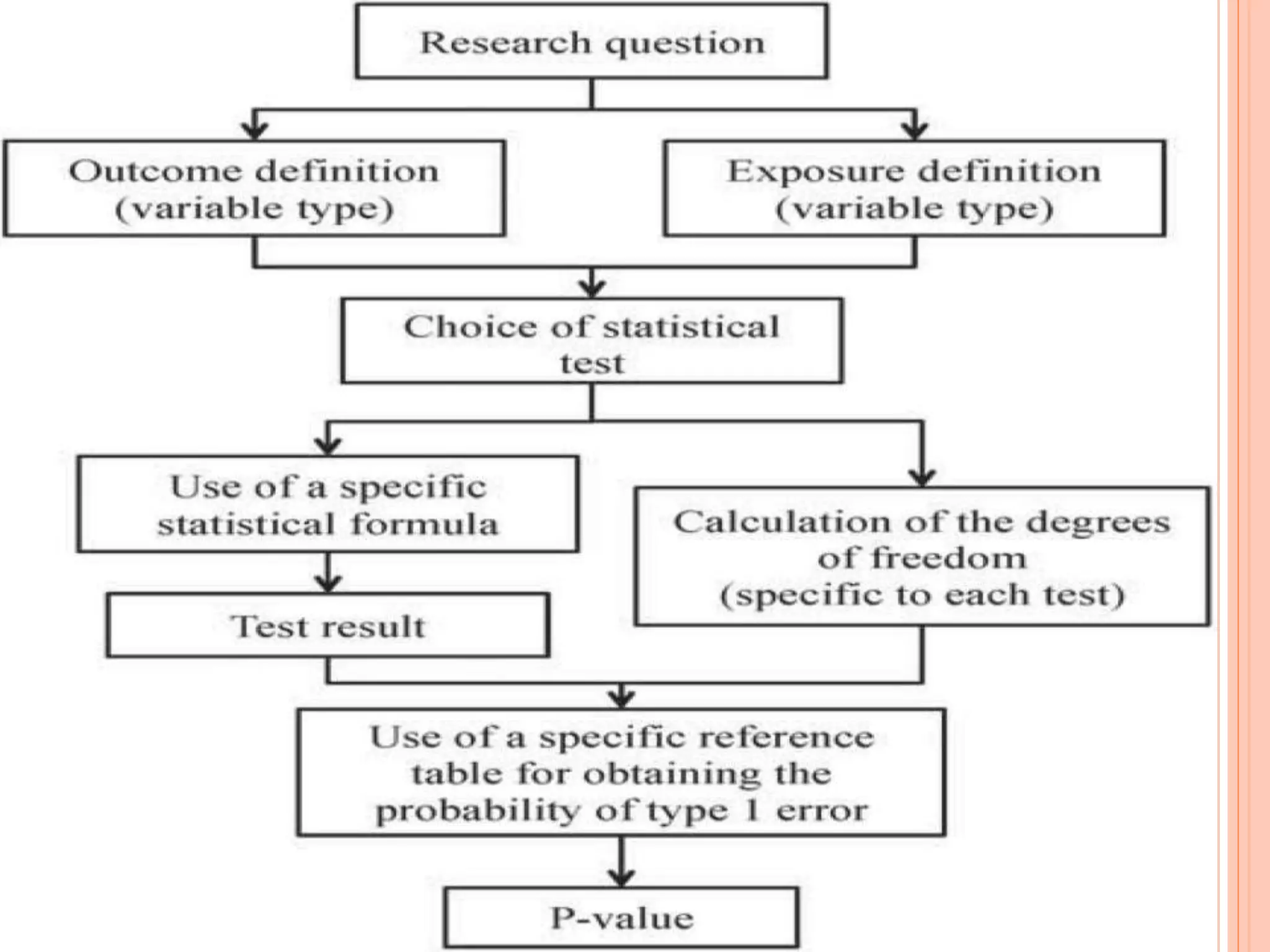
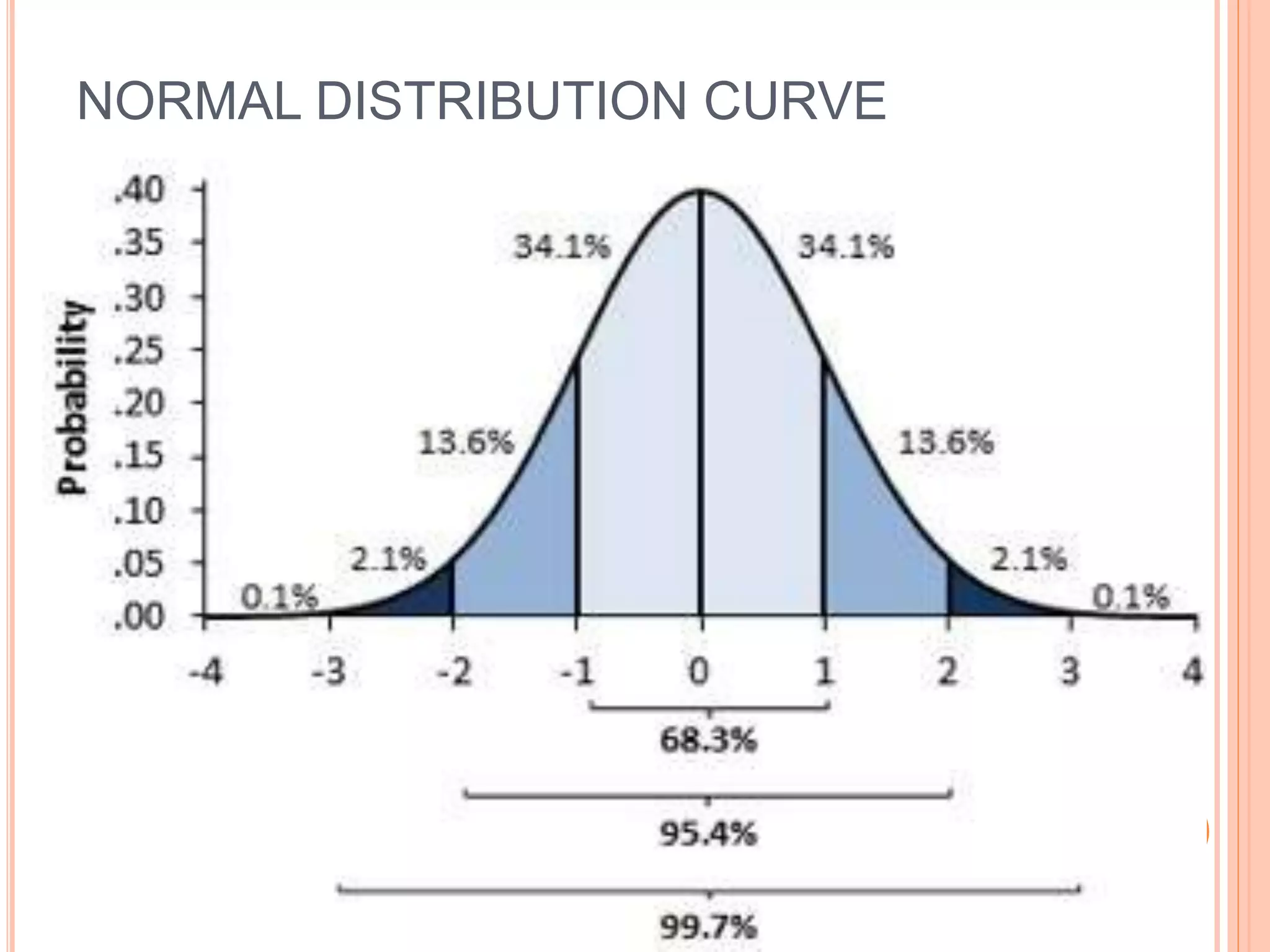
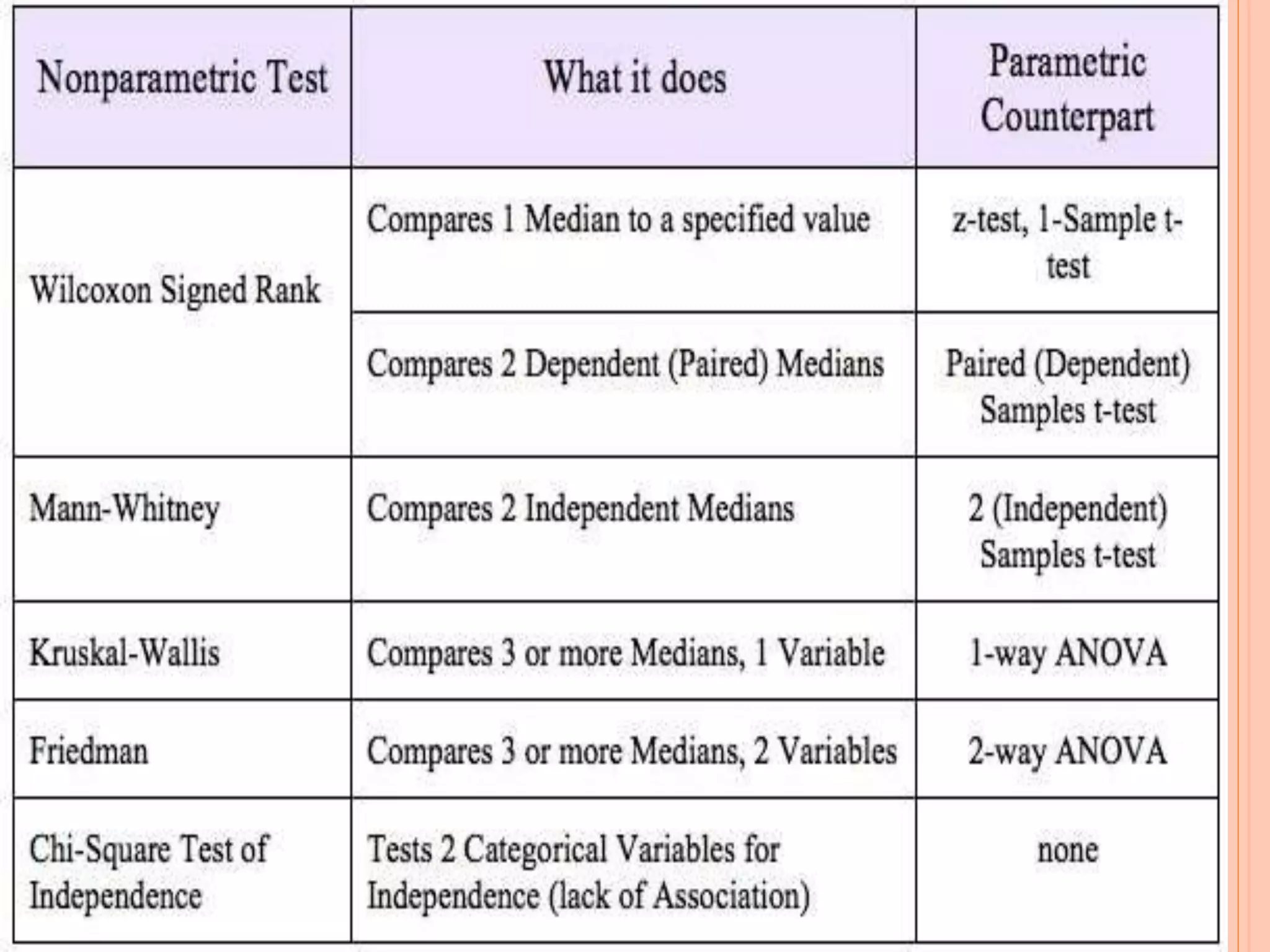
