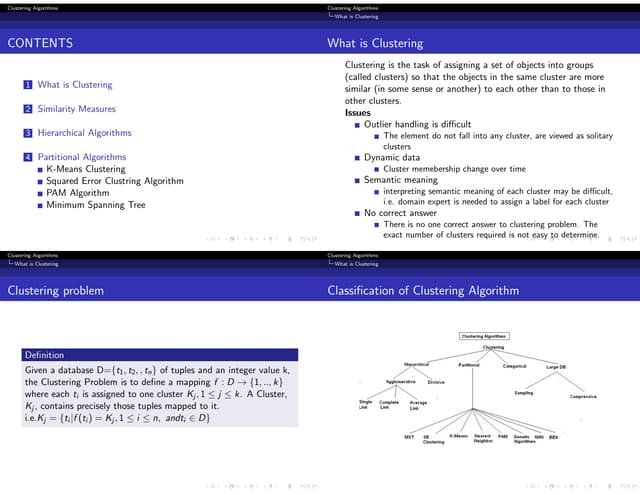
Introduction
Hierarchical Clustering Approach
Atypical clustering analysis approach via partitioning data set sequentially
Construct nested partitions layer by layer via grouping objects into a tree of
clusters (without the need to know the number of clusters in advance)
Use (generalized) distance matrix as clustering criteria
4.
Introduction
Two sequential clusteringstrategies for constructing a tree of
clusters
1. Agglomerative: a bottom-up strategy
Initially each data object is in its own (atomic) cluster
Then merge these atomic clusters into larger and larger clusters
