Download as PDF, PPTX



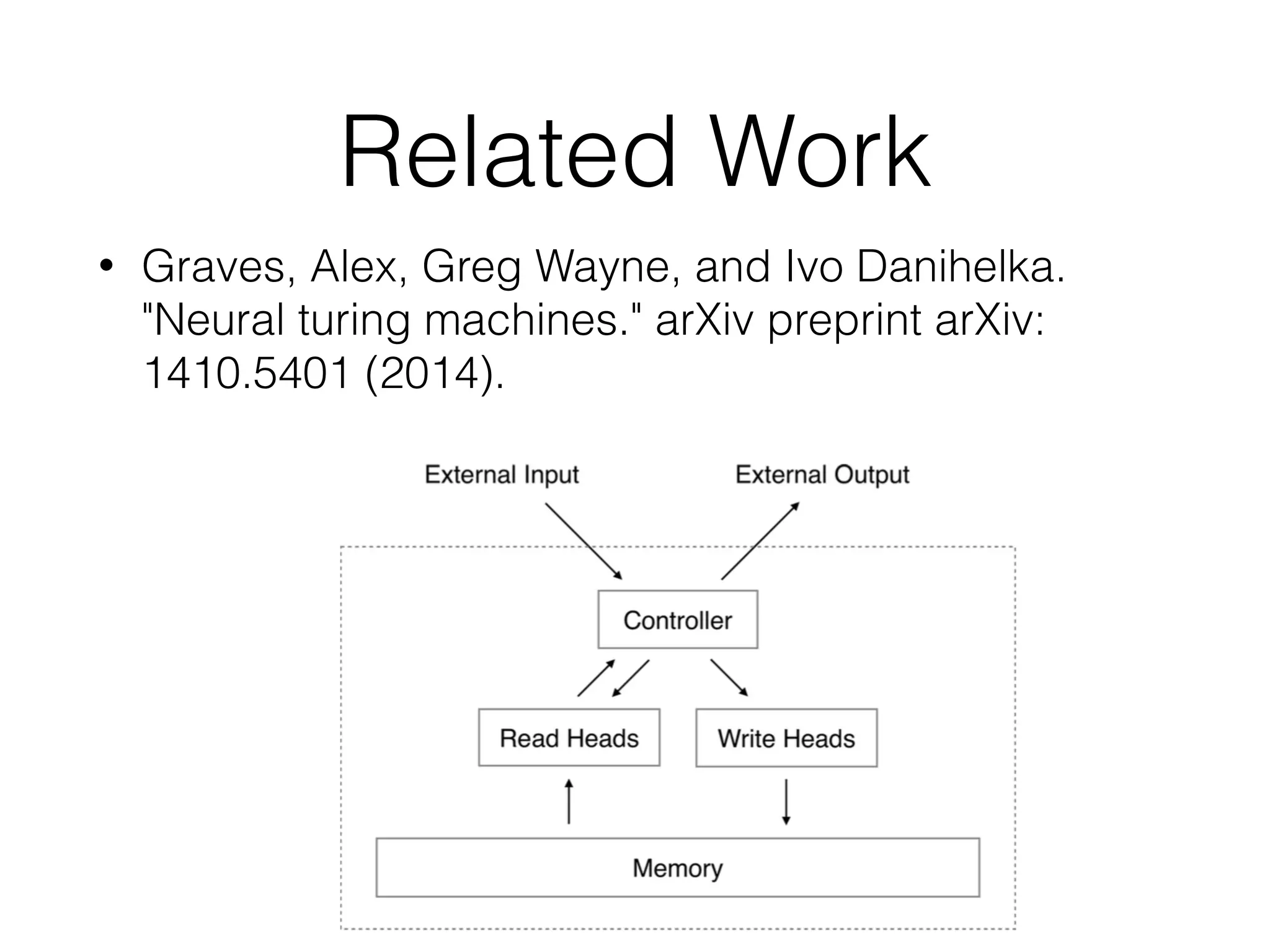
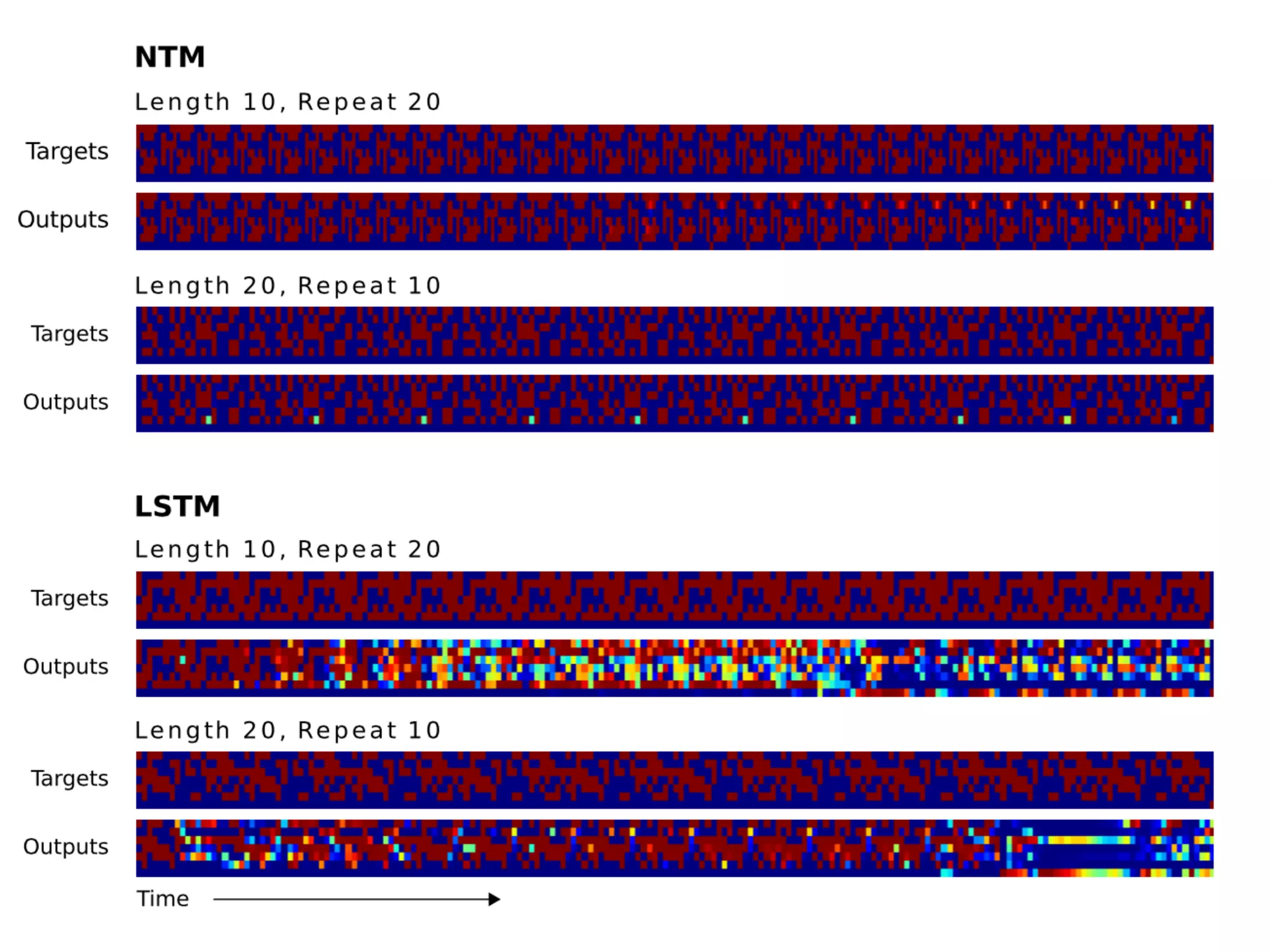


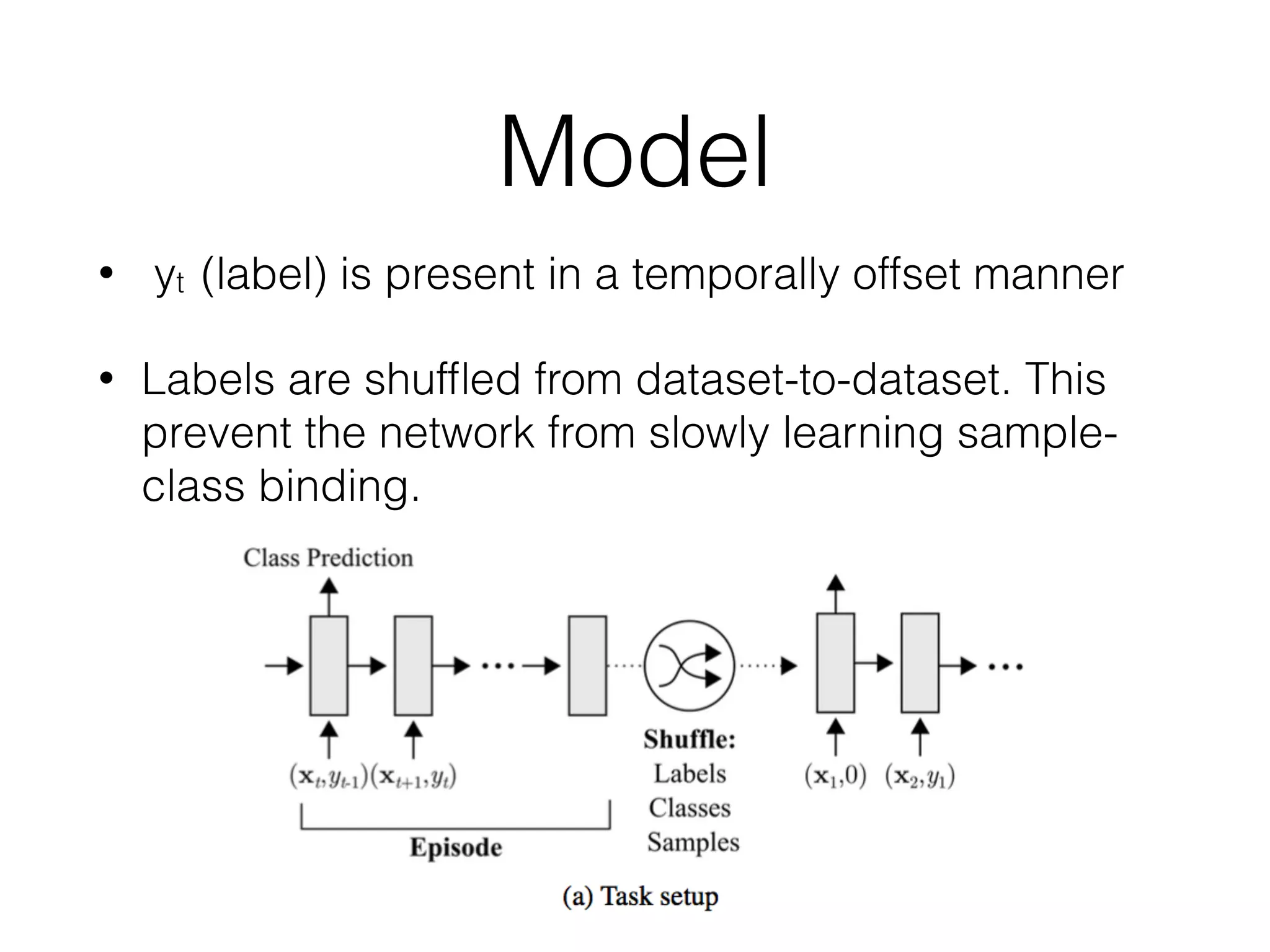
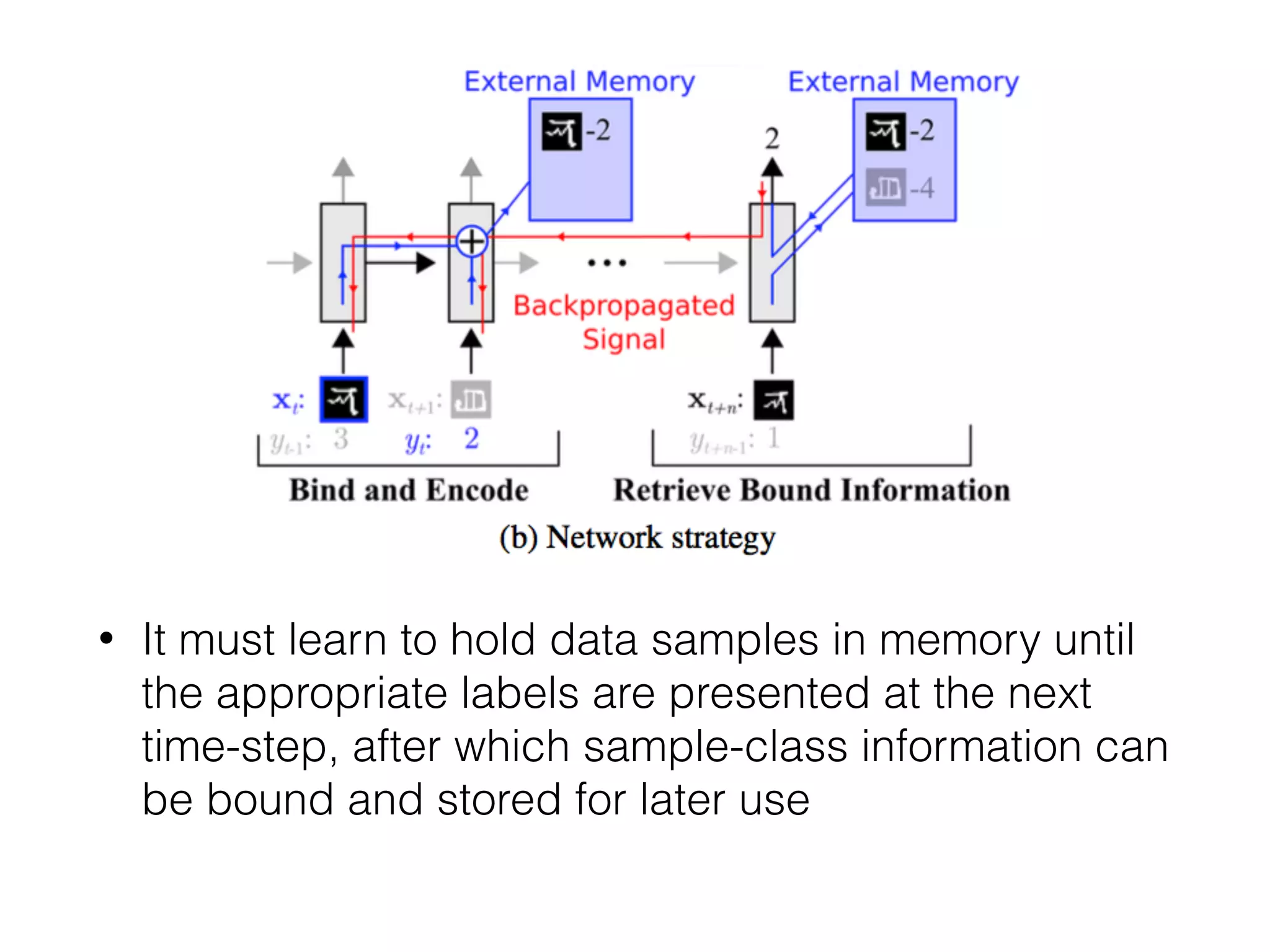
