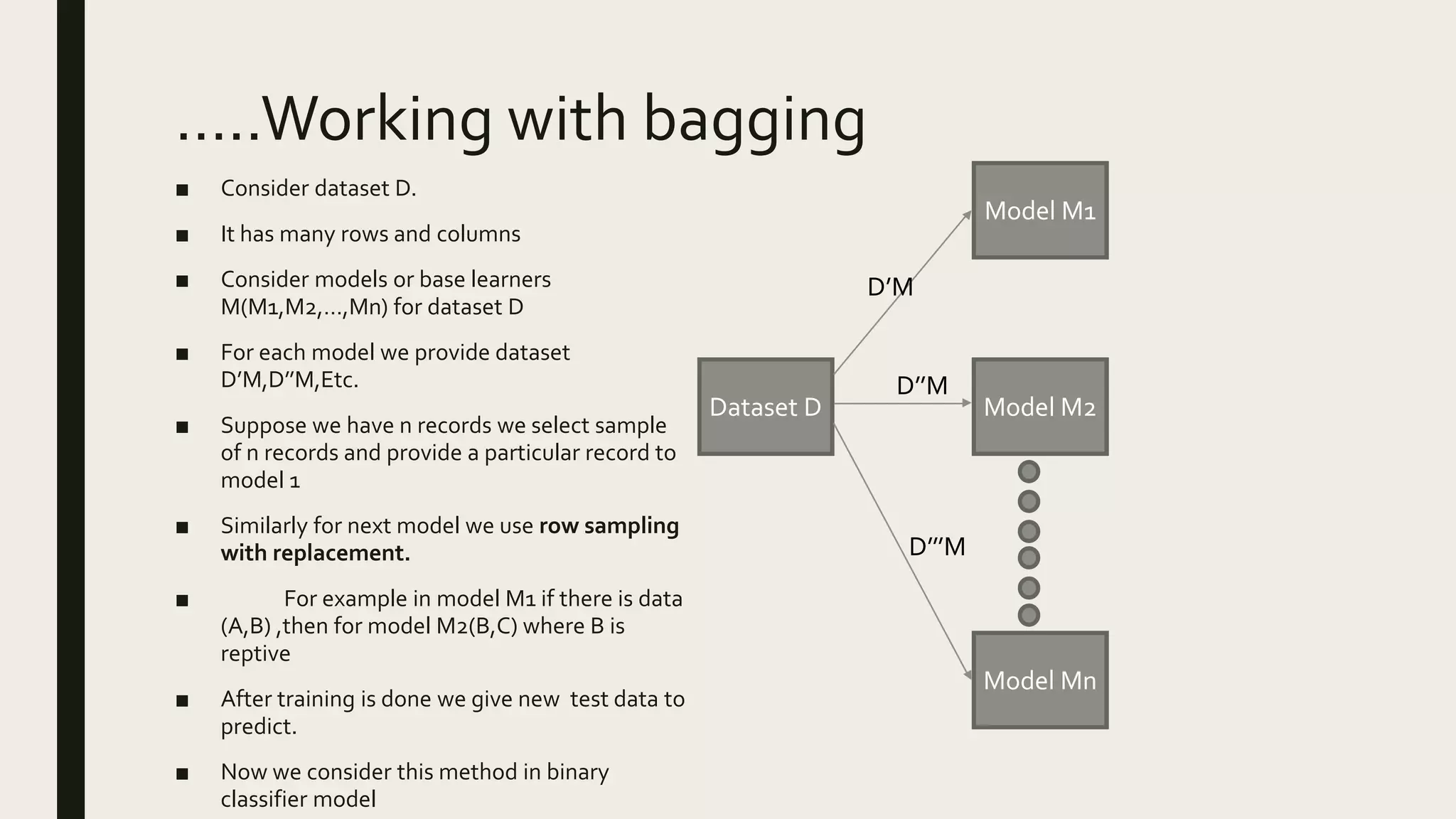
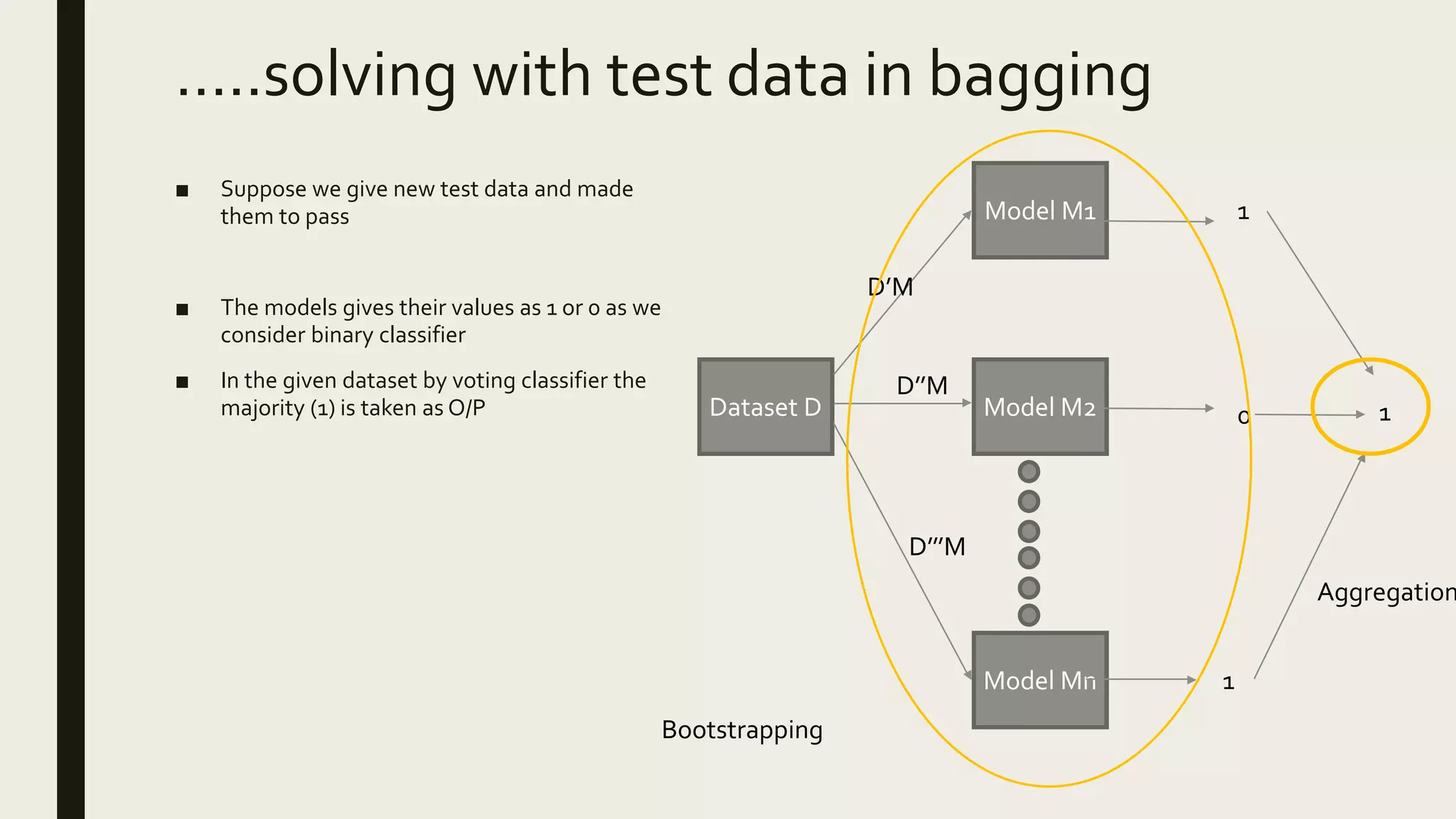
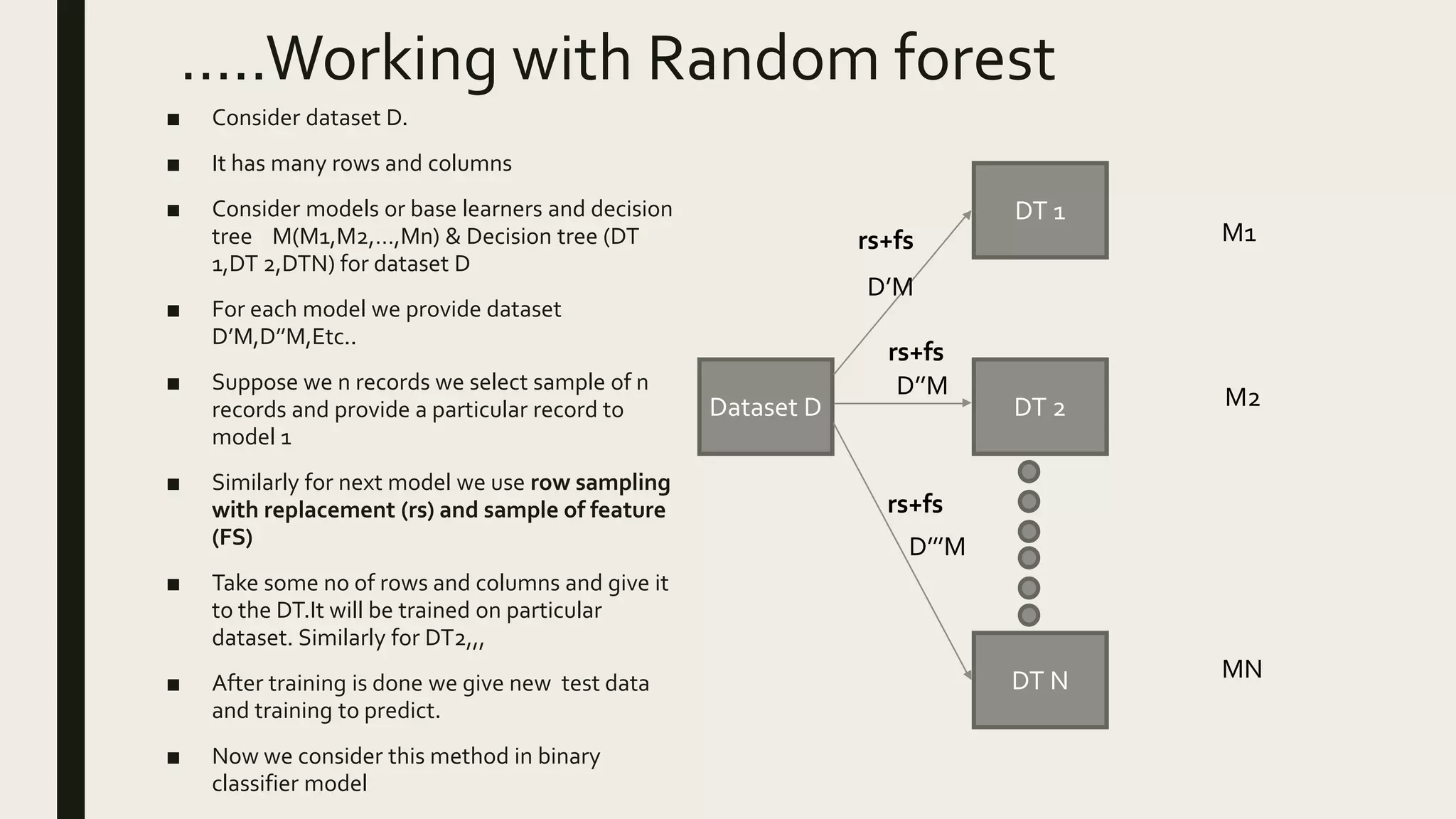
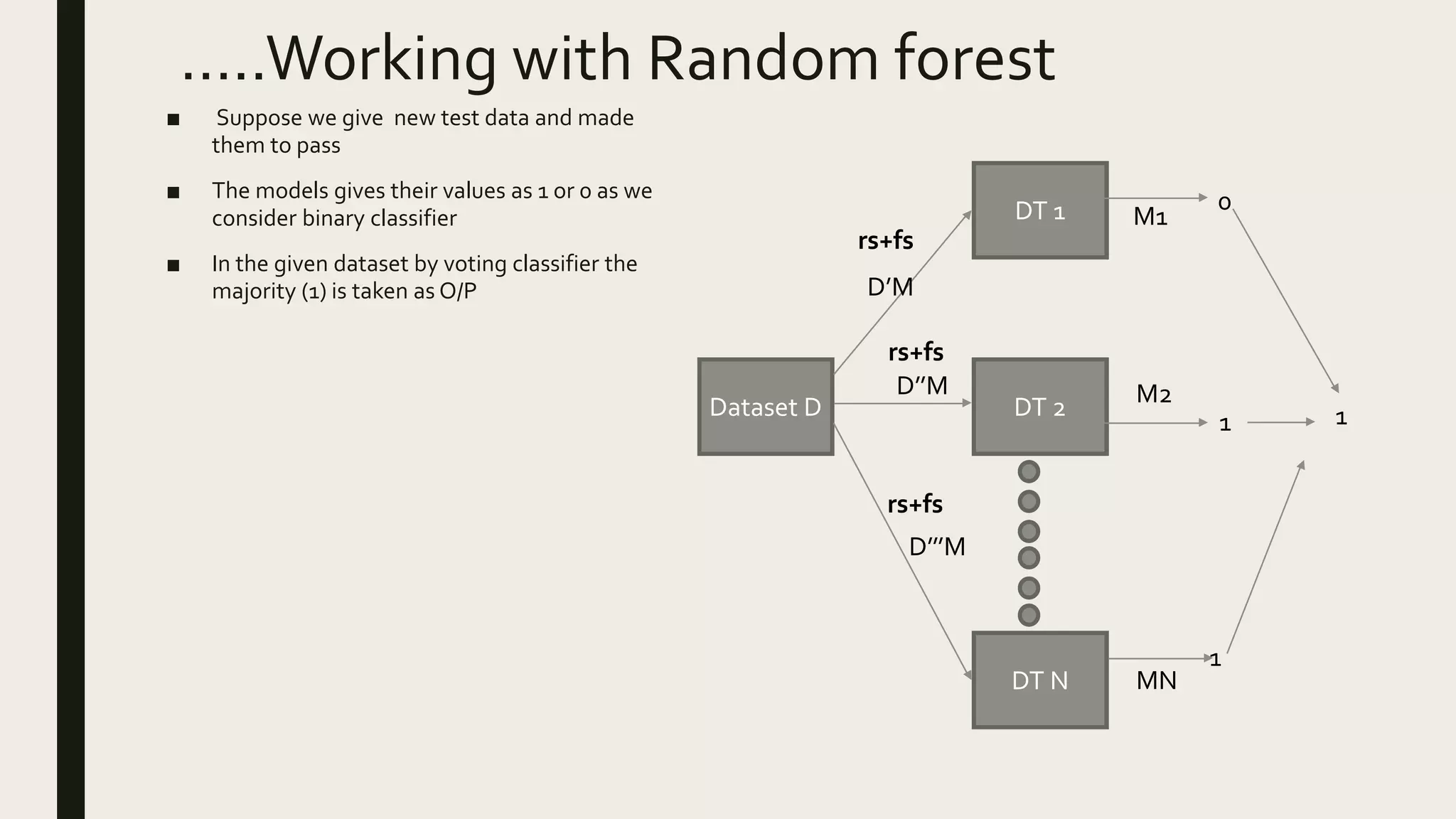