2. Divisive: a top-down strategy
Initially all objects are in one single cluster
Then the cluster is subdivided into smaller and smaller clusters
5.
Introduction
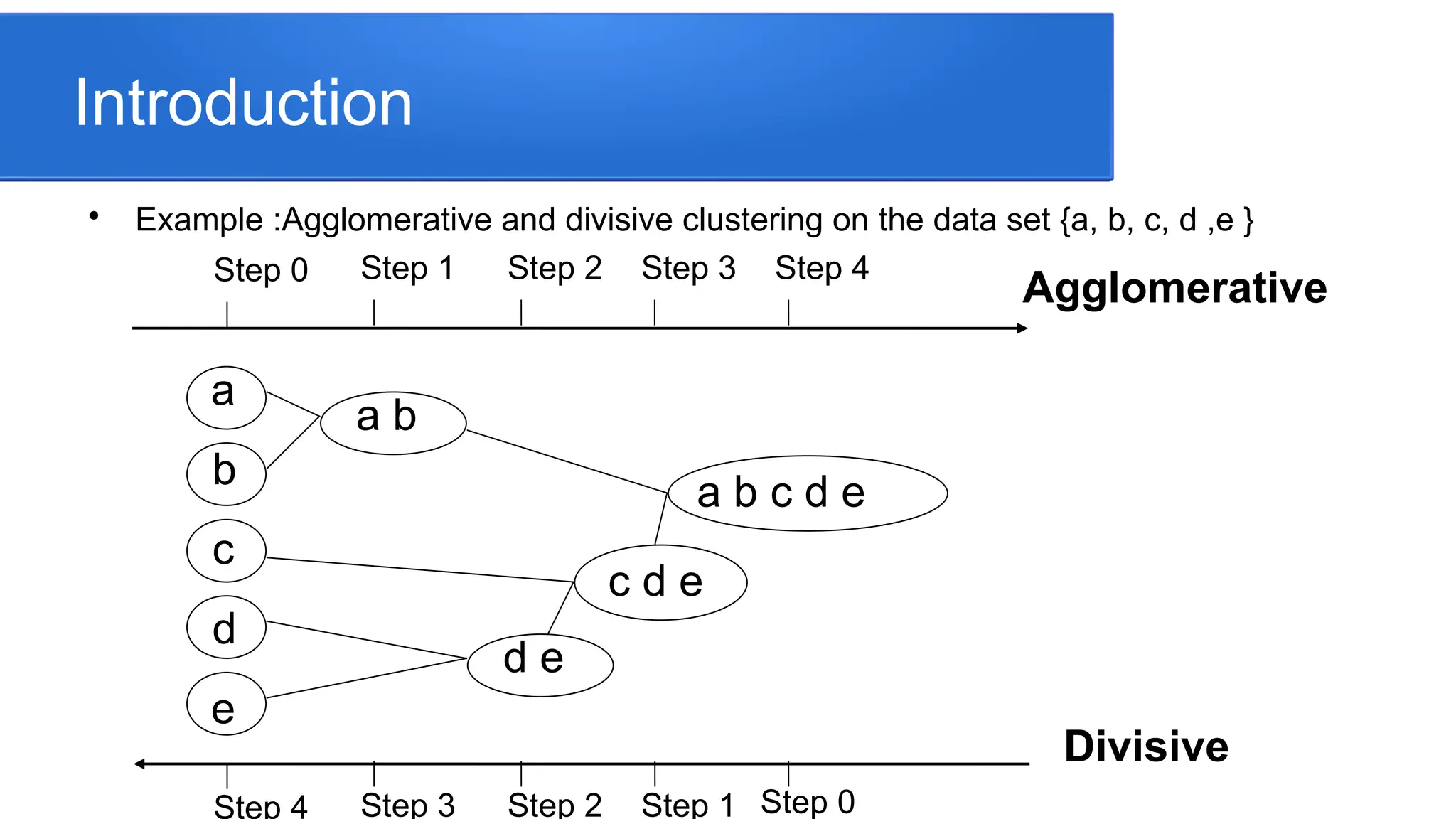
Example :Agglomerative anddivisive clustering on the data set {a, b, c, d ,e }
Step 0 Step 1 Step 2 Step 3 Step 4
b
d
c
e
a
a b
d e
c d e
a b c d e
Step 4 Step 3 Step 2 Step 1 Step 0
Agglomerative
Divisive
6.
Cluster Distance Measures
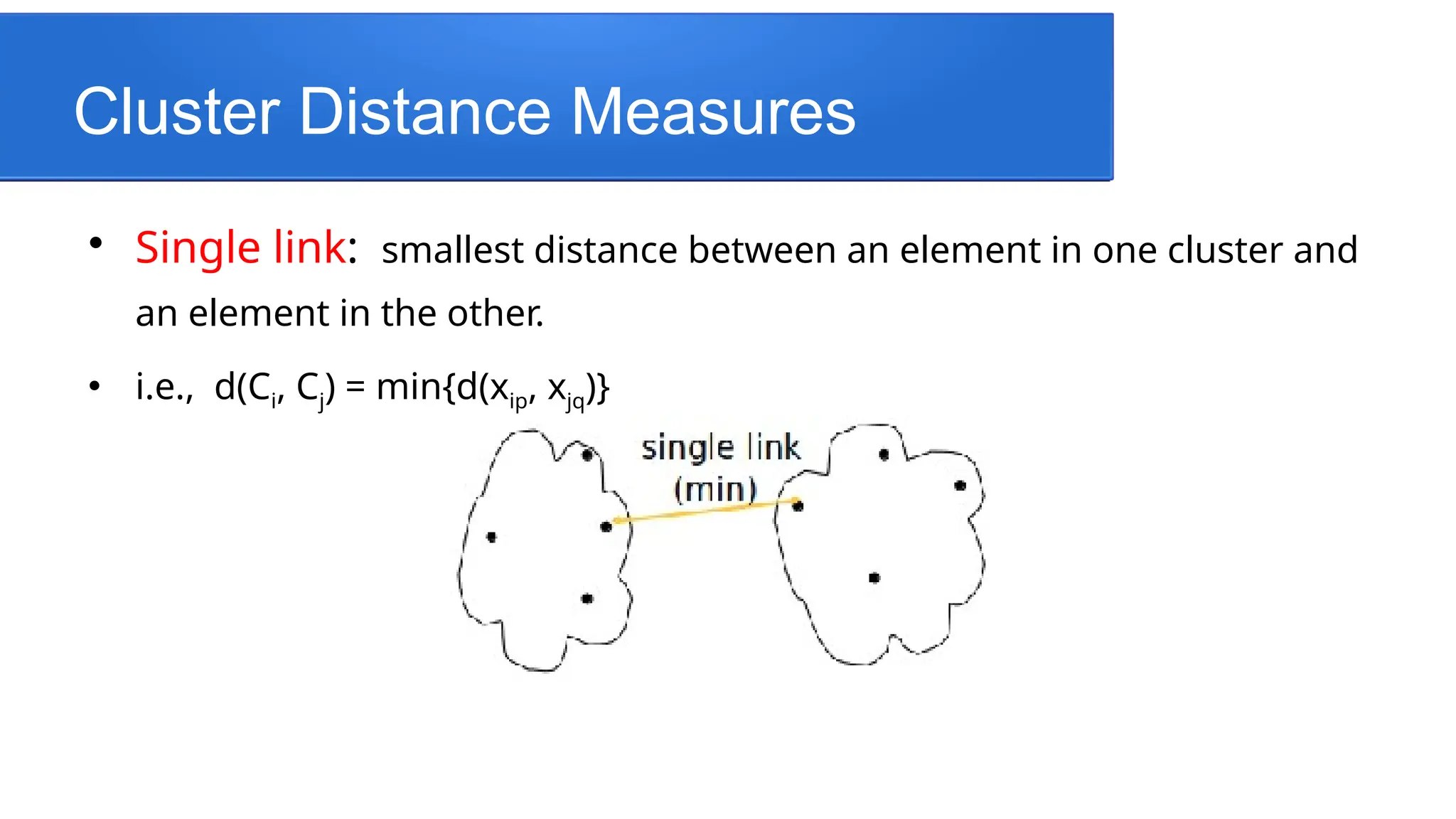
Singlelink: smallest distance between an element in one cluster and
an element in the other.
