Parallel Processing & Pipelining in Computer Architecture_Prof.Sumalatha.pptx
Parallel processing involves executing multiple programs or tasks simultaneously. It can be implemented through hardware and software means in both multiprocessor and uniprocessor systems. In uniprocessors, parallelism is achieved through techniques like pipelining instructions, overlapping CPU and I/O operations, using cache memory, and multiprocessing through time-sharing. Pipelining helps execute instructions in an overlapped fashion to improve efficiency compared to non-pipelined processors. Parallel computers break large problems into smaller parallel tasks executed simultaneously on multiple processors. Types of parallel computers include pipeline computers, array processors, and multiprocessor systems.
Introduction to computer architecture with emphasis on parallel processing and its definition.
Description of the four phases of computer operating systems advancing in parallelism.
Overview of a uniprocessor system with central components and architecture examples of VAX-11/780.
Detailed architecture of IBM System 370 uniprocessor with memory organization and I/O operations.
Methods to promote parallelism via hardware and software mechanisms in uniprocessor computing.
Historical evolution from single ALU to multiple functional units in machines like CDC-6600.
Explanation of pipelining within CPUs and its advantages in process execution with diagrams. Explanation of parallel computer structure types and the use of pipelining for efficiency in execution.
Parallel Processing
• Parallelprocessing is an efficient form of information processing
which emphasizes the exploitation of concurrent events in the
computing process.
• Parallel Processing demands concurrent execution of many
programs in the computer.
• Concurrency implies parallelism, simultaneity, and pipelining.
3.