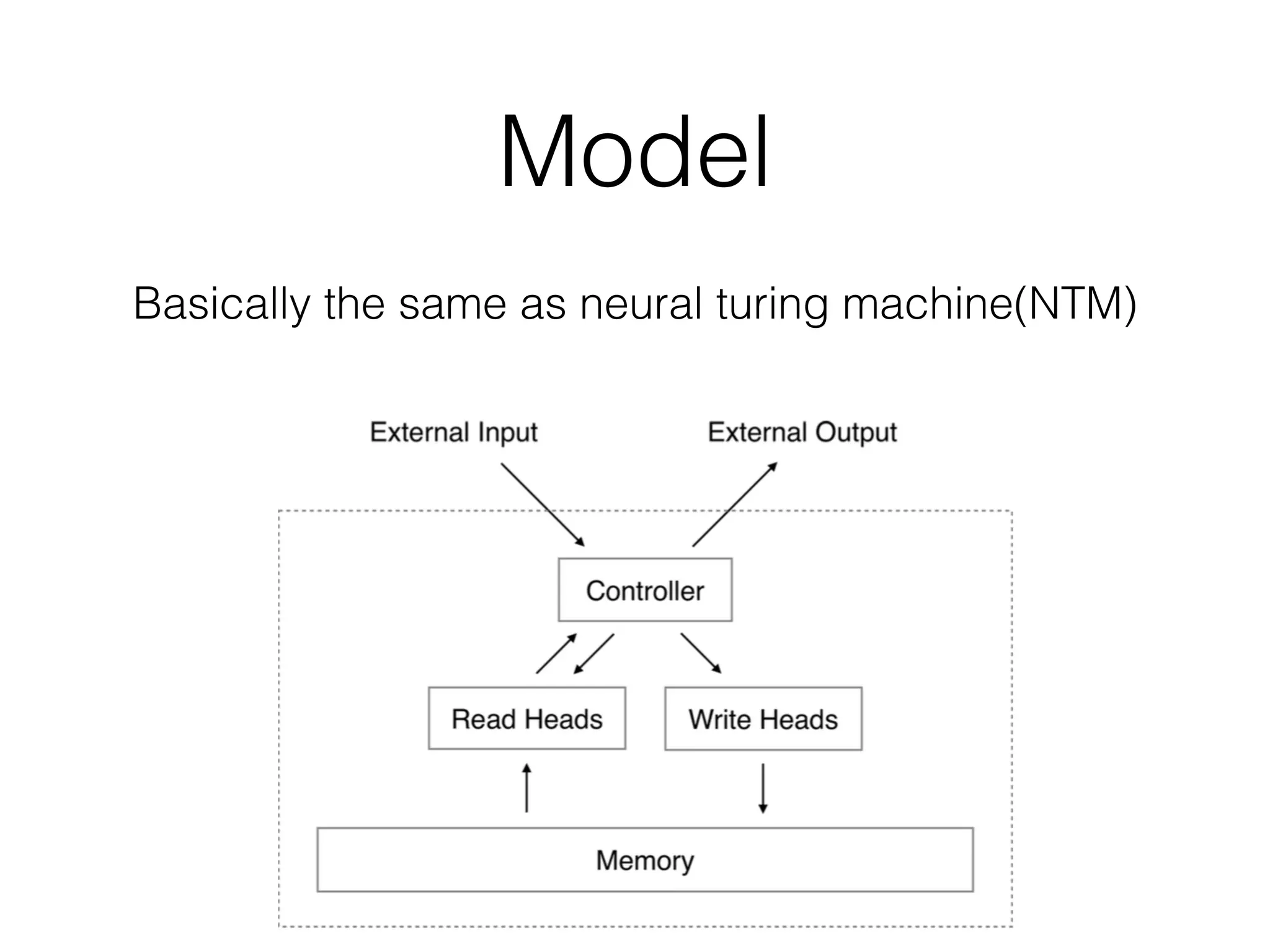





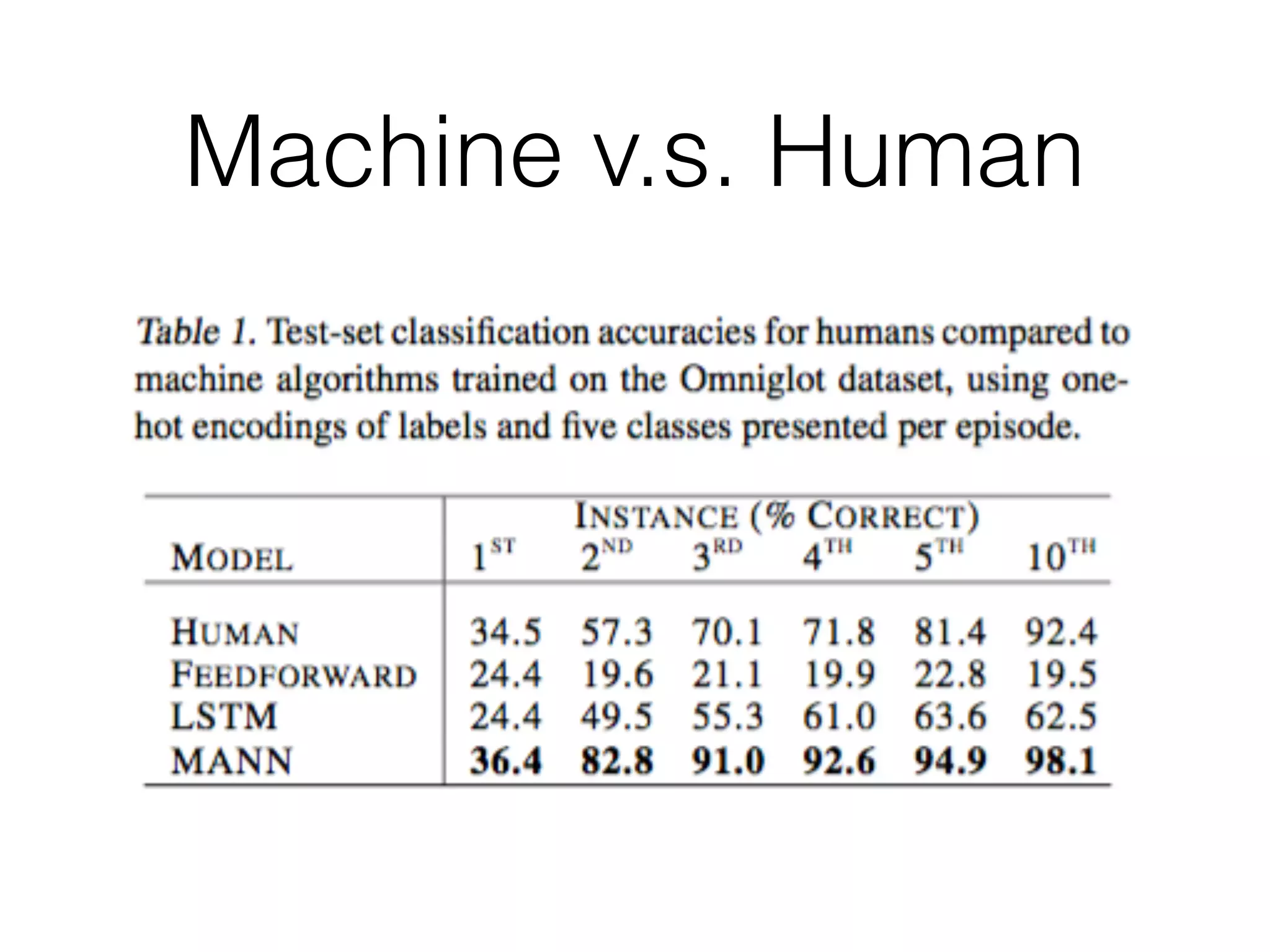


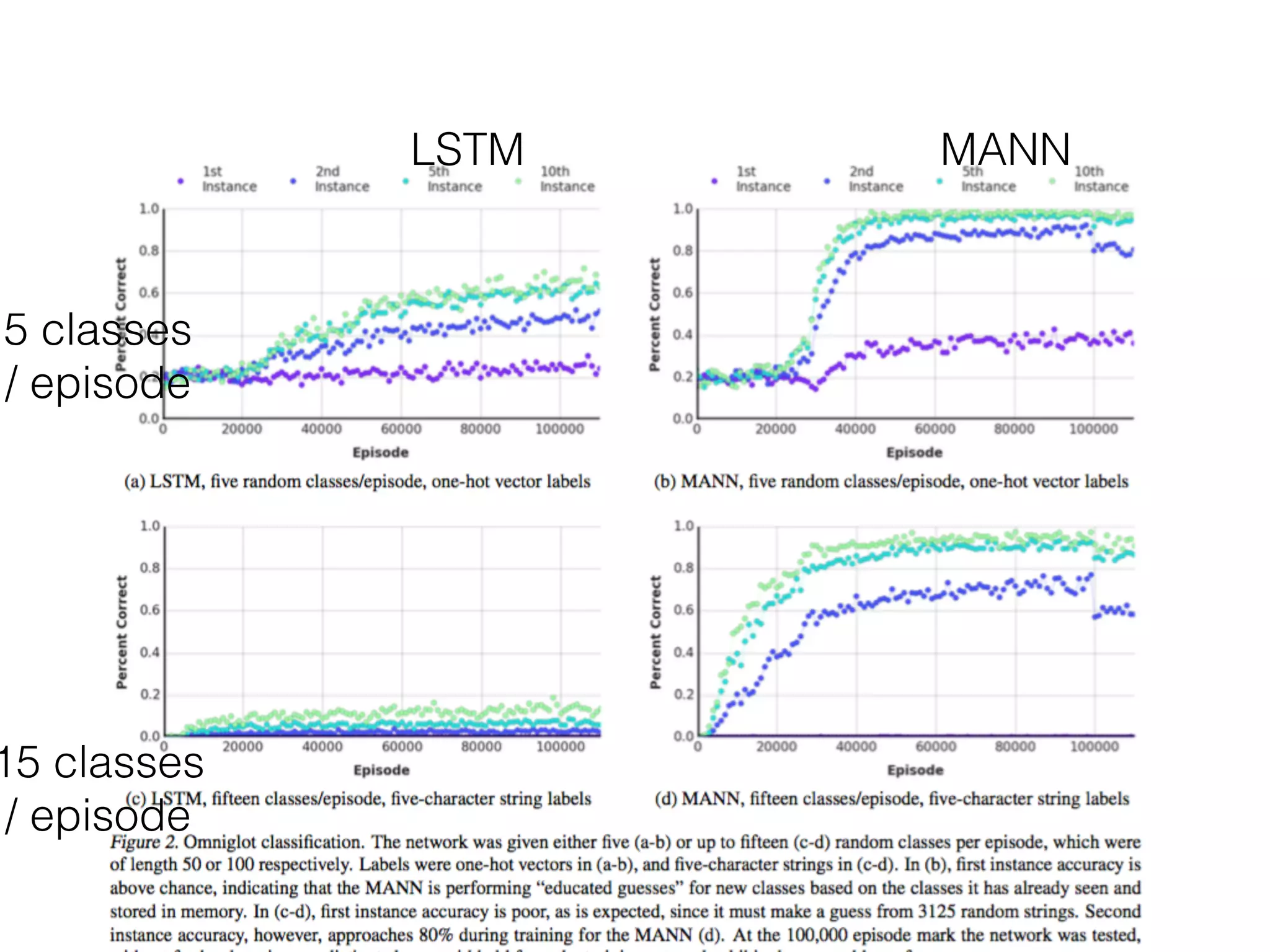
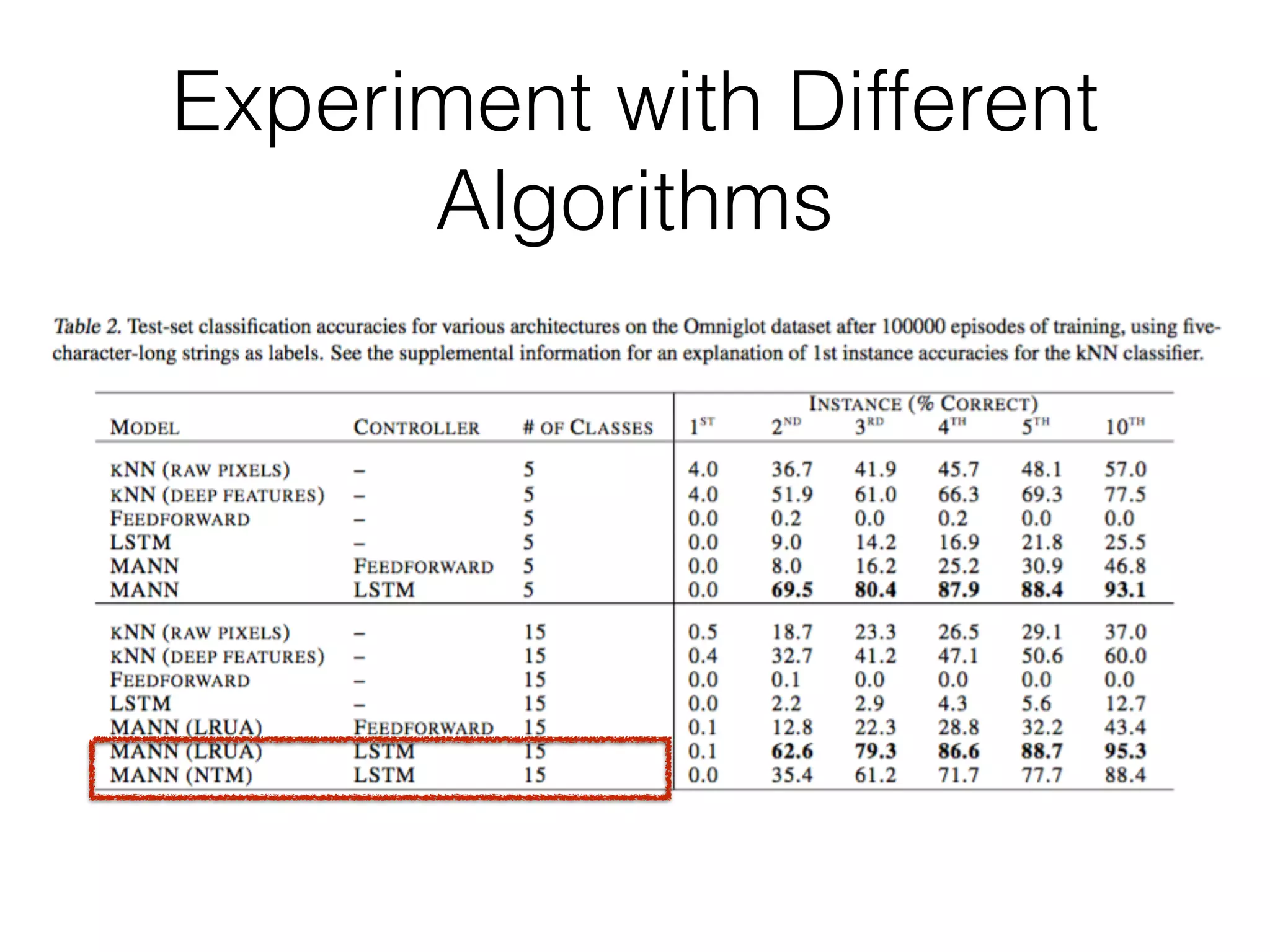