i.e., d(Ci, Cj) = min{d(xip, xjq)}
7.
Cluster Distance Measures
Completelink: largest distance between an element in one cluster
and an element in the other,
i.e., d(Ci, Cj) = max{d(xip, xjq)}
8.
Cluster Distance Measures
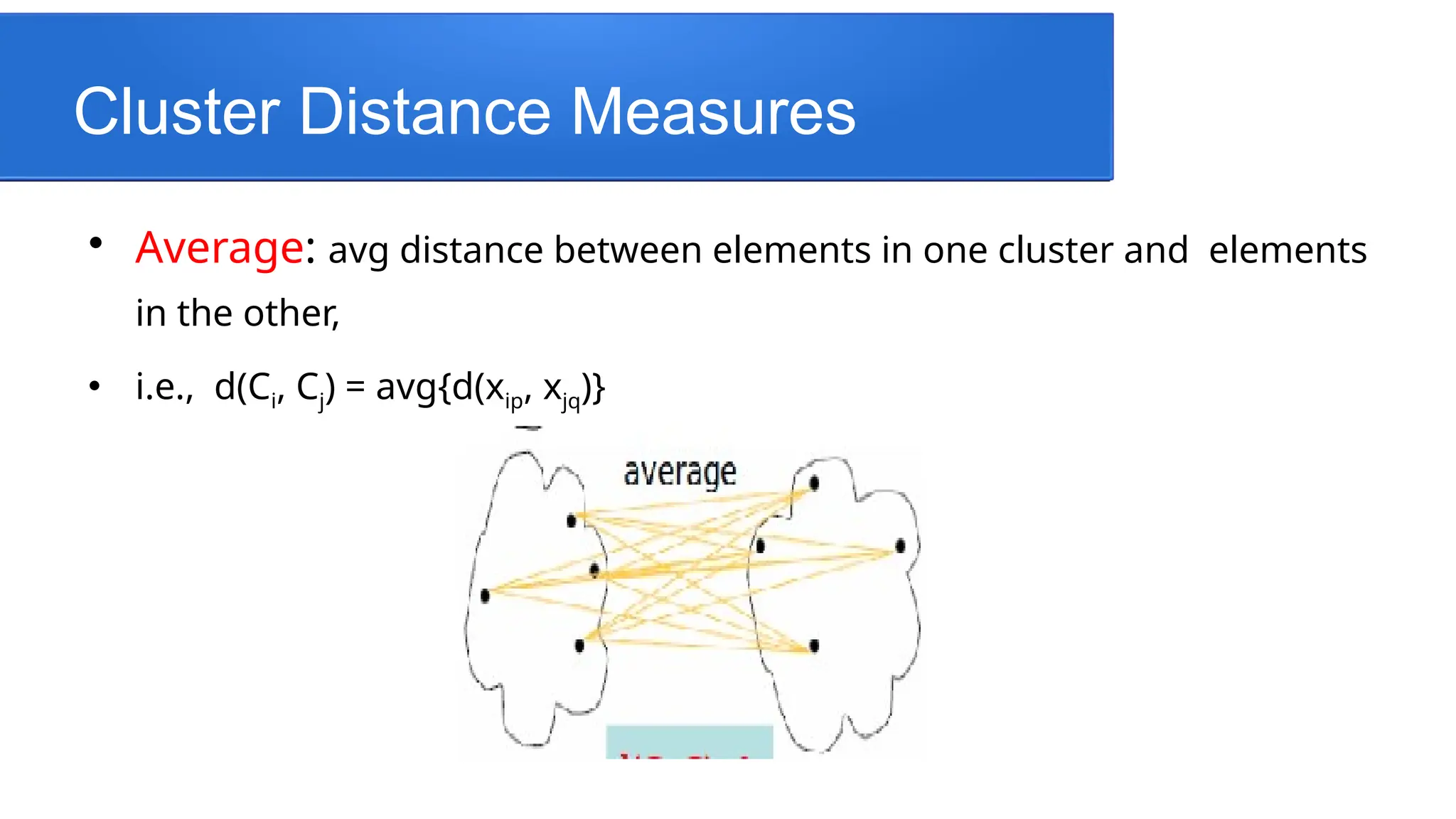
Average:avg distance between elements in one cluster and elements
in the other,
i.e., d(Ci, Cj) = avg{d(xip, xjq)}
9.