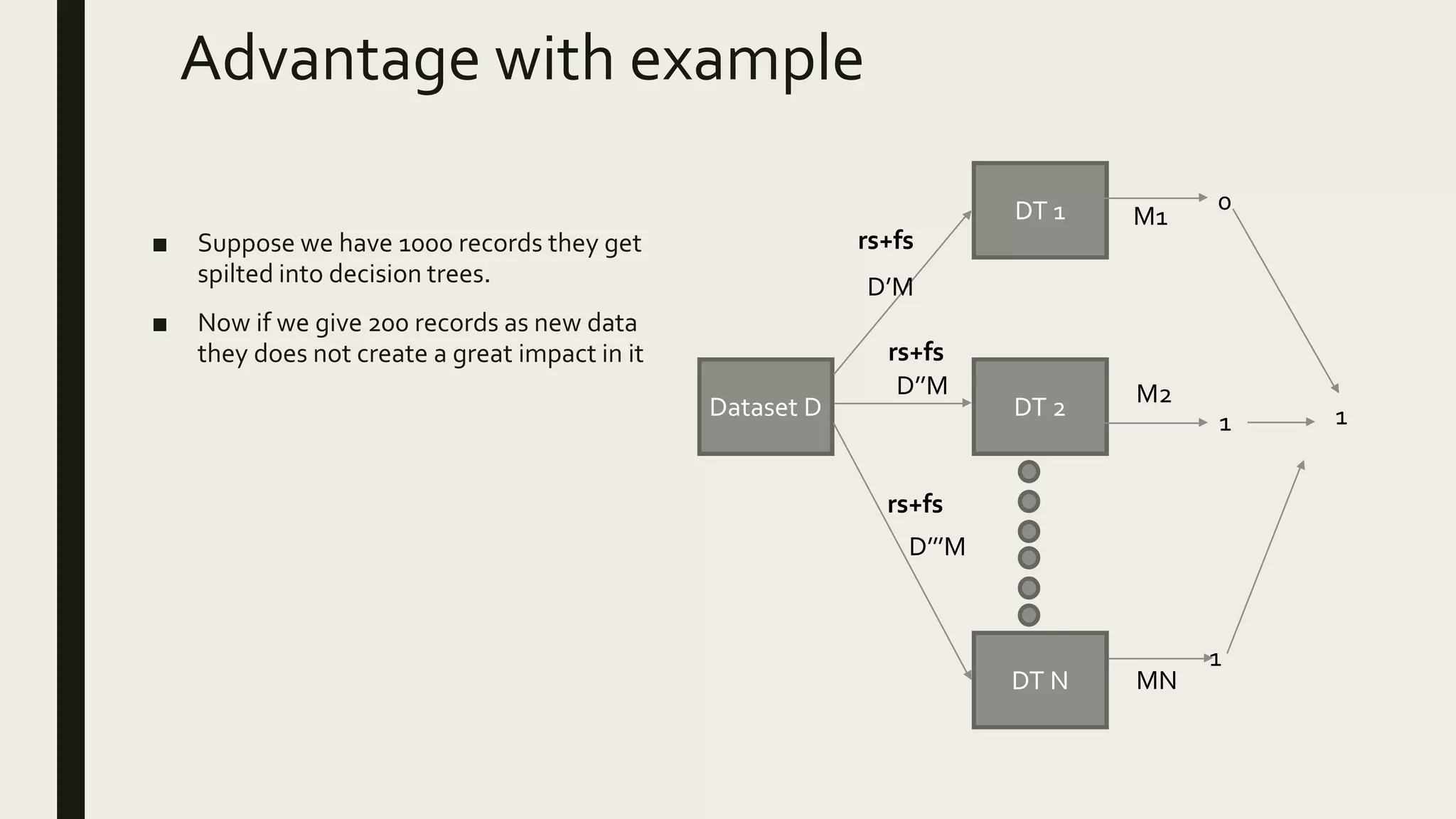
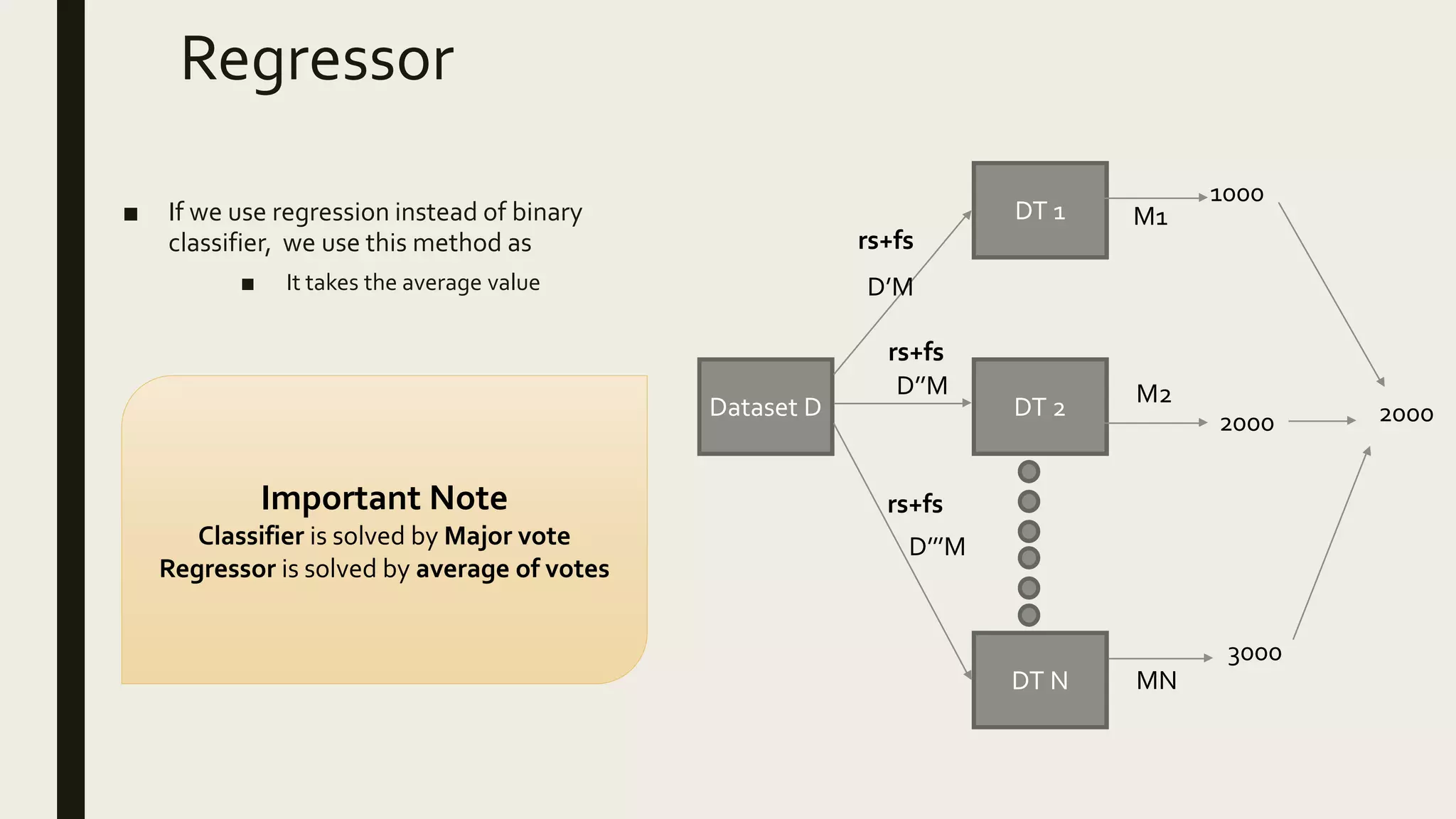
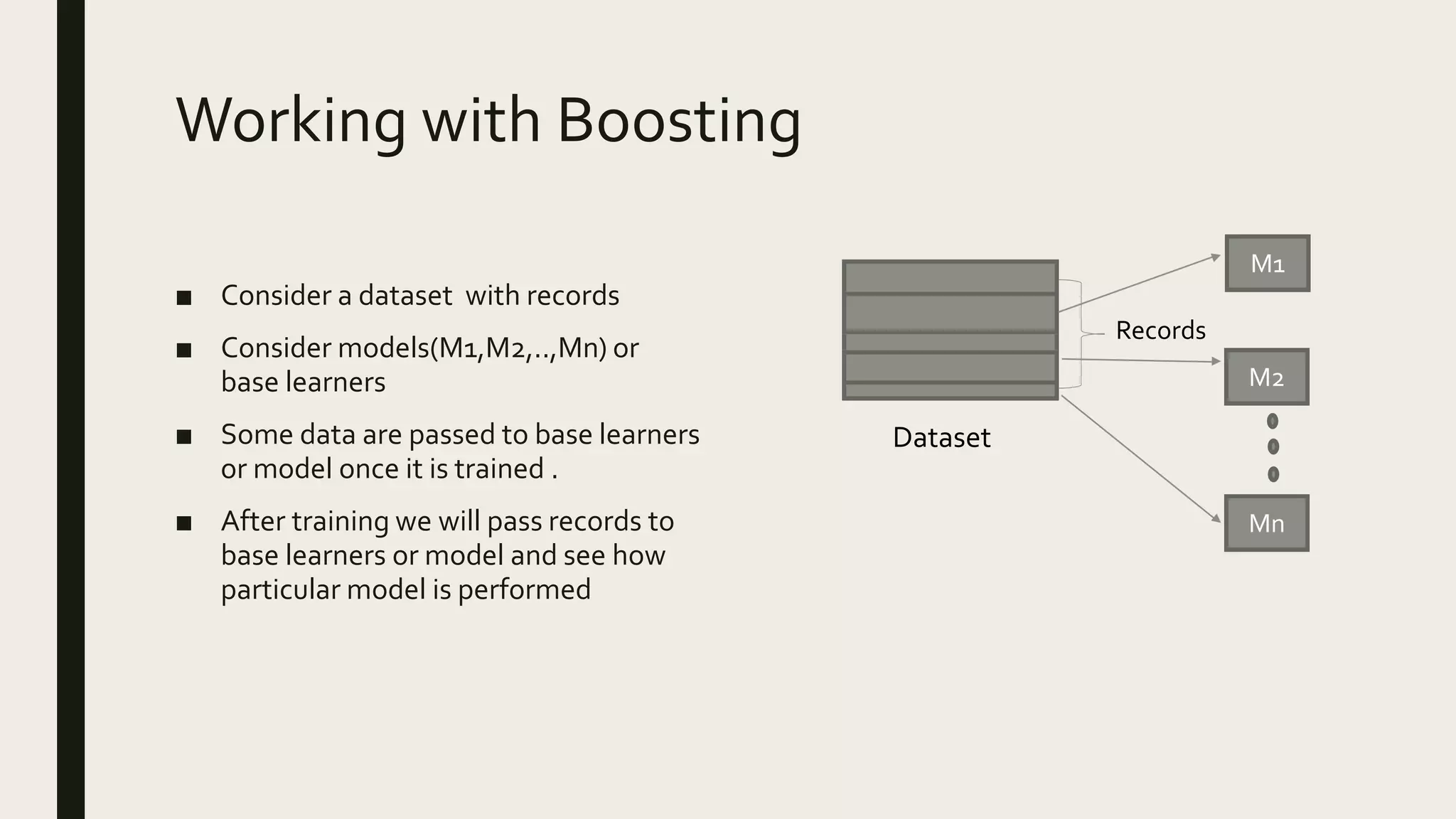
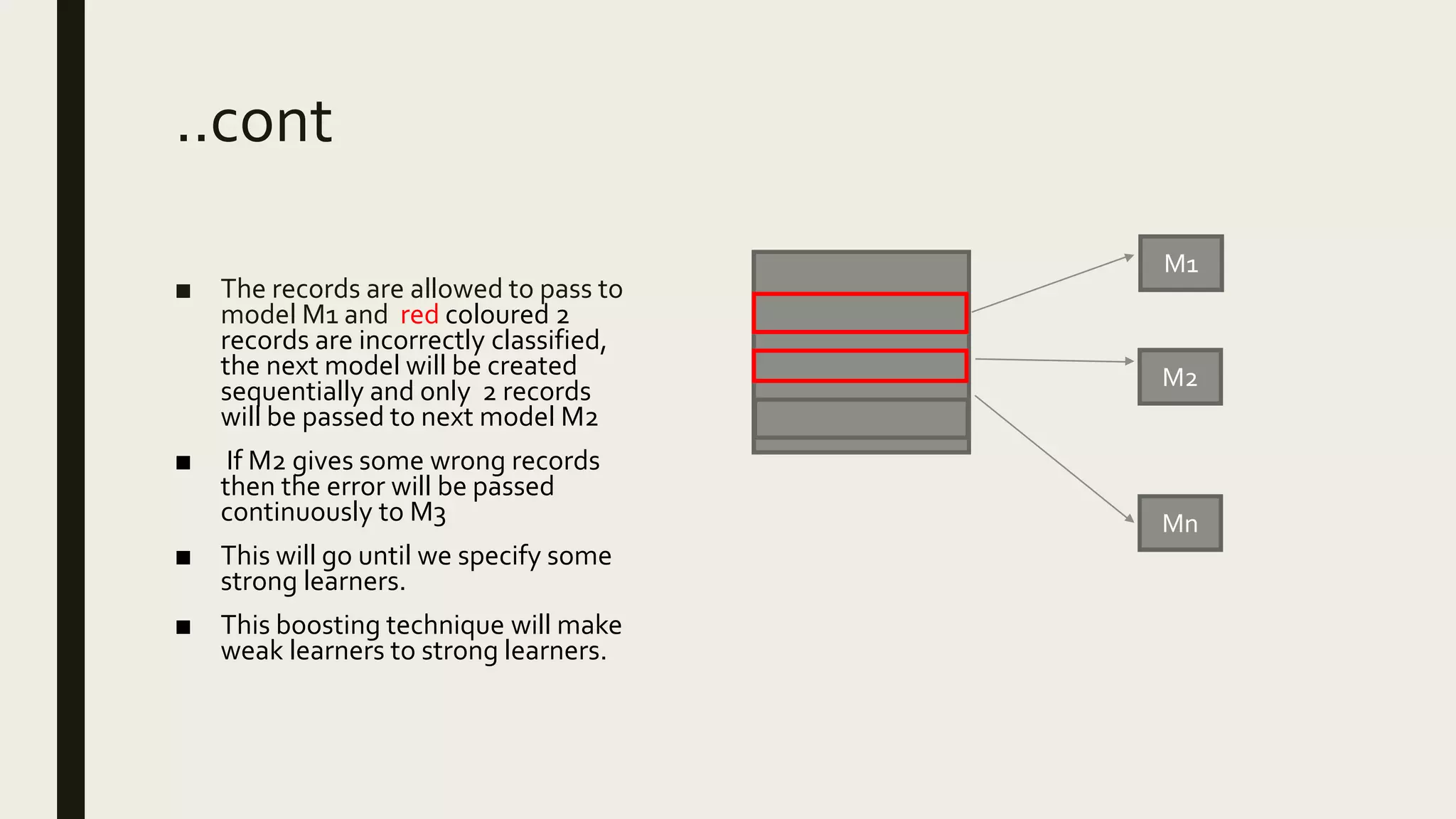