Introduction to Parallelismin Uniprocessor
System
• From an operating point of view, computer systems have improved
chronologically in four phases:
• batch processing
• multiprogramming
• time-sharing
• multiprocessing
• In these four operating modes, the degree of parallelism increase
sharply from phase to phase.
4.
Introduction to Parallelismin Uniprocessor
System Contd…
• We define parallel processing as an efficient form of information processing that emphasizes
the exploitation of concurrent events in the computing process.
• Parallel Processing demands the concurrent execution of many programs in the computer.
• Concurrency implies parallelism, simultaneity, and pipelining.
• The highest level of parallel processing is conducted among multiple jobs or programs through
multiprogramming, time-sharing, and multiprocessing.
• Parallel processing can be challenged in four programmatic levels:
1.Job or program level – the highest level of parallel processing conducted among multiple jobs or
programs
2. Task or procedure level – next higher level parallel processing conducted among procedures or
tasks within the same program
3. Inter-instruction level- The third level to exploit concurrency among multiple instructions
4. Intra-instruction level-Finally concurrent operations within each instruction
5.
Basic Uniprocessor Architecture
•A typical uniprocessor computer consists of three major
components the main memory, the CPU (Central Processing Unit),
and the I/O(Input-Output) subsystem.
• There are two architectures of commercially available uniprocessor
computers to show the relation between three subsystems
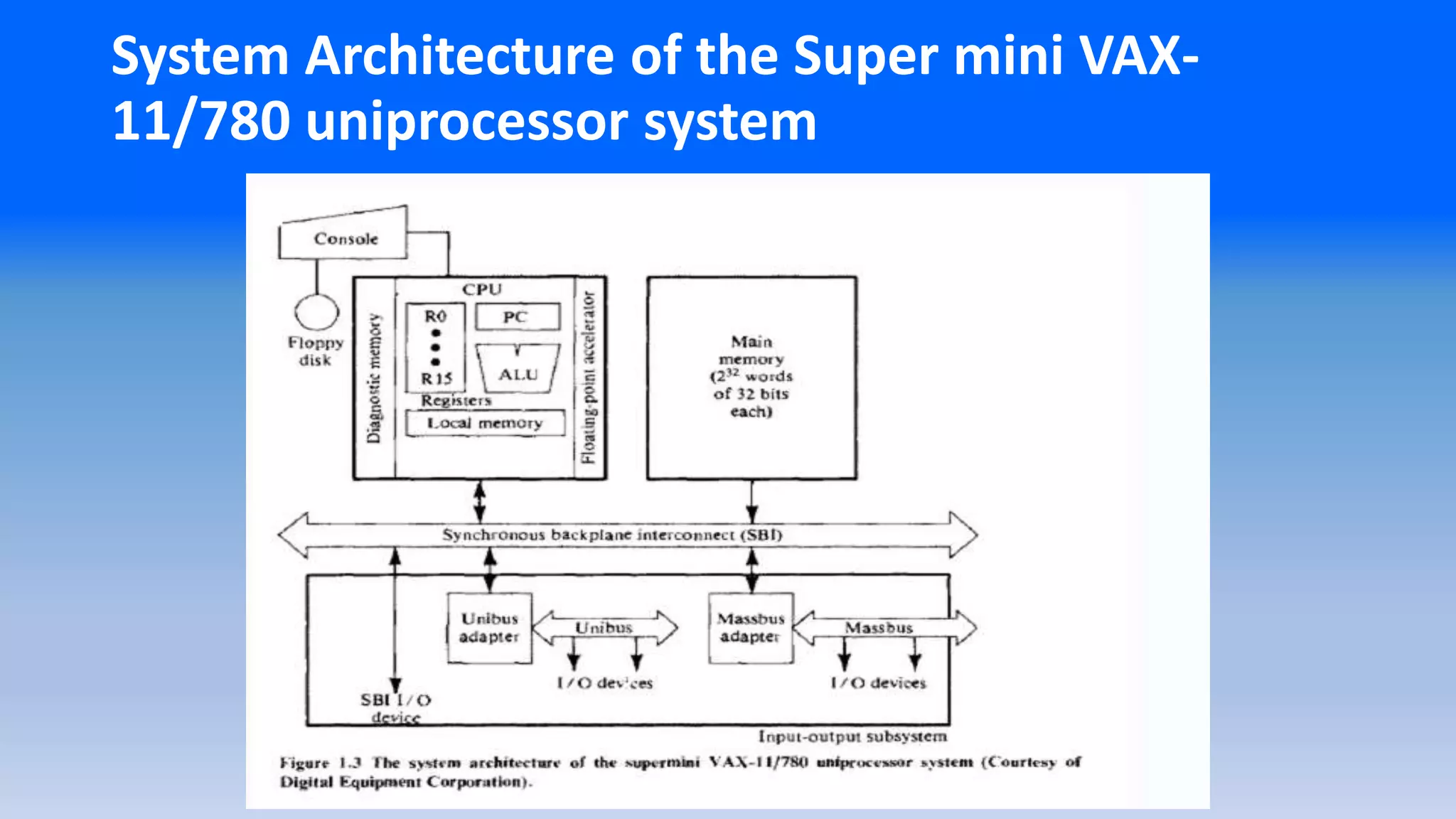
System Architecture ofthe Super mini VAX-
11/780 uniprocessor system Contd…
• There are 16, 32-bit general purpose registers one of which is a Program
Counter (PC).
• There is also a special CPU status register containing about the current