Cluster Distance Measures
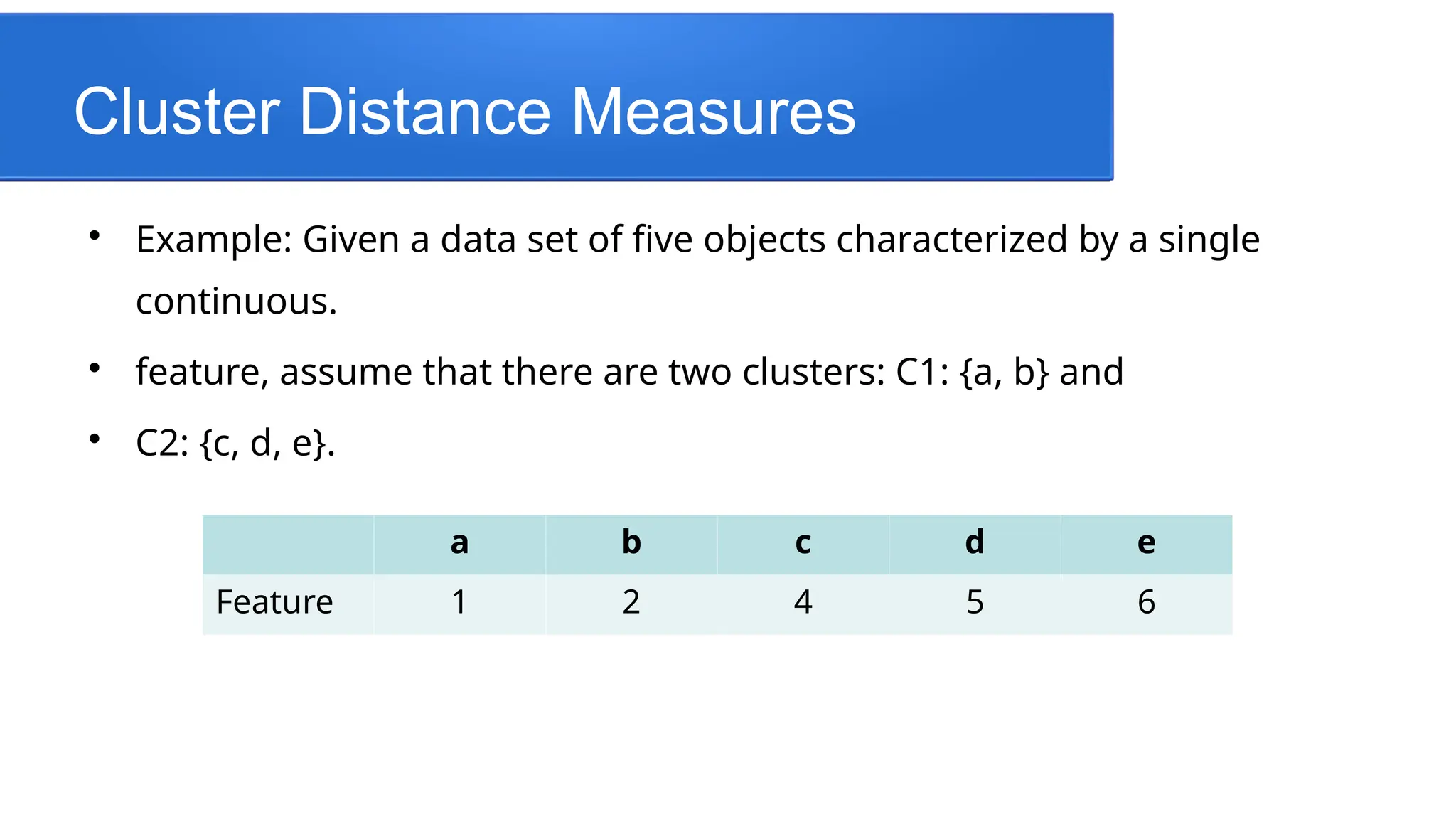
Example:Given a data set of five objects characterized by a single
continuous.
feature, assume that there are two clusters: C1: {a, b} and
C2: {c, d, e}.
a b c d e
Feature 1 2 4 5 6
10.