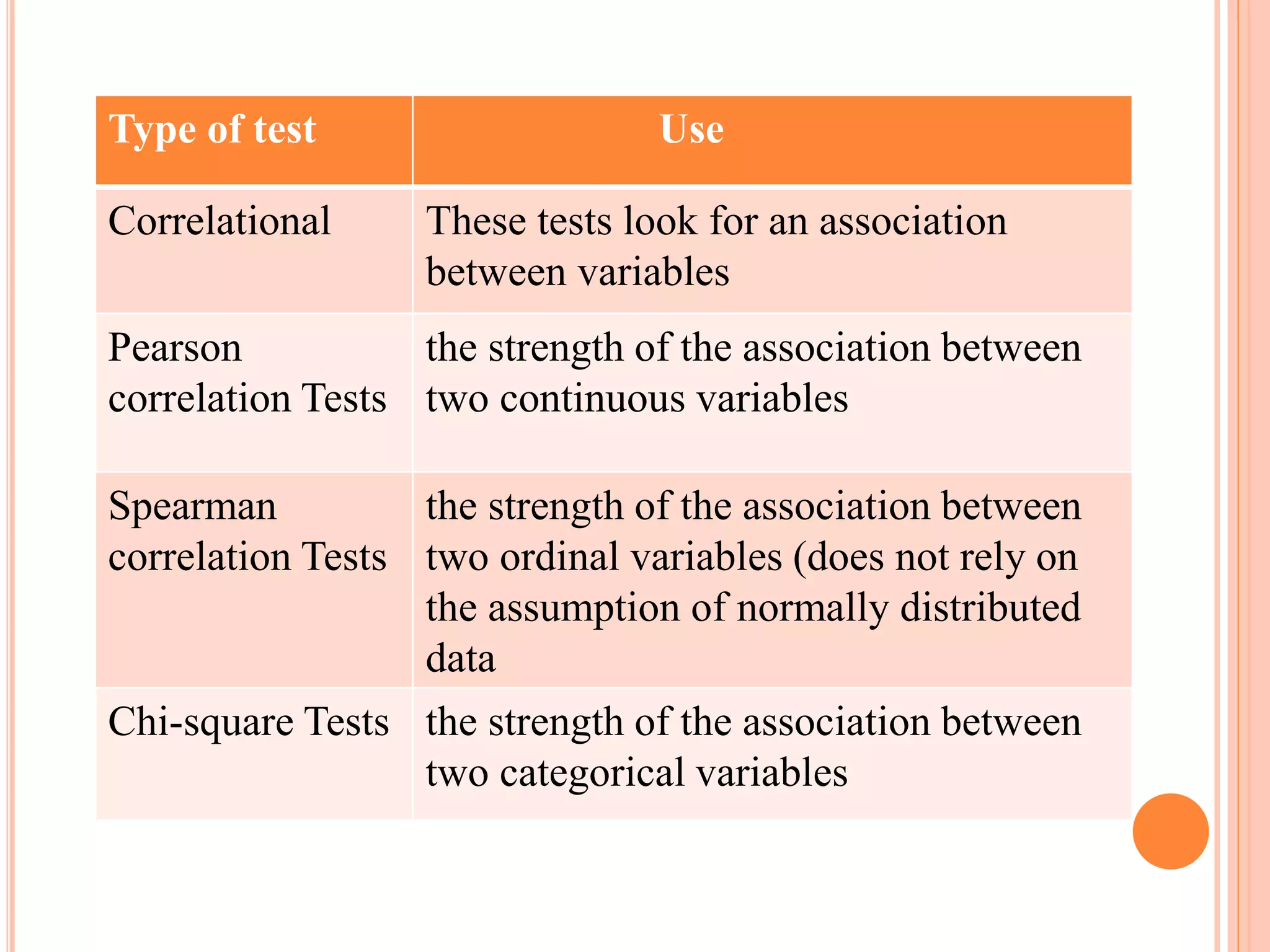
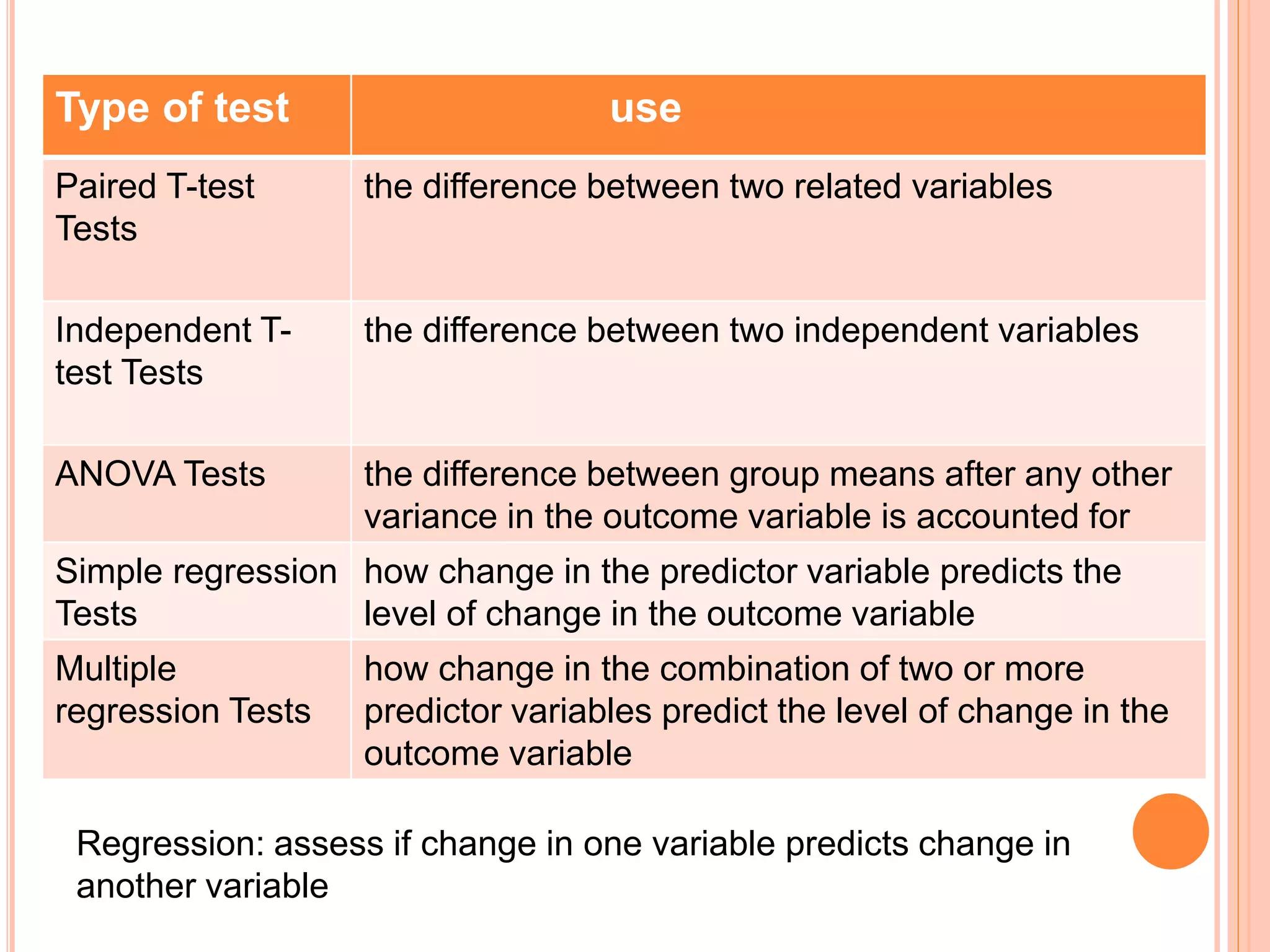
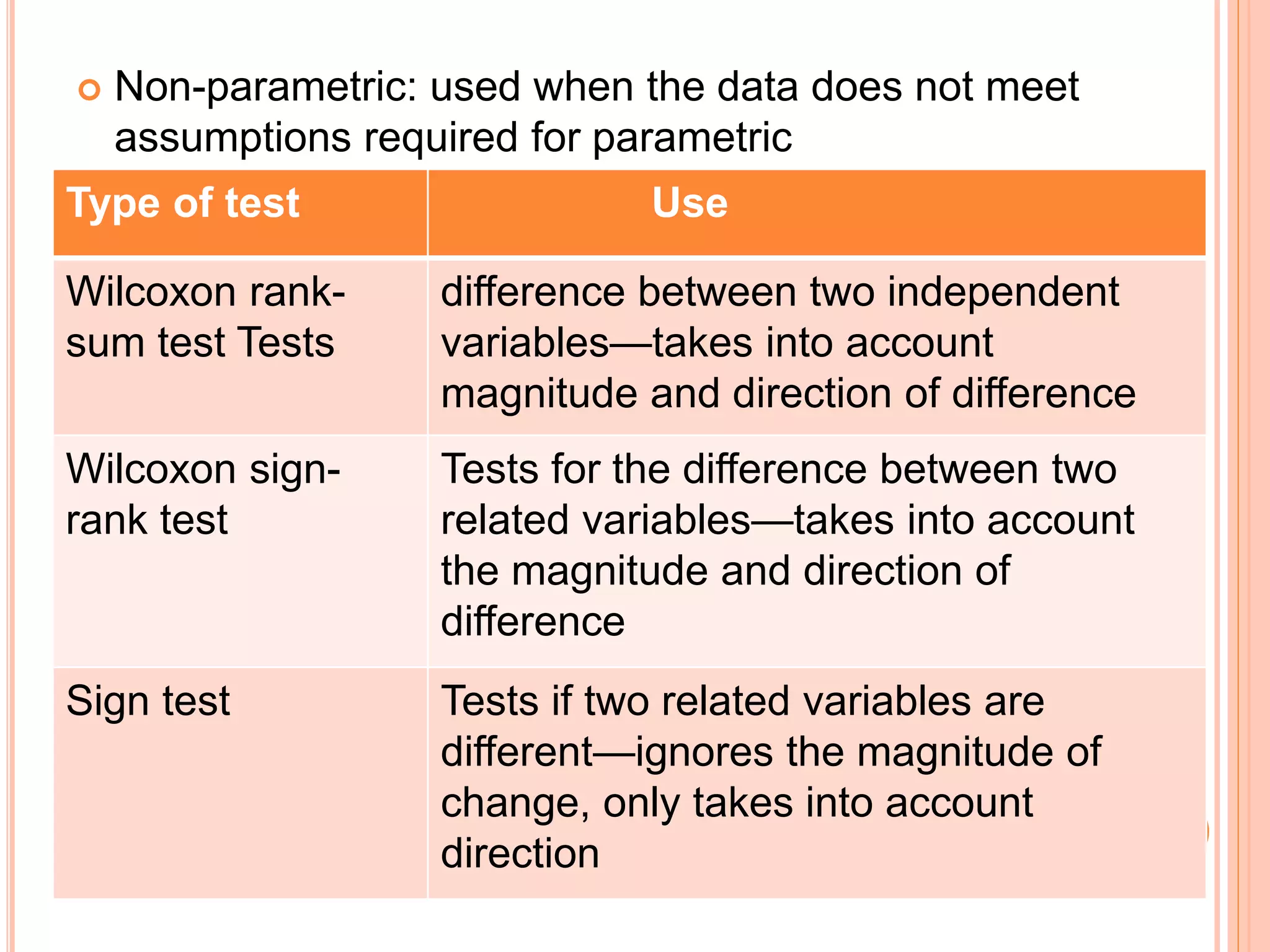
