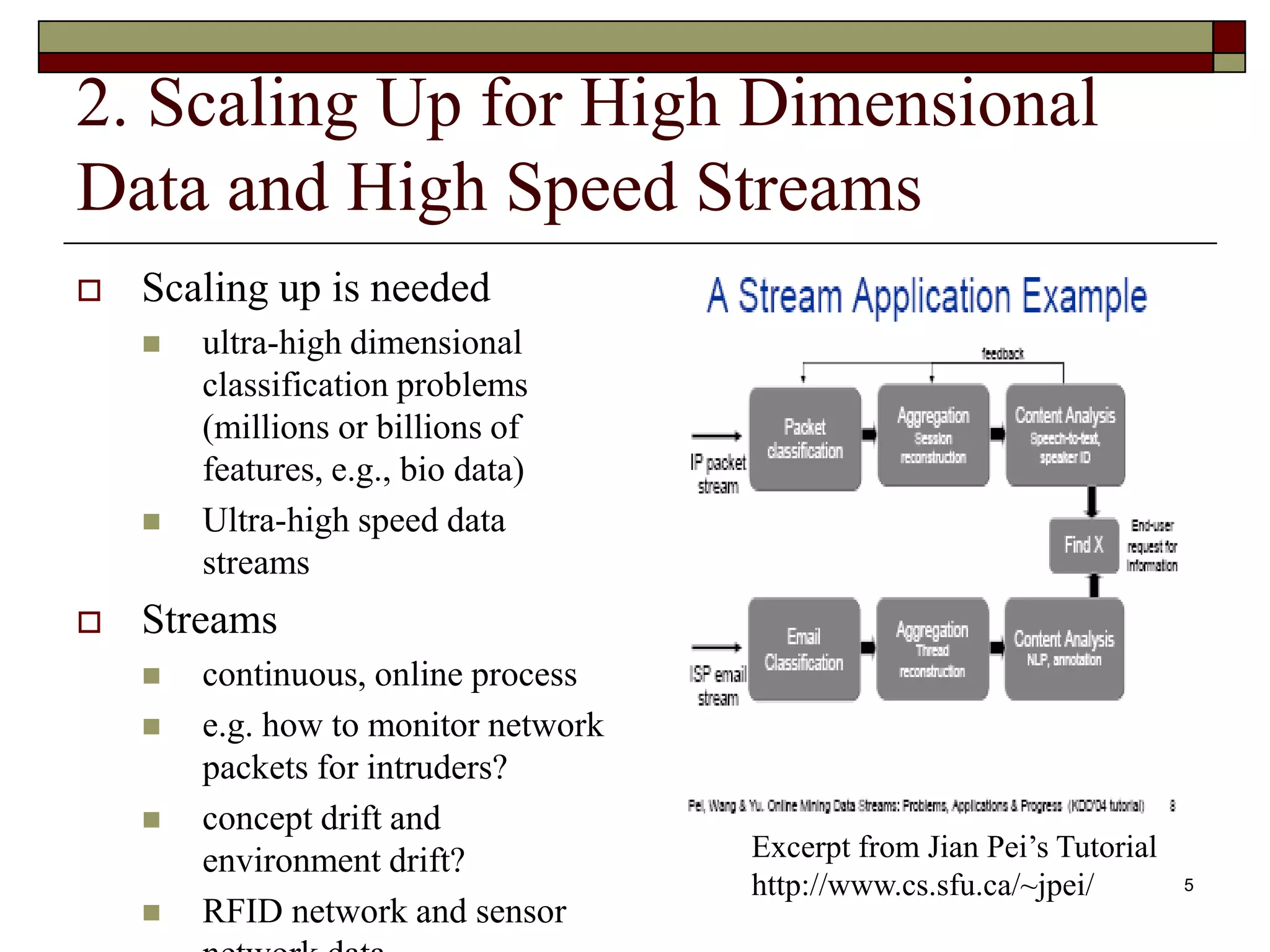
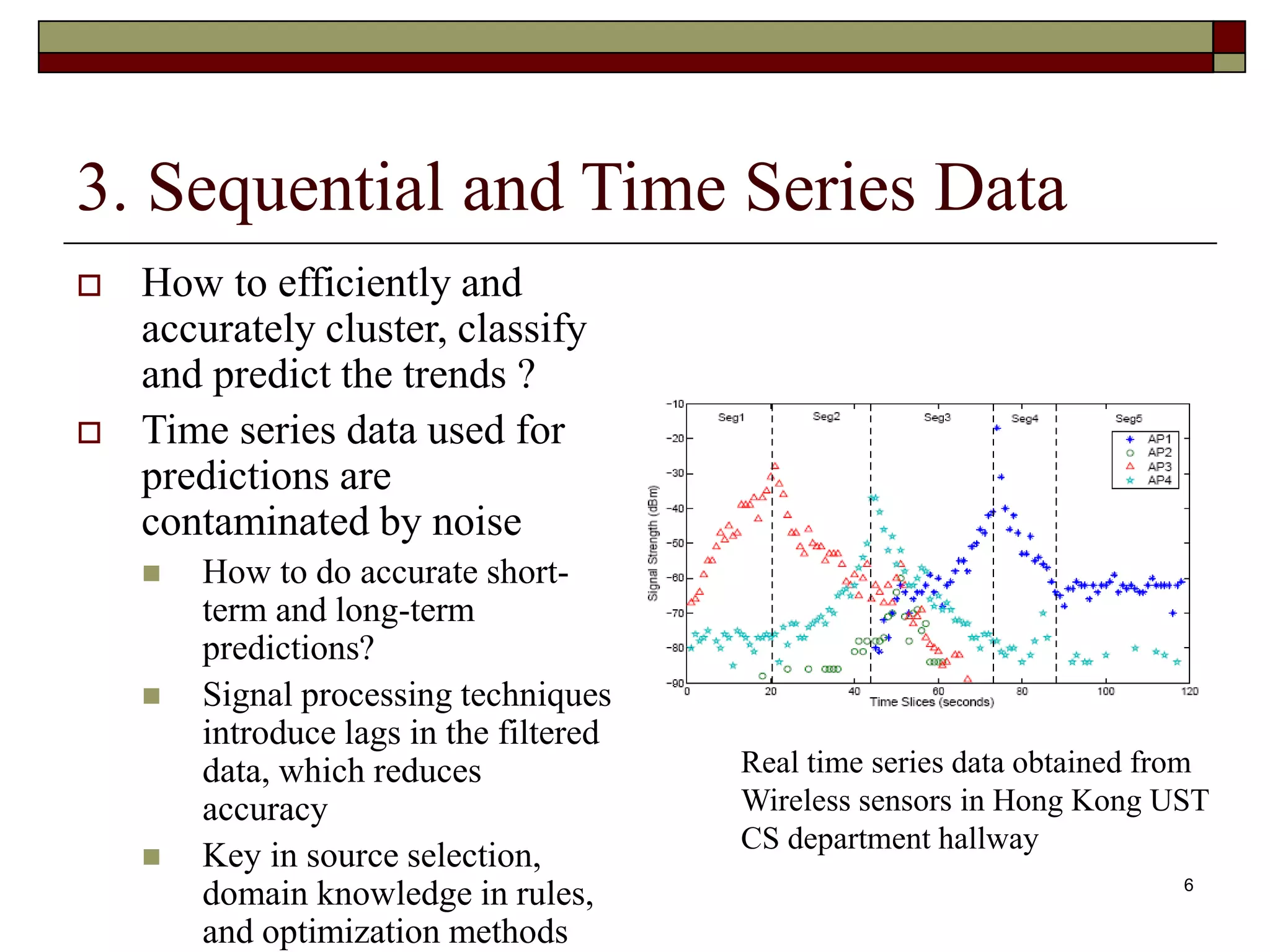
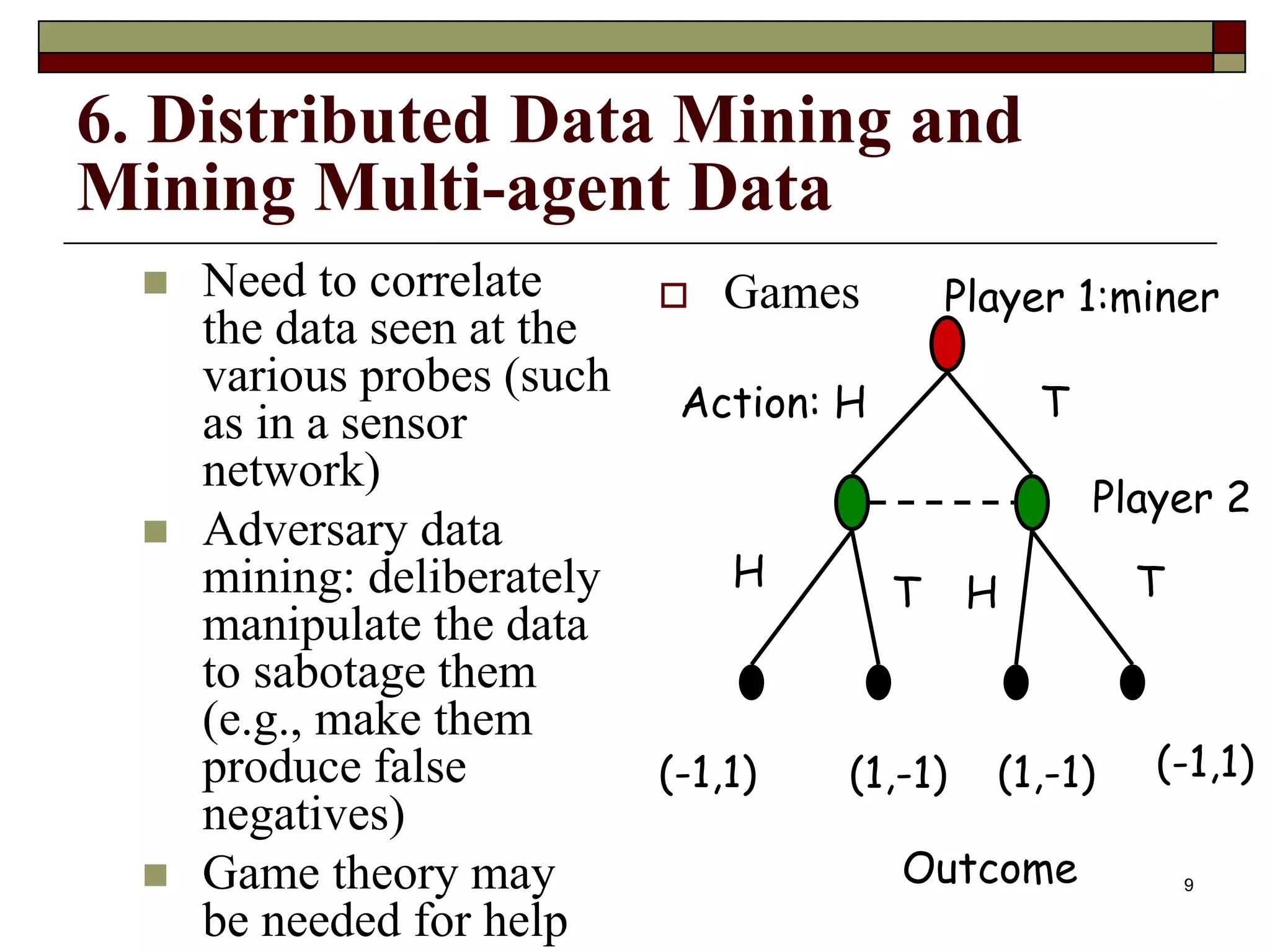
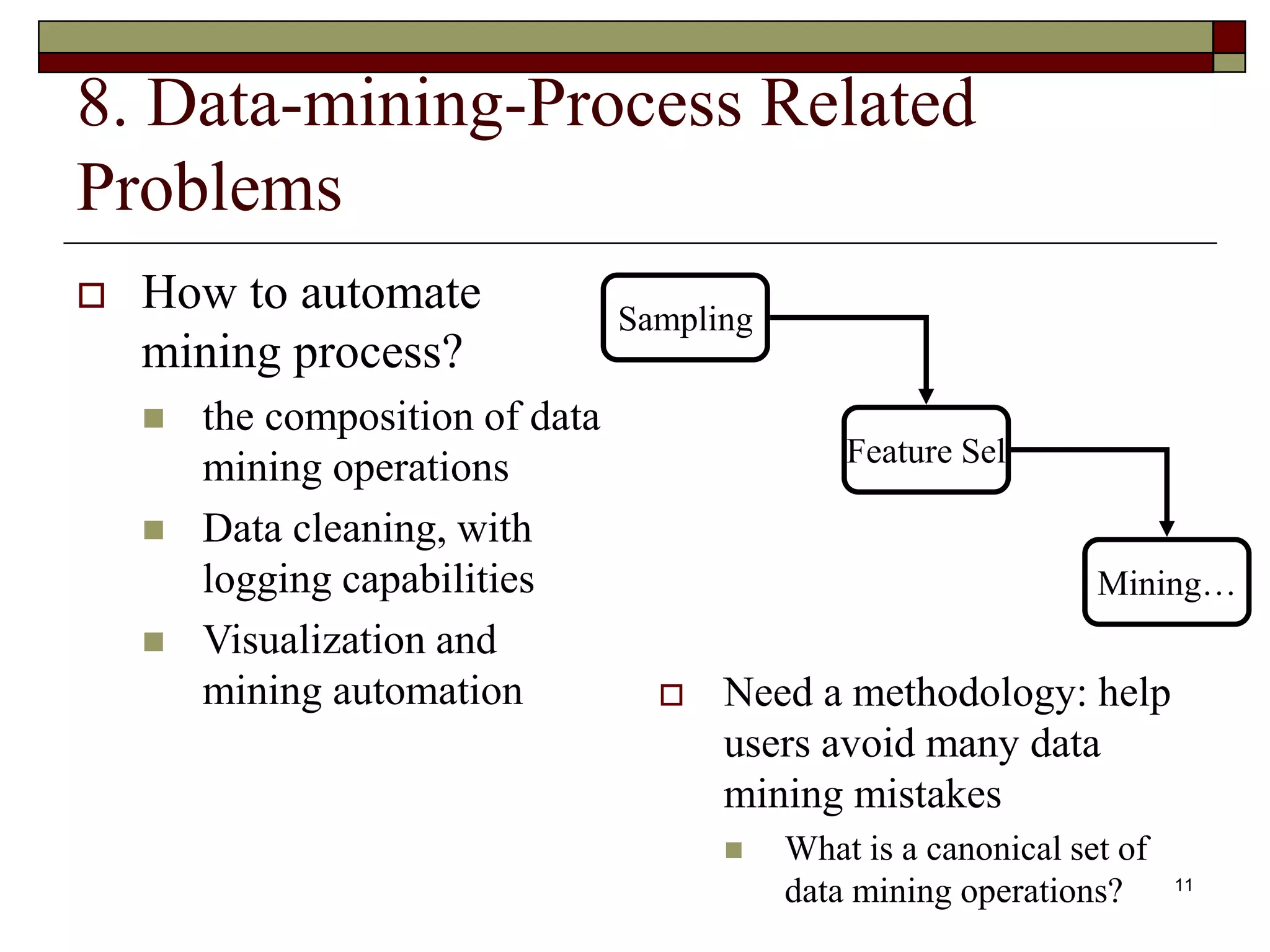
This document outlines 10 challenging problems in data mining research as identified by experts in the field. The problems are: 1) developing a unifying theory of data mining, 2) scaling up for high dimensional and high speed streaming data, 3) mining sequence and time series data, 4) mining complex knowledge from complex data, 5) data mining in network settings, 6) distributed data mining and multi-agent data, 7) data mining for biological and environmental problems, 8) automating the data mining process, 9) ensuring security, privacy and data integrity, and 10) dealing with non-static, unbalanced and cost-sensitive data. A companion survey paper on these challenges is forthcoming.























































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)