Cluster Distance Measures
1.Calculate the distance matrix.
a b c d e
a 0 1 3 4 5
b 1 0 2 3 4
c 3 2 0 1 2
d 4 3 1 0 1
e 5 4 2 1 0
11.
Cluster Distance Measures
2.Calculate three cluster distances between C1 and C2.
Single link
dist (C1 ,C2)=min{d(a,c),d(a,d),d (a,e),d (b,c),d(b,d) ,d (b,e)}
=min {3, 4, 5, 2, 3, 4}= 2
12.
Cluster Distance Measures
2.Calculate three cluster distances between C1 and C2.
Complete link
dist (C1 ,C2)=max {d (a,c),d(a,d),d(a,e) ,d(b,c),d (b,d),d(b,e)}
=max {3, 4, 5, 2, 3, 4}= 5
13.
Cluster Distance Measures
2.Calculate three cluster distances between C1 and C2.
Average:
dist (C1 ,C2)=
d (a,c)+d (a,d )+d (a,e)+d (b,c )+d ( b,d) +d ( b,e)
6
=
3+4 +5+2+3+4
6
=
21
6
=3 .5
14.
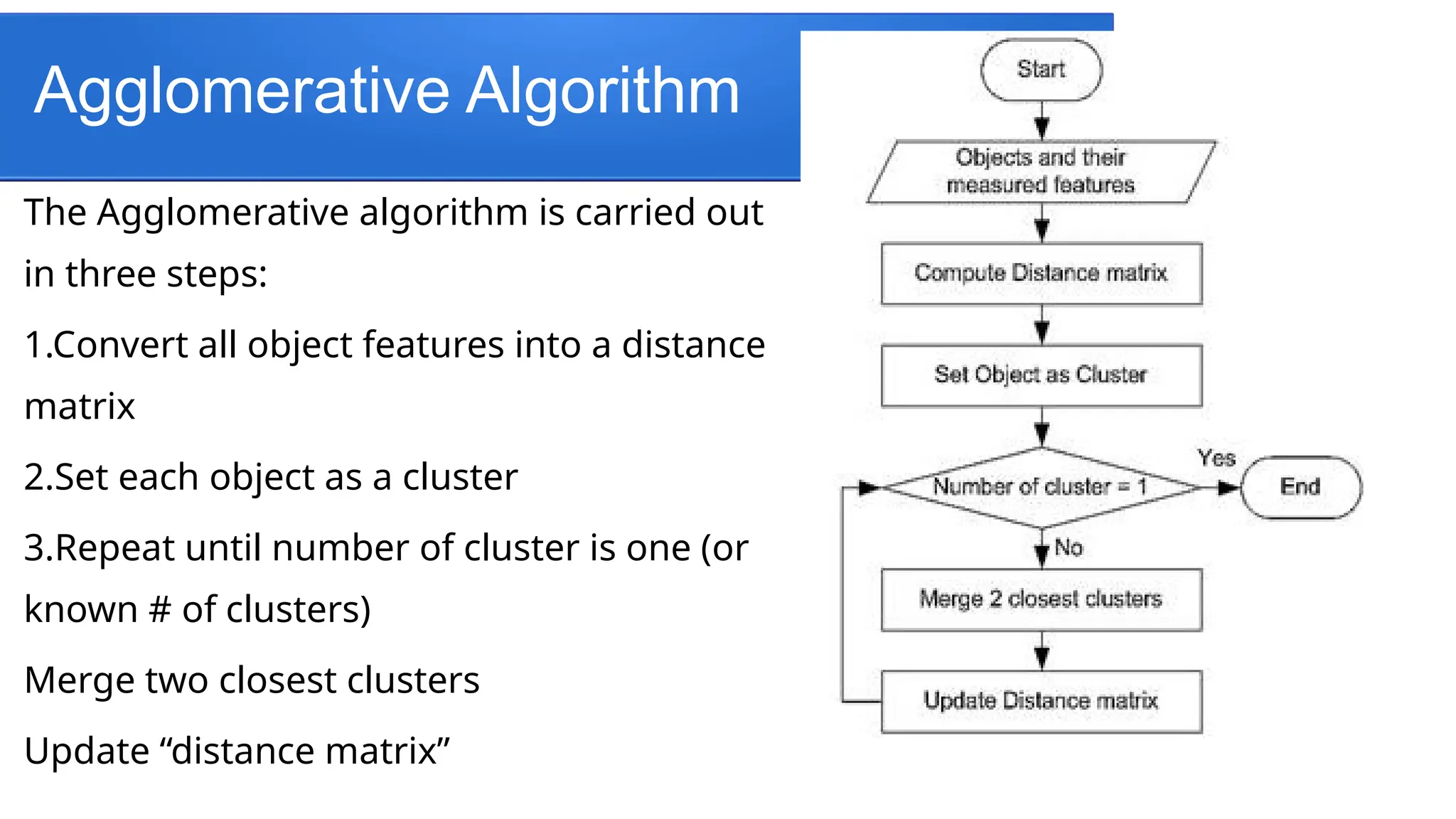
Agglomerative Algorithm
The Agglomerativealgorithm is carried out
in three steps:
1.Convert all object features into a distance
matrix
2.Set each object as a cluster
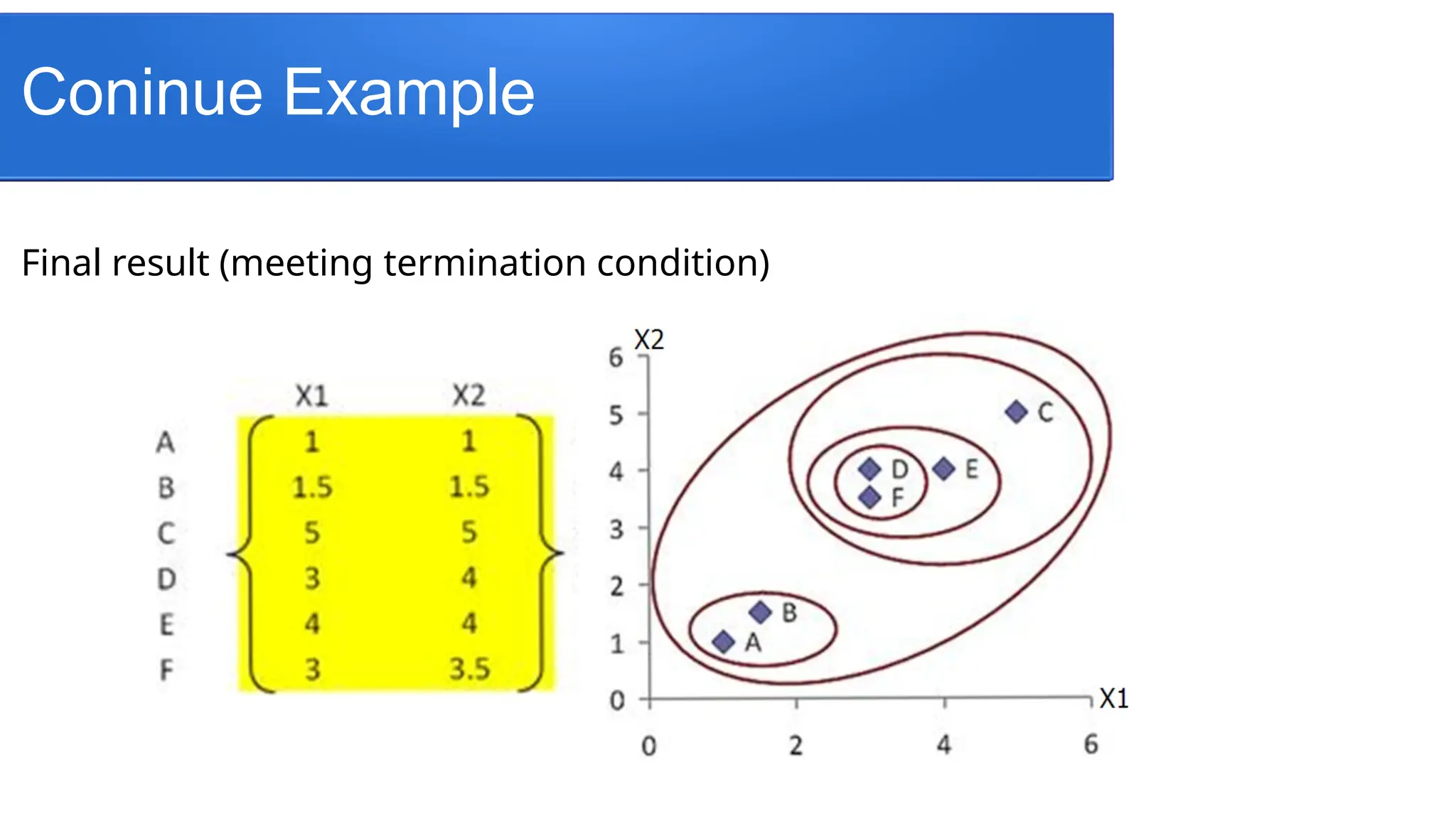
3.Repeat until number of cluster is one (or