state of the processor is executed.
• The CPU contains an ALU with an optional Floating-point accelerator and
some local cache memory with an optional diagnostic memory.
• Floating-point accelerator (FPA) -A device to improve the overall
performance of a computer by removing the burden of performing
floating-point arithmetic from the central processor.
• optional diagnostic memory –checks the errors.
8.
• The CPUcan be intervened by the operator through the console
connected to a floppy disk.
• The CPU, the main memory( 2^32 words of 32-bit each), and the I/O
subsystem are all connected to a common bus, the synchronous
backplane interconnection(SBI).
• Through this bus, all I/O devices can communicate with each other
with the CPU or with the memory.
• I/O devices can be connected directly to the SBI through the unibus
and its controller or through a mass bus and its controller
System Architecture of the Super mini VAX-
11/780 uniprocessor system Contd…
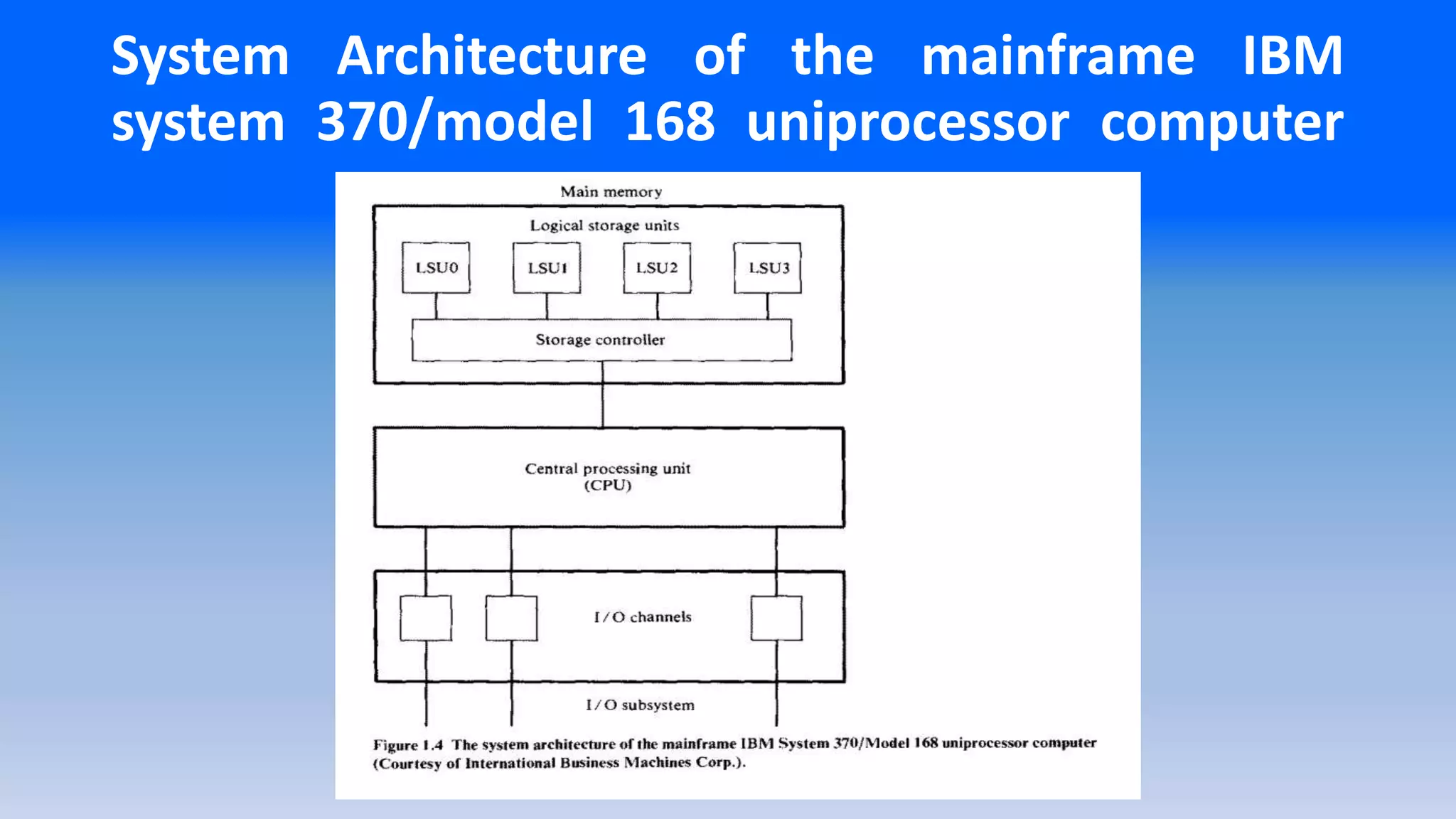
•The CPU containsthe instruction decoding and execution units as well
as the cache.
•Main memory is divided into four units referred to as logical storage
units (LSU) that are four ways interleaved.
•The storage controller provides multiport Connections between the
CPU and the four LSUs.
•Peripherals are connected to the system via high-speed I/O channels
which operate asynchronously with the CPU
System Architecture of the mainframe IBM
system 370/model 168 uniprocessor computer
Contd…
PARALLELLISM IN UNIPROCESSORSYSTEM
• A number of parallel processing mechanisms have been developed in
uniprocessor computers.
• We identify them in the following six categories:
1.Multiplicity of functional units
2.Parallelism and pipelining within the CPU
3.Overlapped CPU and I/O operations
4.Use of a hierarchical memory system
5.Balancing of subsystem bandwidths
6.Multiprogramming and time sharing
13.