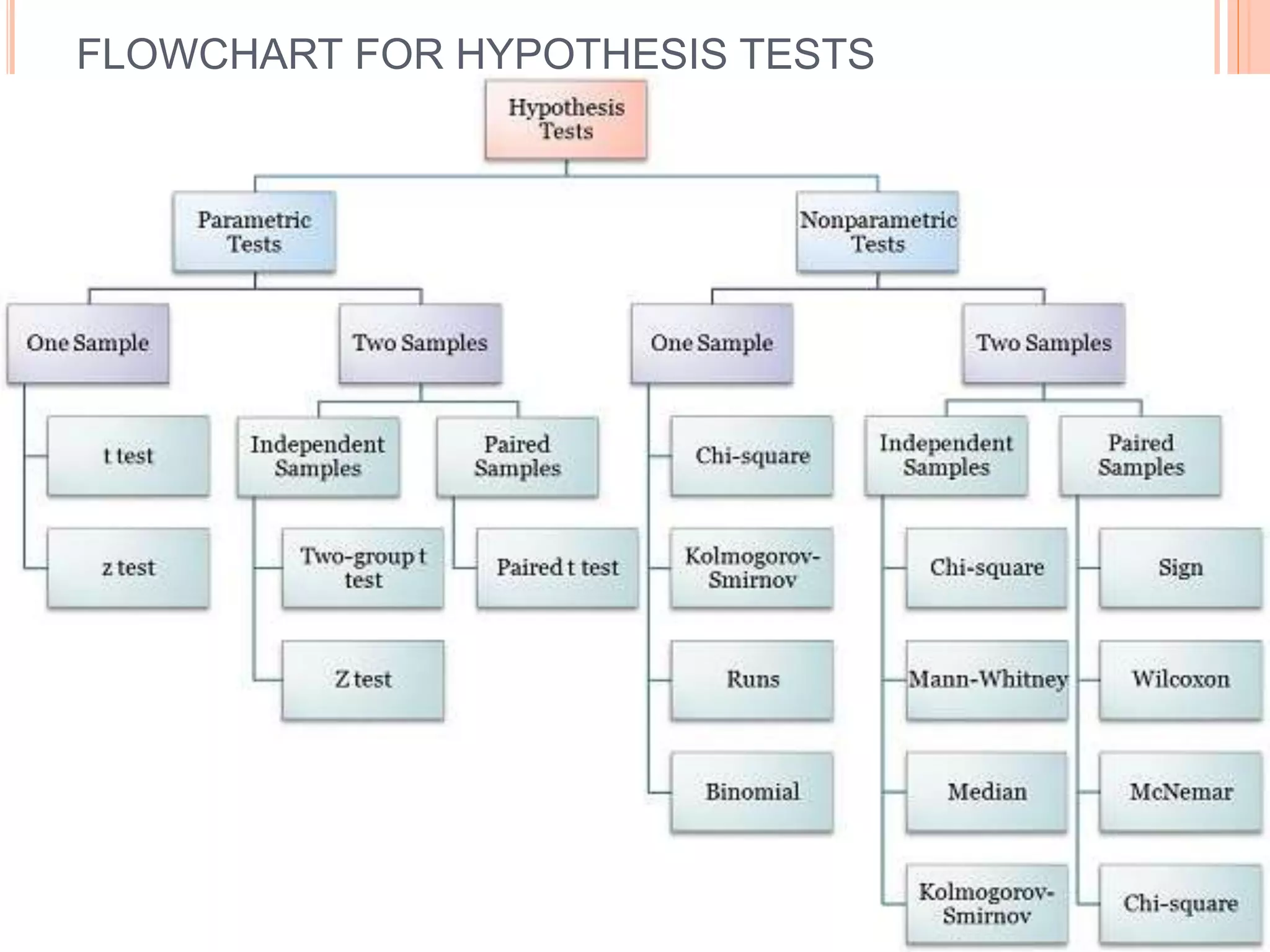
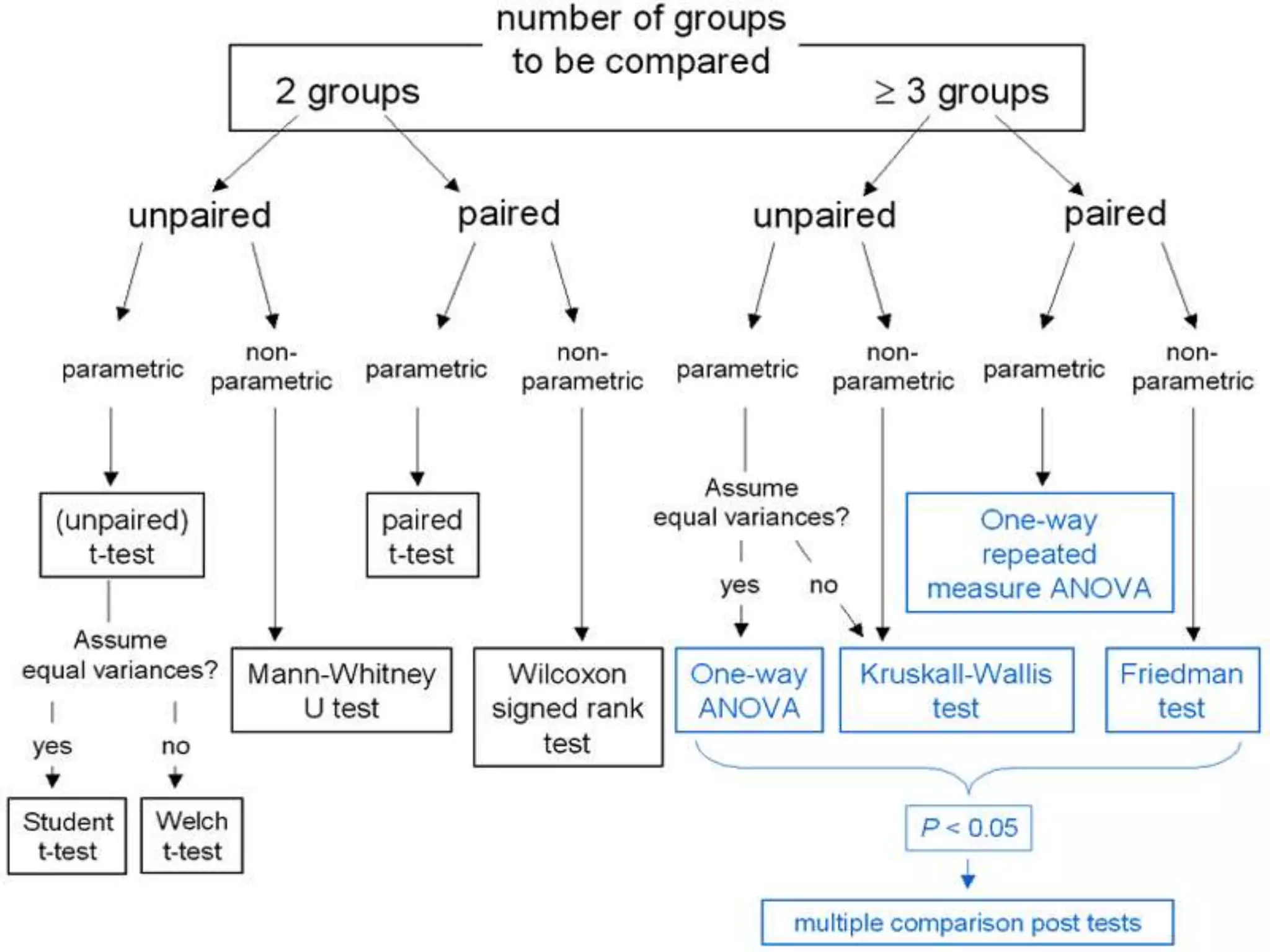
This document provides an overview of different statistical tests used in epidemiological studies and their applications. It discusses topics such as data types (quantitative, categorical), variables, statistics, null and alternative hypotheses, errors in significance testing, and choices between parametric and nonparametric tests. The key information provided includes classifications of variable types, definitions of common statistics, explanations of hypotheses testing and p-values, and guidance on selecting appropriate tests based on the scale and distribution of the data.