known # of clusters)
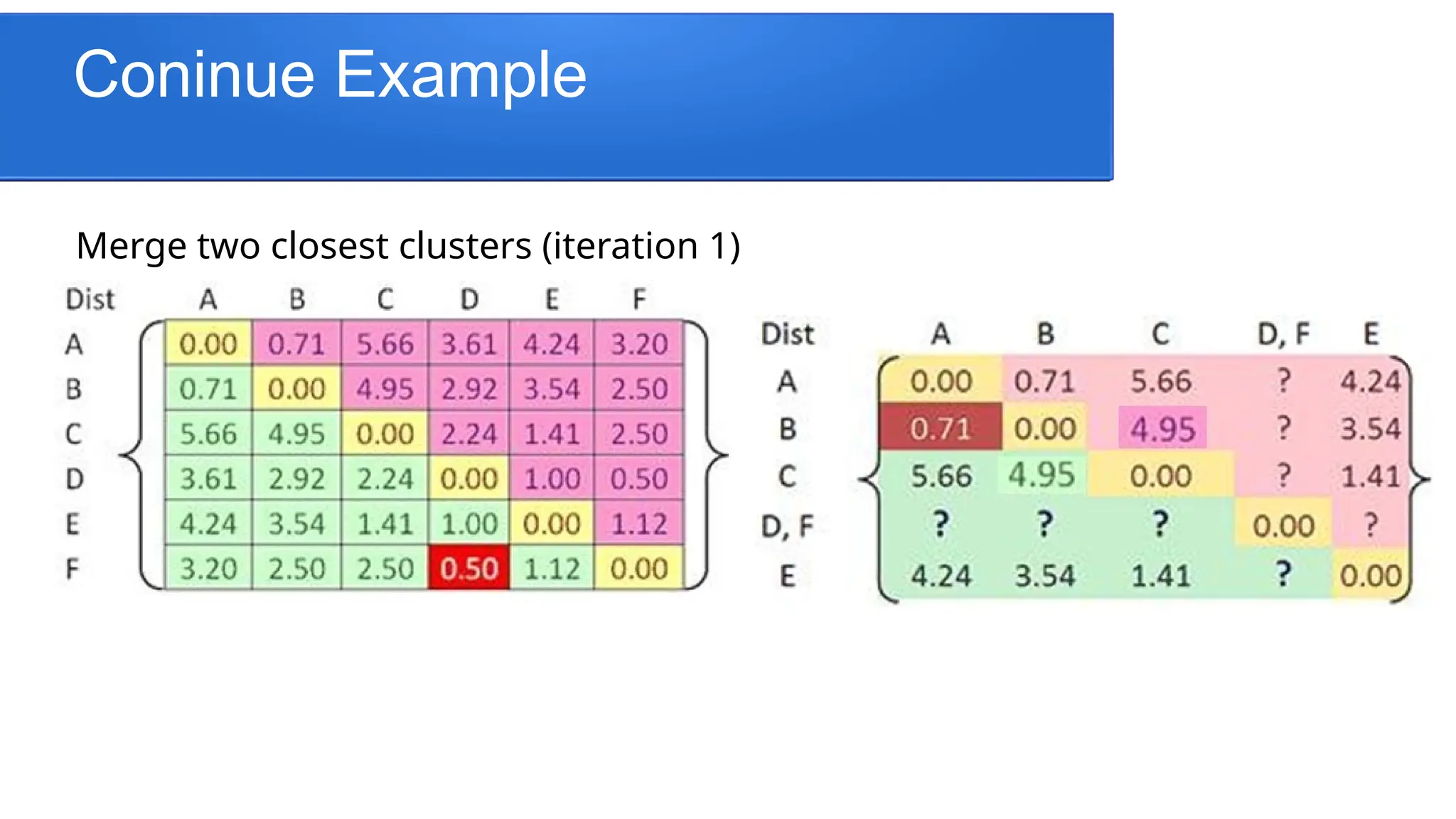
Merge two closest clusters
Update “distance matrix”
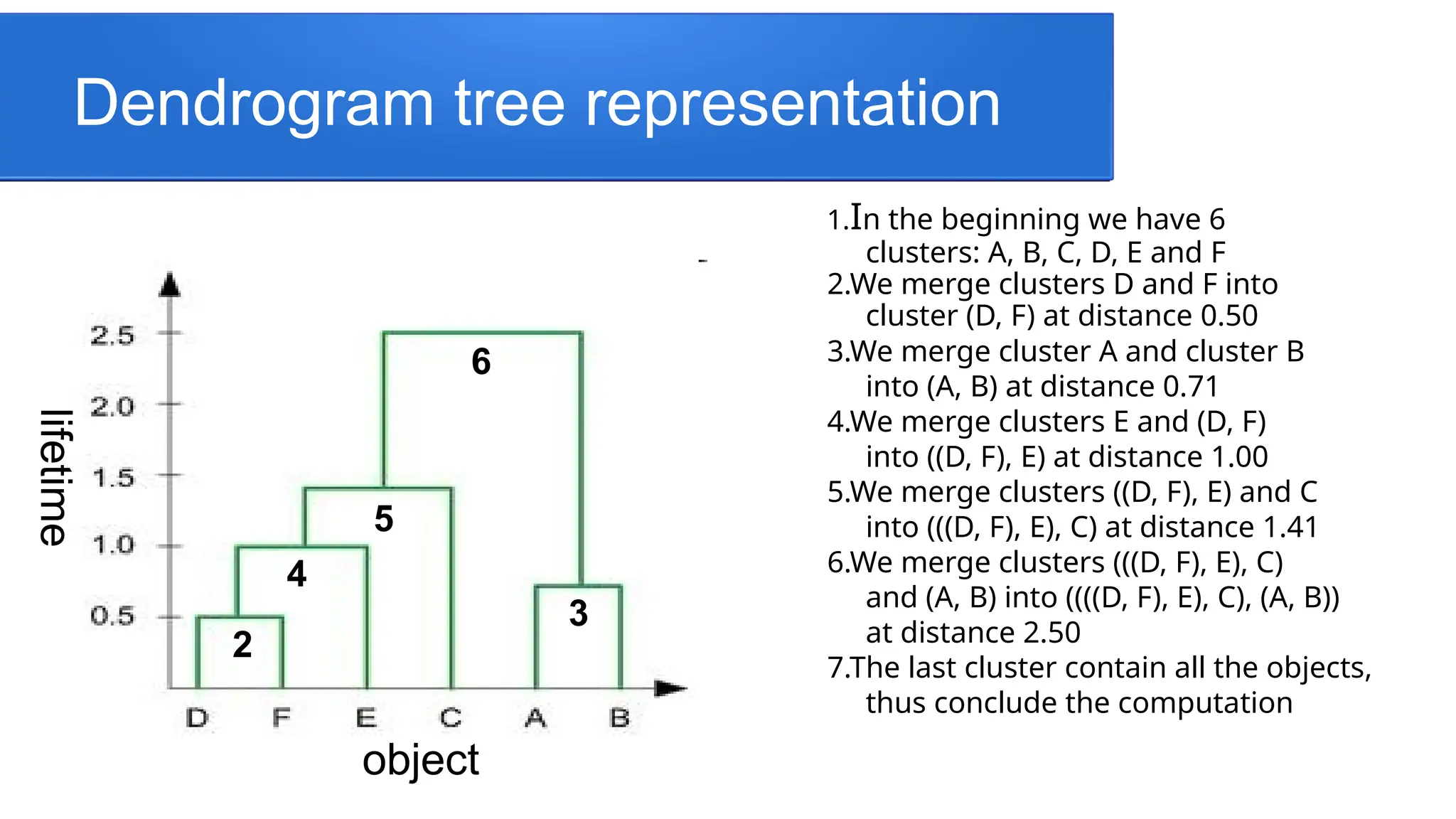
Dendrogram tree representation
1.Inthe beginning we have 6
clusters: A, B, C, D, E and F
2.We merge clusters D and F into
cluster (D, F) at distance 0.50
3.We merge cluster A and cluster B
into (A, B) at distance 0.71
4.We merge clusters E and (D, F)
into ((D, F), E) at distance 1.00
5.We merge clusters ((D, F), E) and C
into (((D, F), E), C) at distance 1.41
6.We merge clusters (((D, F), E), C)
and (A, B) into ((((D, F), E), C), (A, B))
at distance 2.50
7.The last cluster contain all the objects,
thus conclude the computation
2
3
4
5
6
object
lifetime
25.
Summary
Hierarchical algorithm isa sequential clustering algorithm.
Use distance matrix to construct a tree of clusters (dendrogram).
Hierarchical representation without the need of knowing # of clusters (can set
termination condition with known # of clusters).