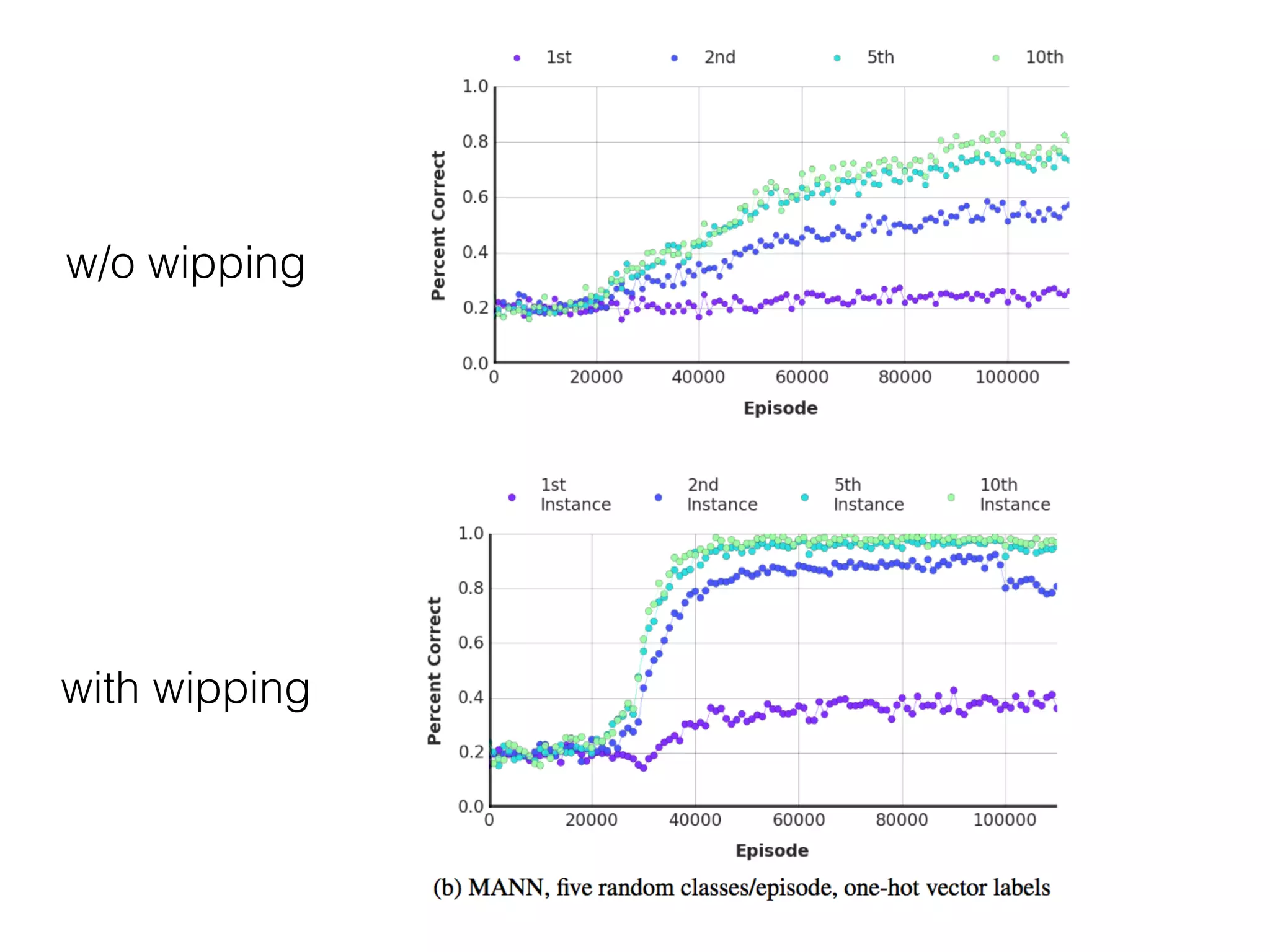

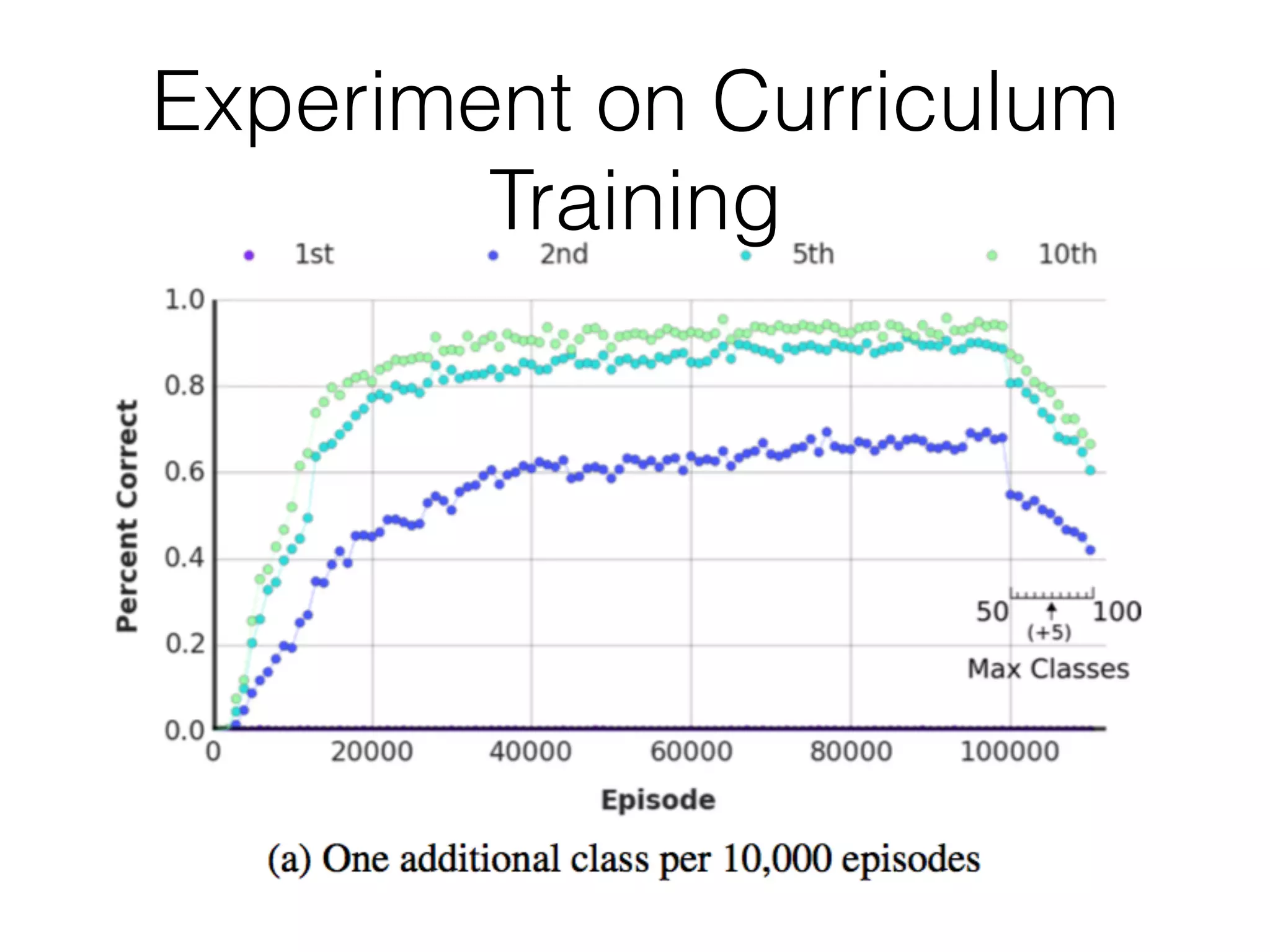



































This document summarizes a research paper on memory-augmented neural networks (MANN) for meta-learning. The paper proposes a MANN model that learns to do classification on unseen classes by learning the sample-class binding in an external memory rather than network weights. The MANN outperforms k-nearest neighbors and using an LSTM controller performs better than a feedforward controller. Experiments show the MANN can rapidly learn from small amounts of data, as wiping memory between tasks encourages incremental learning while retaining relevant background knowledge.














































![[DL輪読会]Understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170217-170217024917-thumbnail.jpg?width=640&height=640&fit=bounds)


![[PR12] PR-036 Learning to Remember Rare Events](https://cdn.slidesharecdn.com/ss_thumbnails/pr12pr-036learningtoremeberrareevents-170917140144-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)