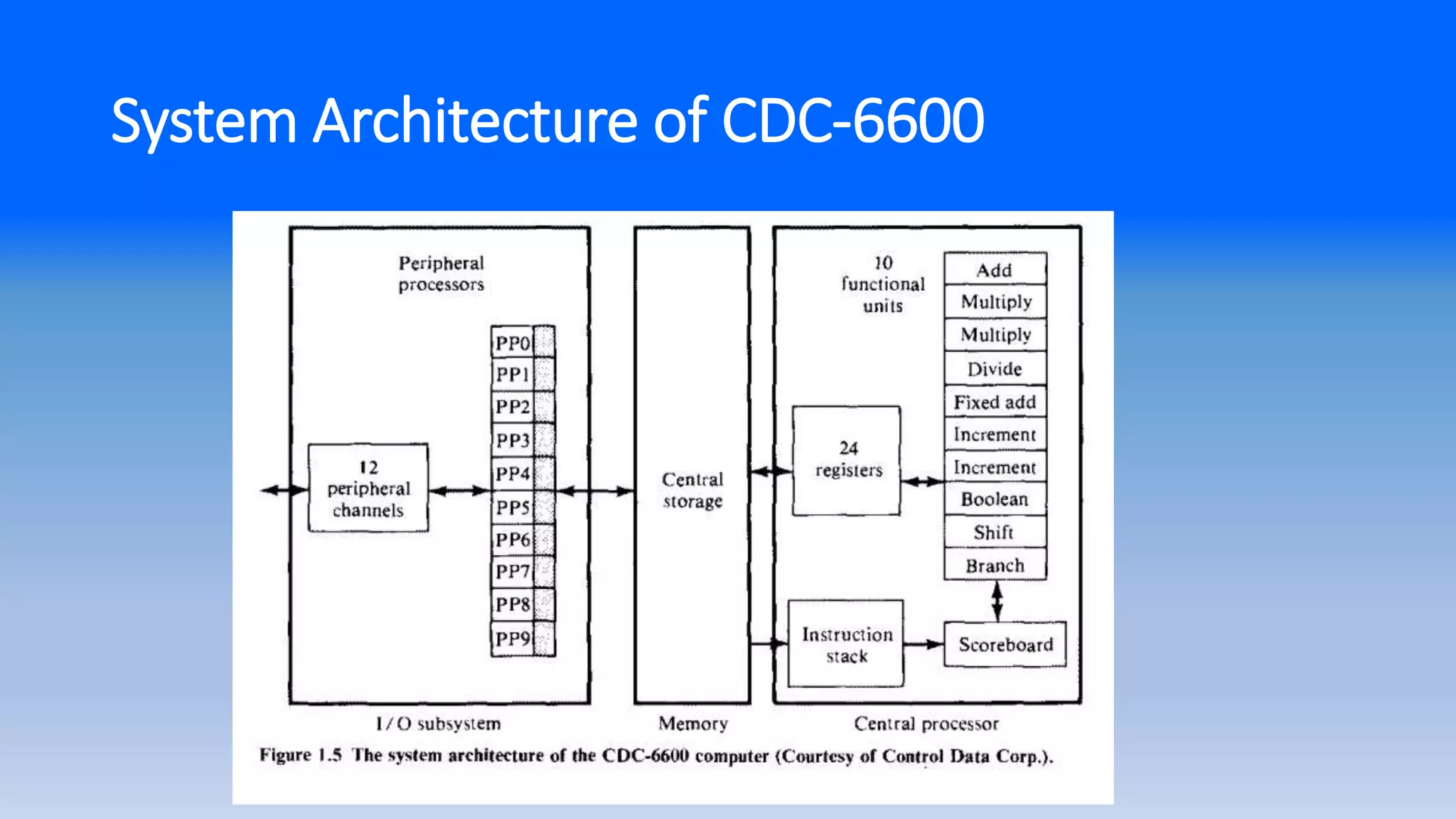
Multiplicity of FunctionalUnits
• Early computers
- one ALU that performs one operation at a time
- Slow processing
• Multiple and specialized functional units.
- operate in parallel.
- two parallel execution units (fixed and floating point
arithmetic) in
CDC-6600
→10 functional units
Parallelism and pipeliningwithin the CPU
• Instead of serial bit adders, parallel adders are used in almost ALUs
• Use of High-speed multiplier recoding and convergence division
• Sharing of hardware resources for functions of multiply and divide
• Various phases of instructions executions (instruction fetch ,
decode, operand fetch, arithmetic logic execution, store result) are
pipelined
• For overlapped instruction executions, instruction prefetch and
buffering techniques have been developed.
16.
Overlapped CPU andI/O operations
• I/O operations are performed simultaneously with CPU
computations by using separate I/O controllers, channels, or I/O
processors.
• DMA channel can be used for direct transfer of data between main
memory and I/O devices
17.