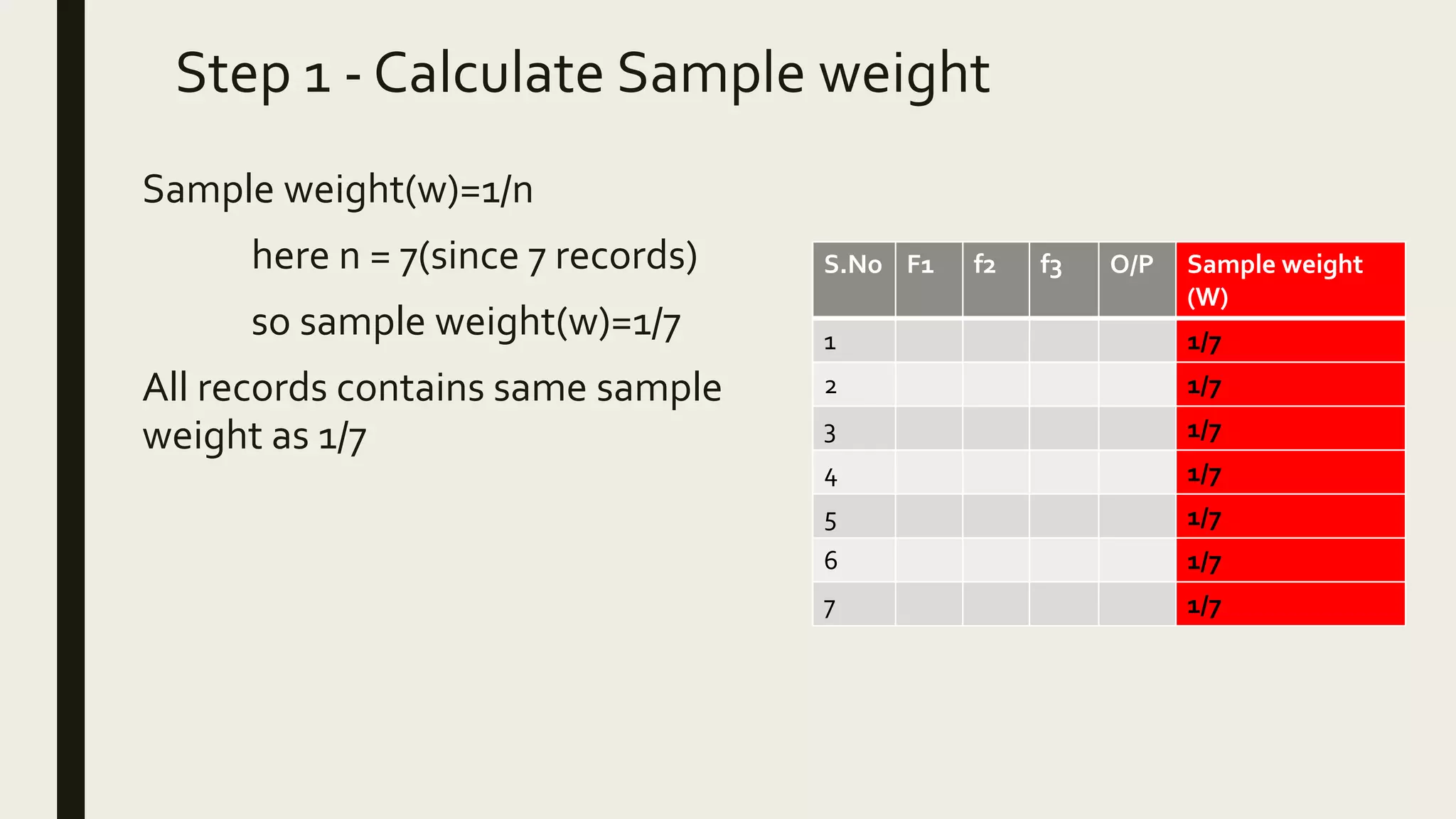
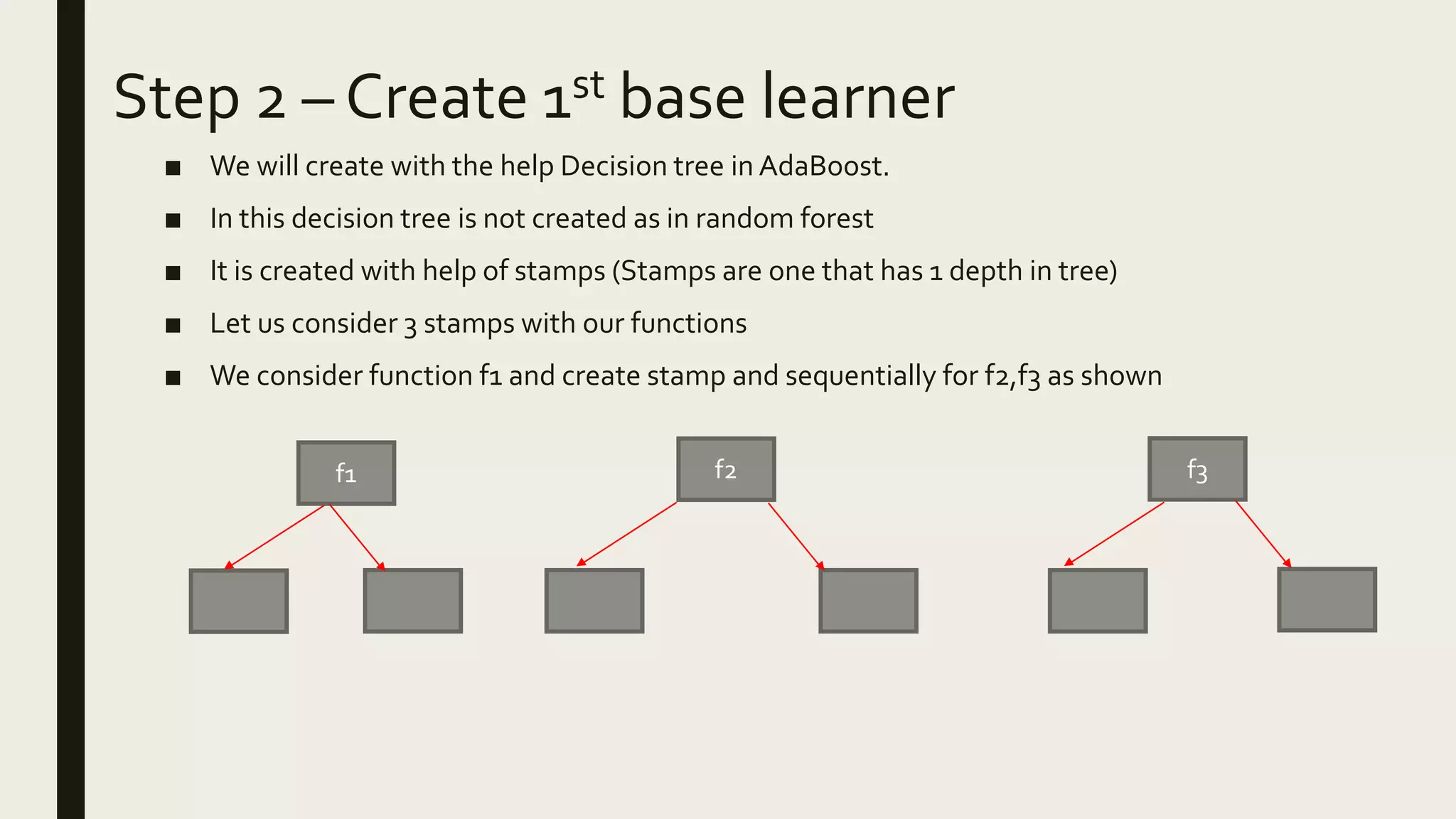
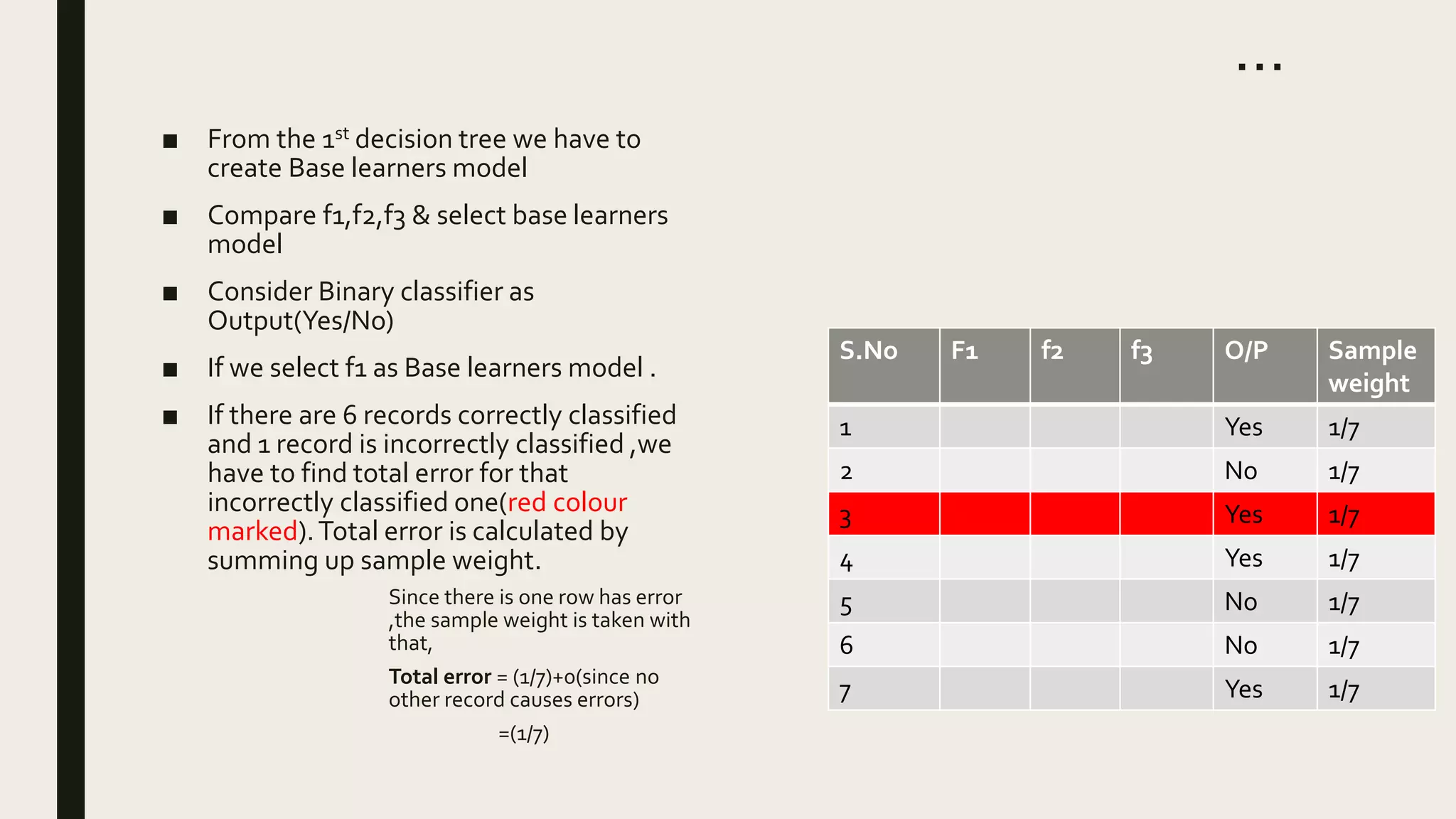
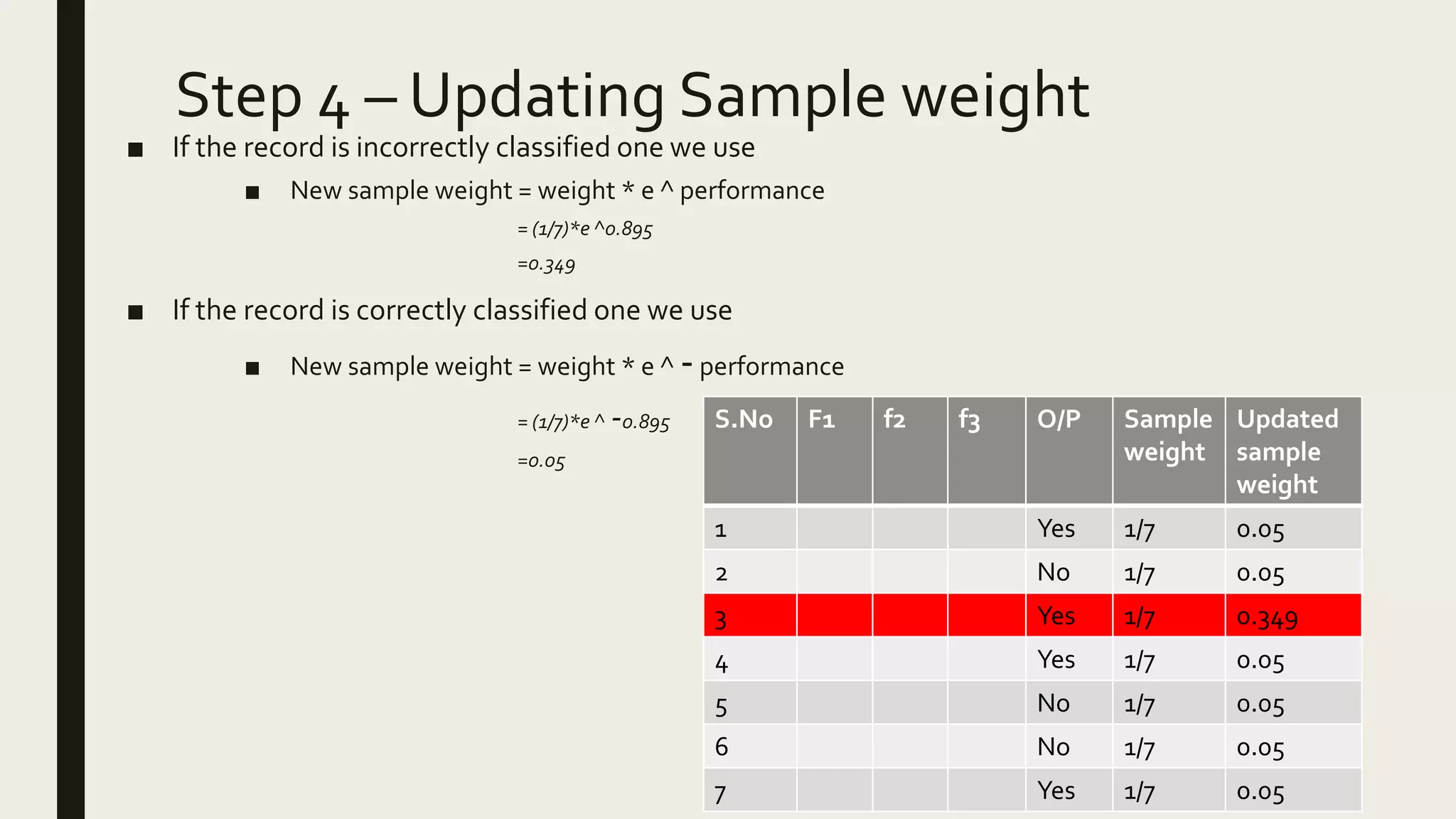
