



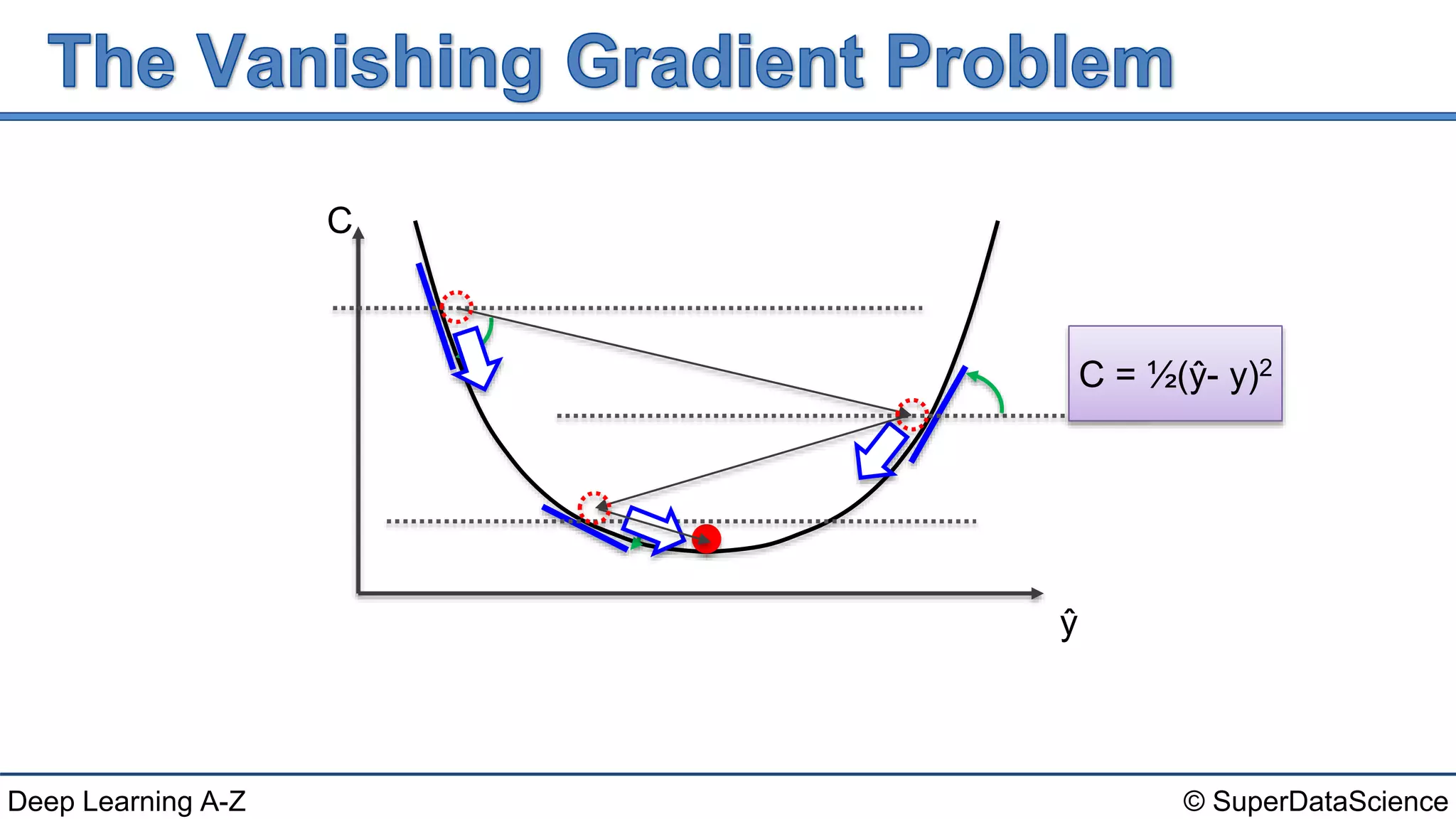
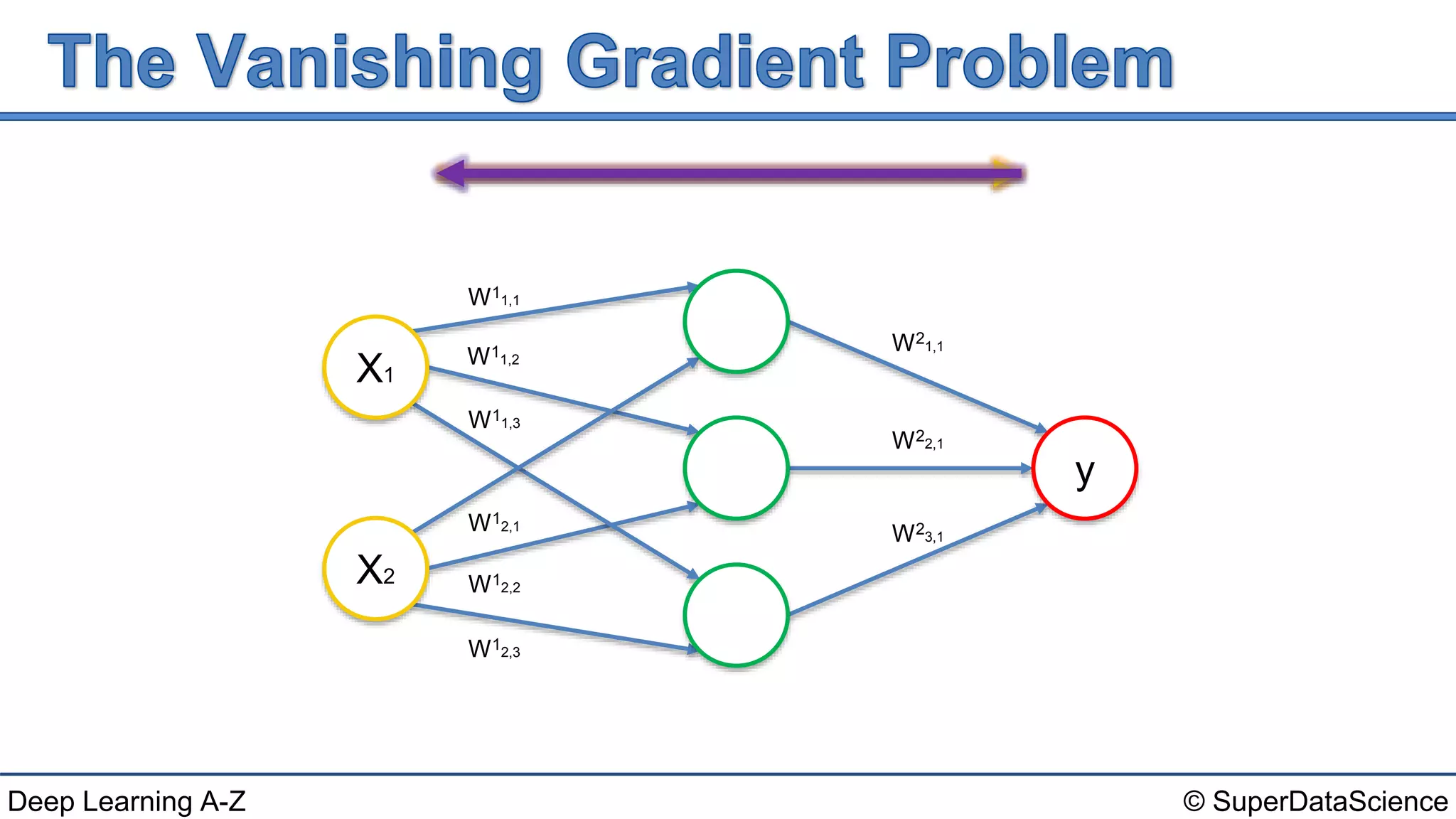
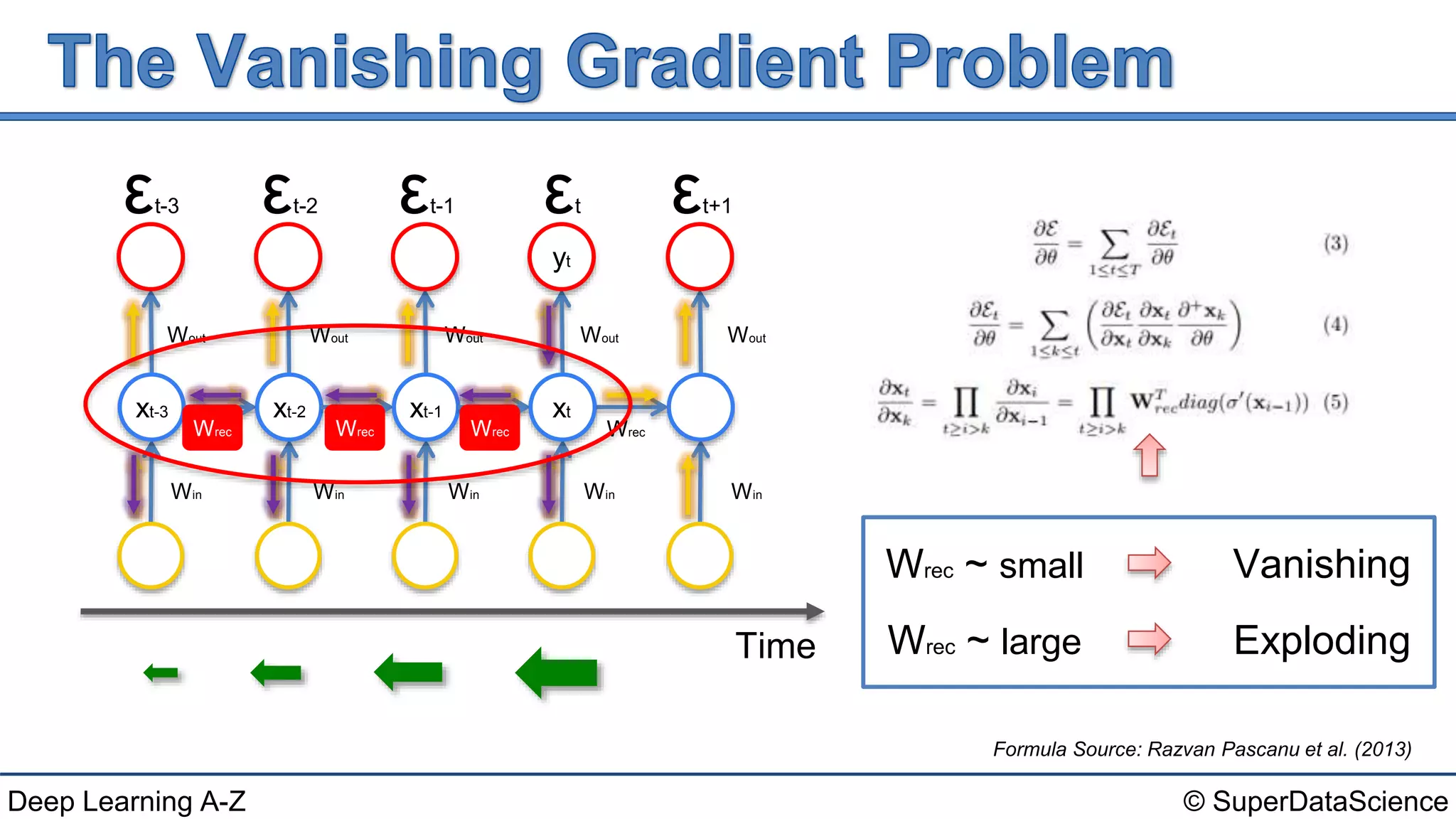














This document discusses the problems of exploding and vanishing gradients that can occur when training recurrent neural networks. It provides solutions for each problem, such as weight initialization techniques, echo state networks, and LSTM networks. It also references three seminal papers from 1991, 1994, and 2013 that investigated issues with training recurrent networks and long short-term dependencies.























































































