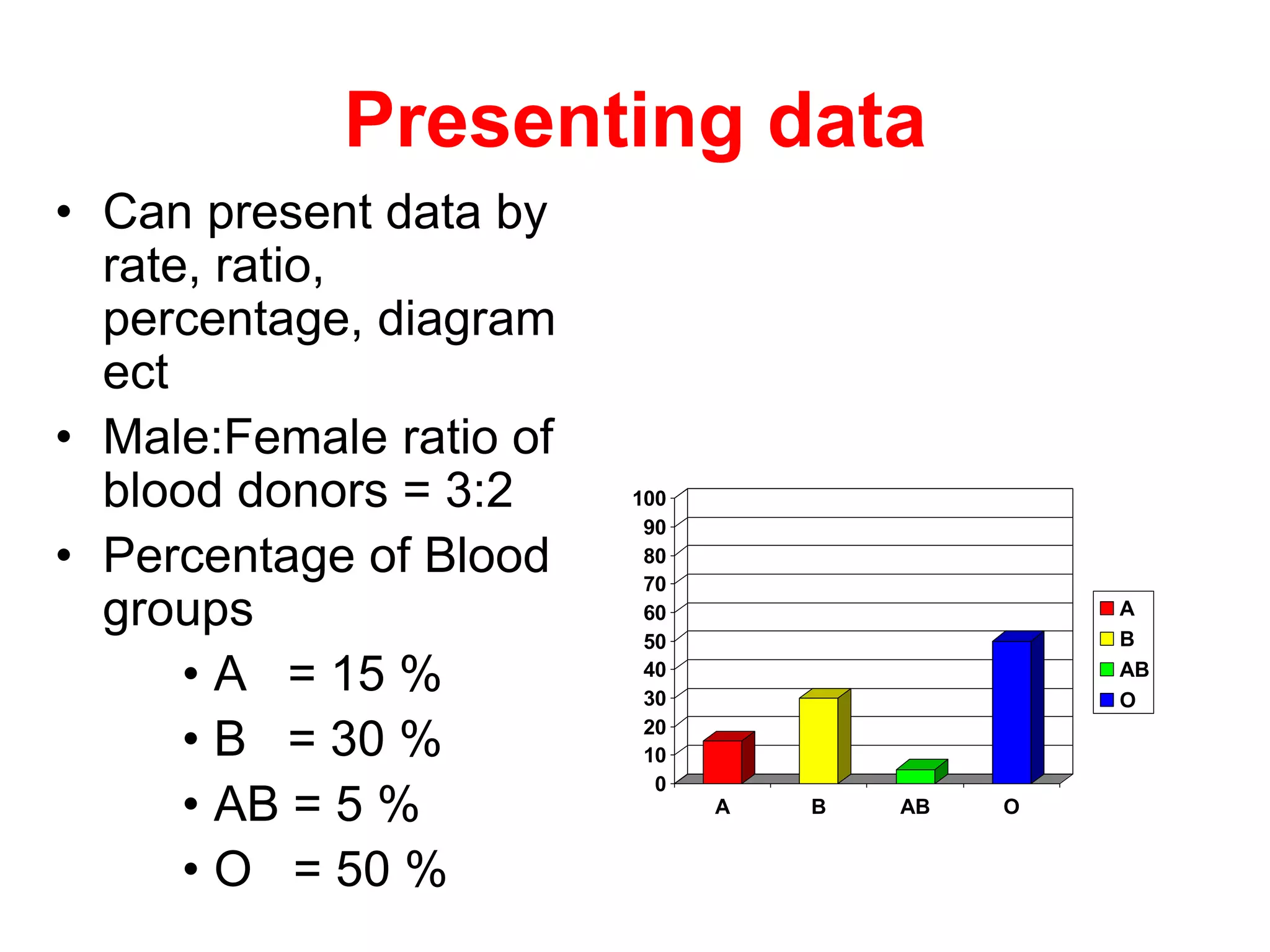
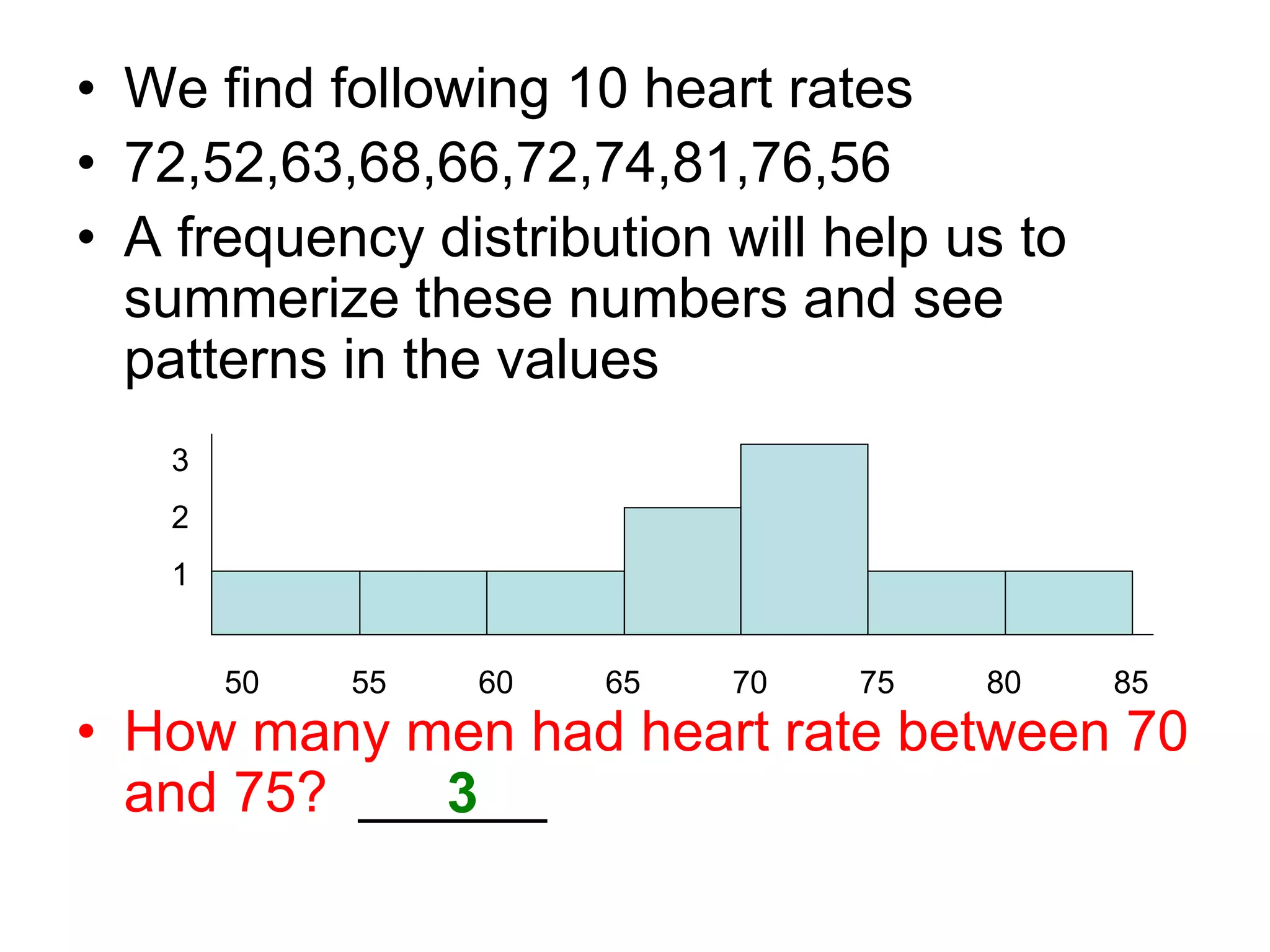
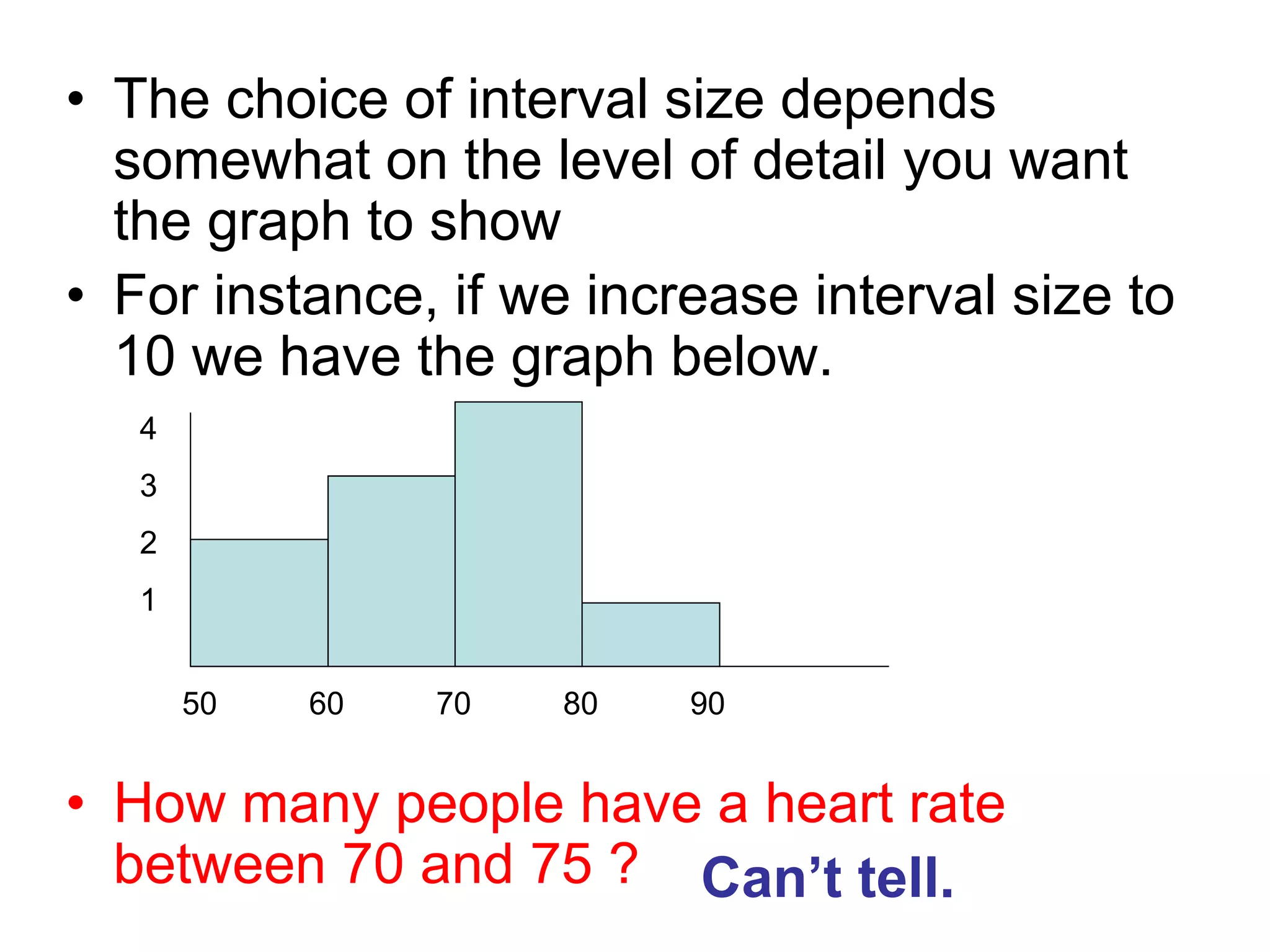
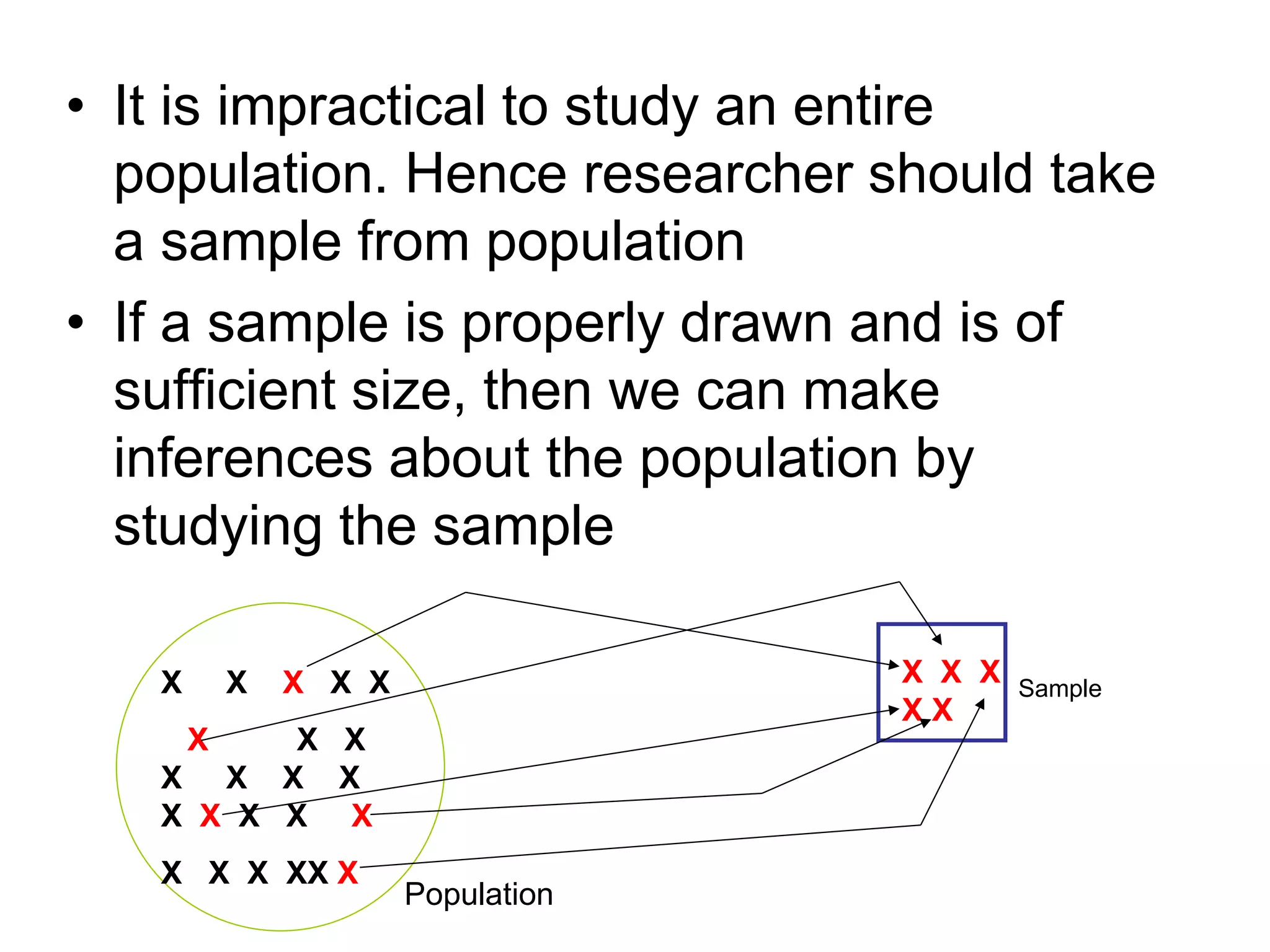
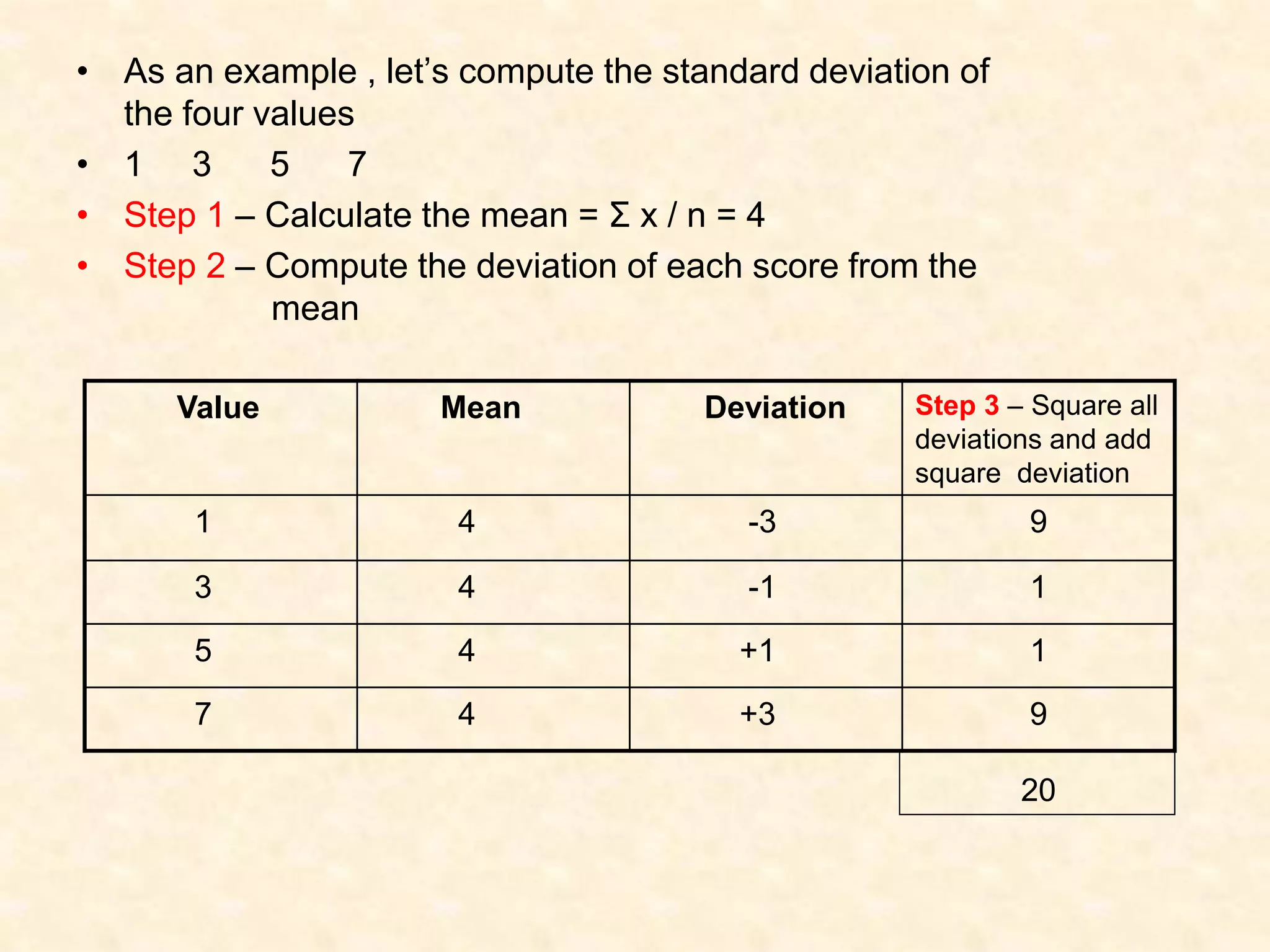
Statistics involves collecting, organizing, summarizing, presenting, and analyzing data to draw valid conclusions. It can be used to describe characteristics of groups through descriptive statistics or make inferences about larger populations based on samples using inferential statistics. Common techniques for summarizing data include frequency distributions, measures of central tendency like mean, median and mode, and measures of dispersion like range, interquartile range, and standard deviation. Properly collecting a sample from a population allows researchers to make inferences about the population.



























































































![Lesson3 lpart one - Measures mean [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lesson2-measuresmeanautosaved-241011173812-613e1e66-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 25] Stefan_Milosevic - AI and digital twins in precision oncology...](https://cdn.slidesharecdn.com/ss_thumbnails/nnmuciuxr2ugh4d9pzkg-1-251126104228-148c7fe8-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jurij Kodre - What Can Healthcare Learn From Finance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/q87nzrwtd6ihsqqtrqdr-7-251126104228-00657fba-thumbnail.jpg?width=640&height=640&fit=bounds)