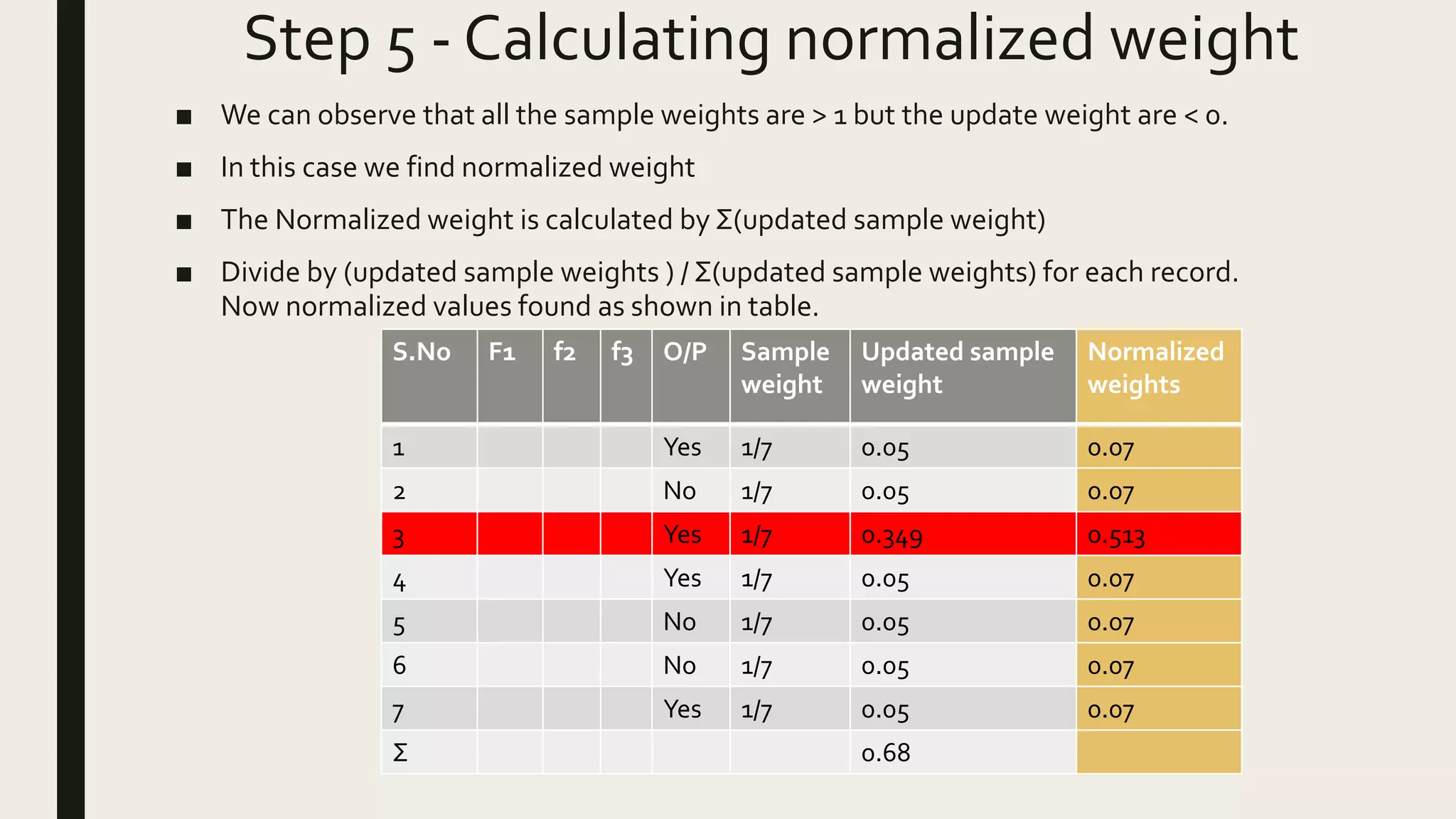
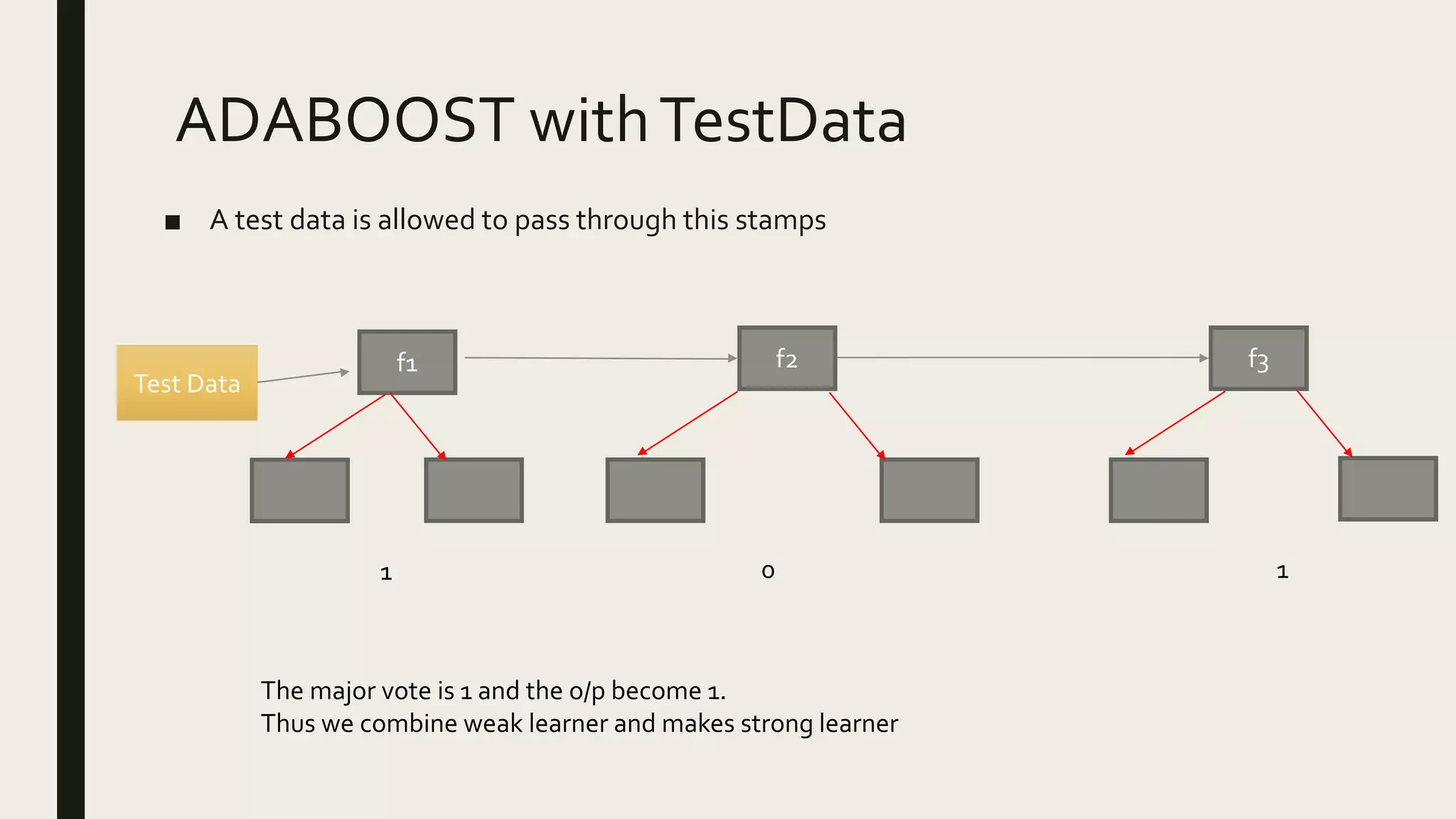
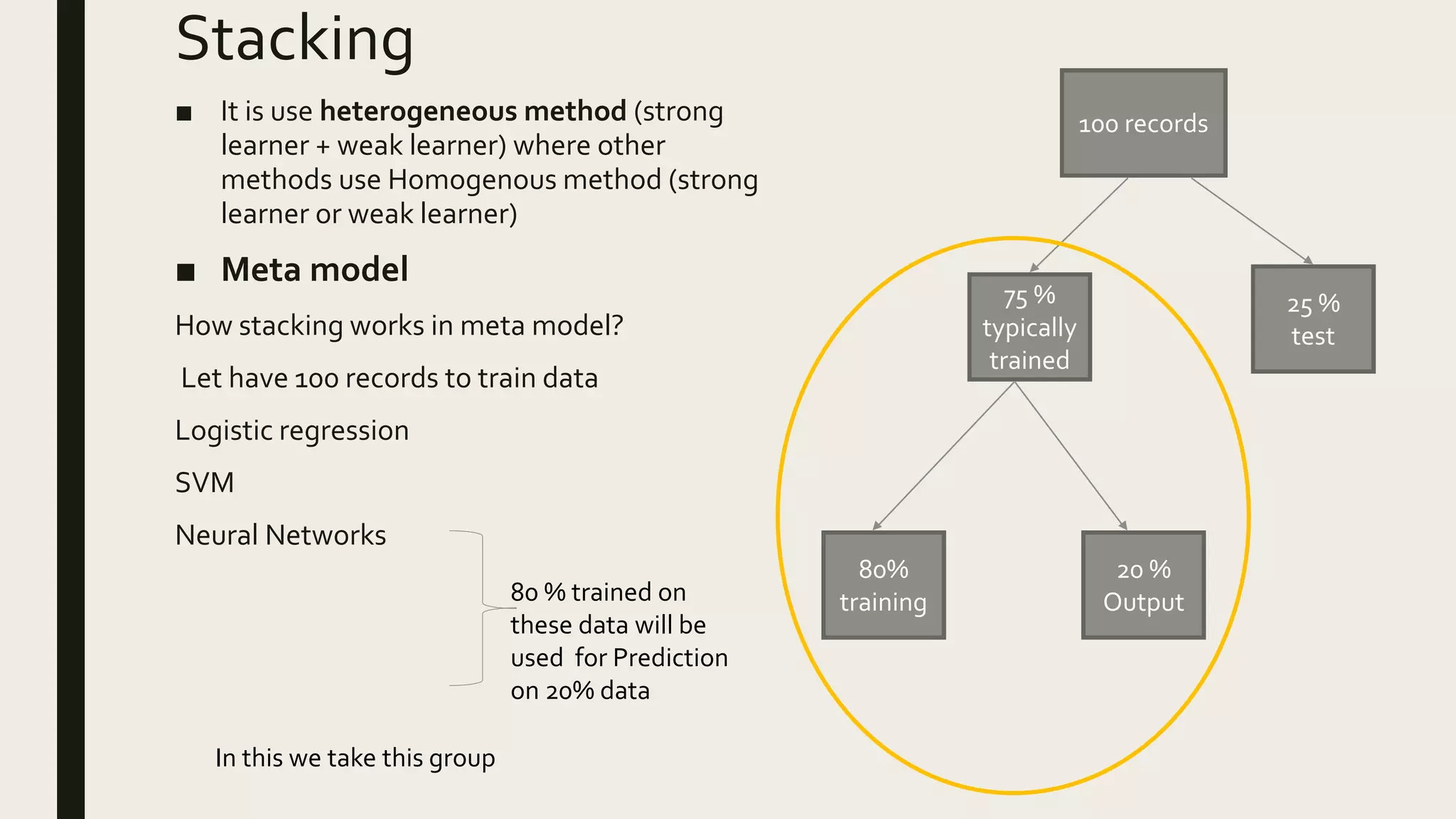
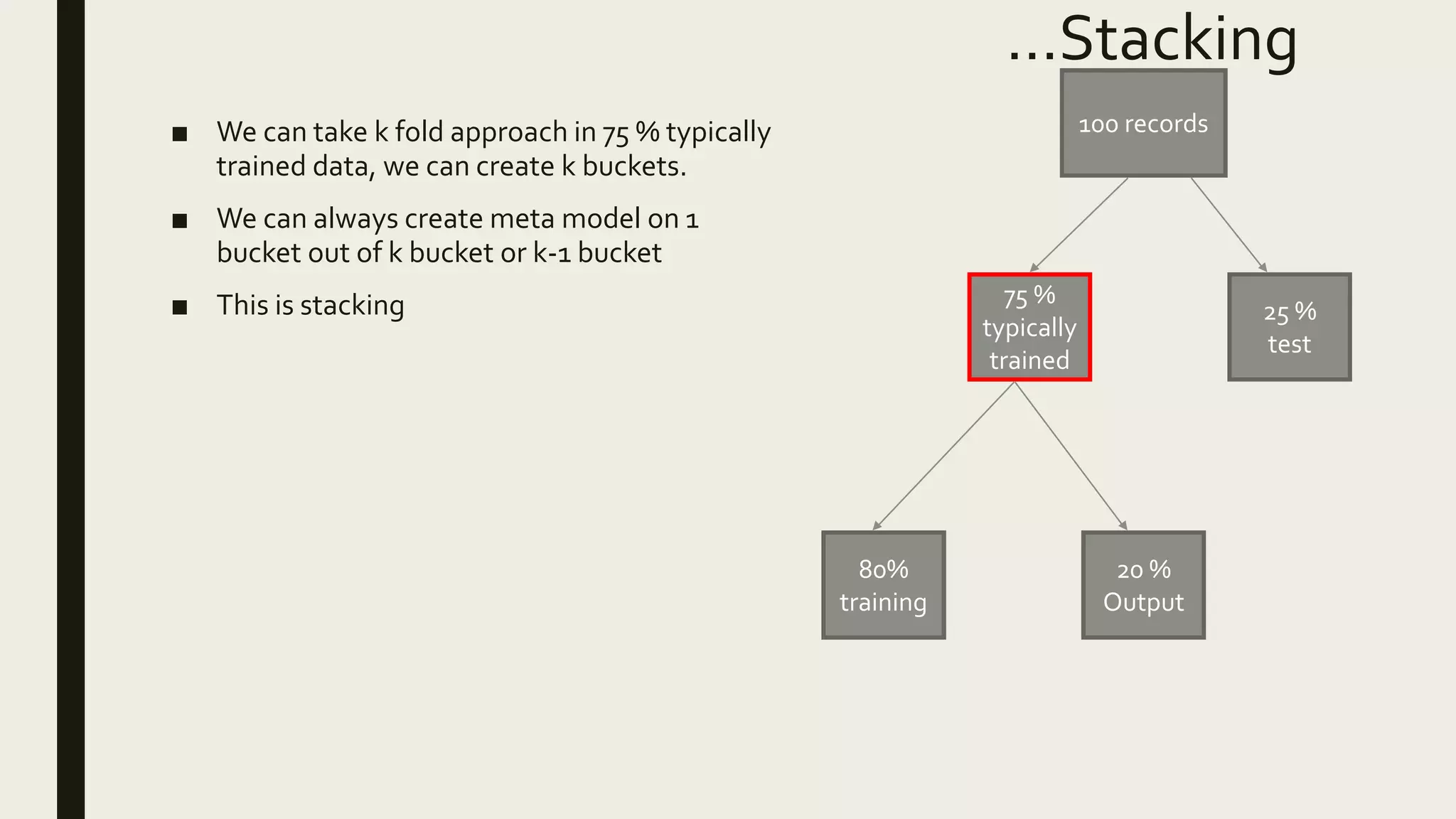
Ensemble methods combine multiple machine learning models to obtain better predictive performance than from any individual model. There are two main types of ensemble methods: sequential (e.g AdaBoost) where models are generated one after the other, and parallel (e.g Random Forest) where models are generated independently. Popular ensemble methods include bagging, boosting, and stacking. Bagging averages predictions from models trained on random samples of the data, while boosting focuses on correcting previous models' errors. Stacking trains a meta-model on predictions from other models to produce a final prediction.