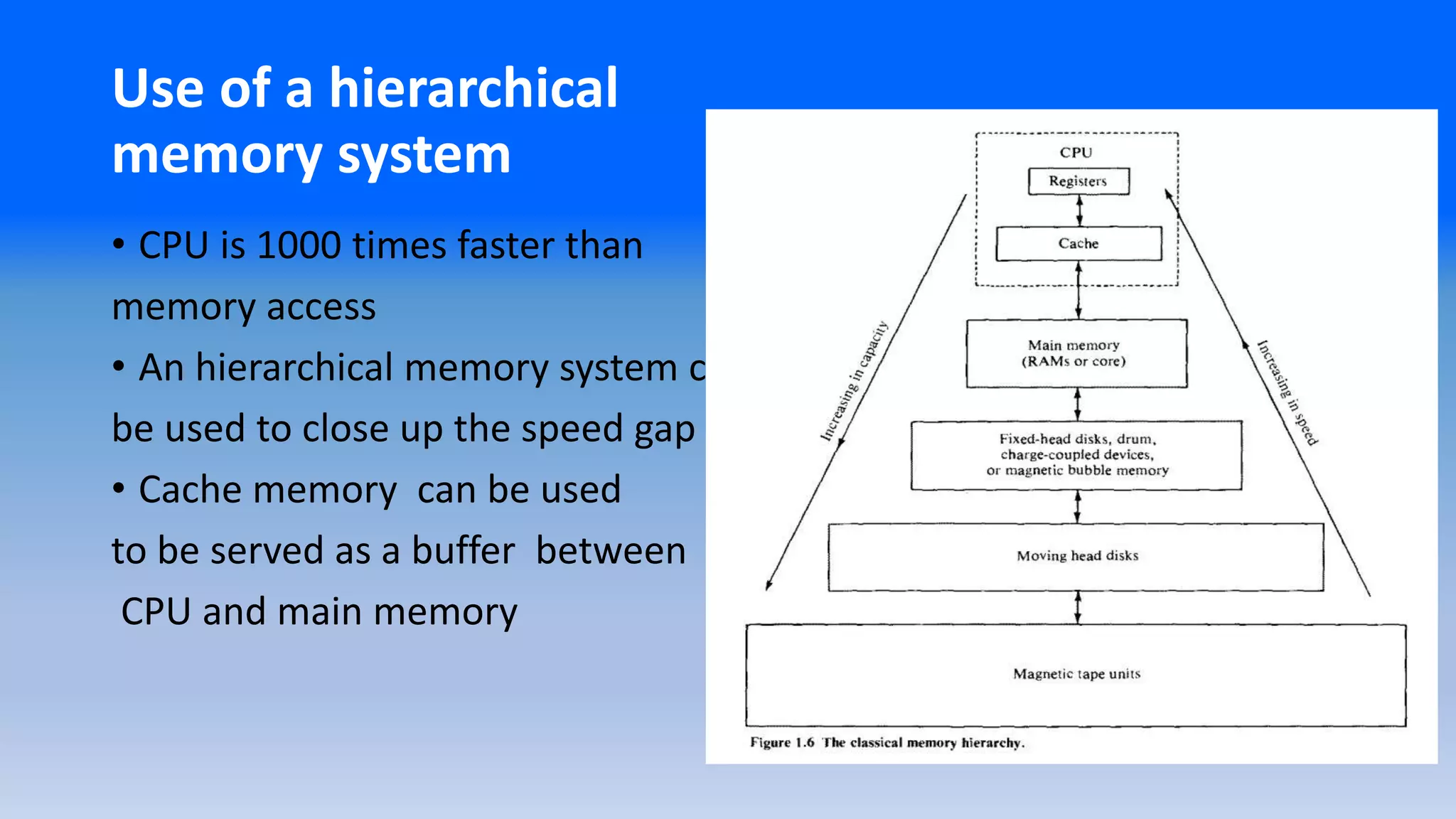
Use of ahierarchical
memory system
• CPU is 1000 times faster than
memory access
• An hierarchical memory system can
be used to close up the speed gap
• Cache memory can be used
to be served as a buffer between
CPU and main memory
18.
Balancing of subsystembandwidths
• CPU is the fastest unit in computer.
• The bandwidth of a system is defined as the number of operations performed per unit time.
• In case of main memory the memory bandwidth is measured by the number of words that can
be accessed per unit time.
• Relationship b/w BWs
•
19.
Balancing of subsystembandwidths
Bandwidth Balancing Between CPU and Memory
• The speed gap between the CPU and the main memory can be closed up by using
fast cache memory between them.
• A block of memory words is moved from the main memory into the cache so that
immediate instructions can be available most of the time from the cache.
Bandwidth Balancing Between Memory and I/O Devices
• Input-output channels with different speeds can be used between the slow I/O
devices and the main memory.
• The I/O channels perform buffering and multiplexing functions to transfer the data
from multiple disks into the main memory by stealing cycles from the CPU.
20.
Parallel Computer Structures
•A parallel computer is a kind of computer structure where a large
complex problem is broken into multiple small problems which are
then executed simultaneously by several processors. We often
consider this as parallel processing.
• It is divided into three
1.Pipeline Computer
2.Array Processors
3.Multiprocessor Systems
21.
Pipeline Computer
• Pipelinecomputers leverage parallel computing by overlapping the
execution of one process with another process.
• If we consider executing a small program that has a set of instructions
then we can categorize the execution of the entire program in four steps
that must be repeated continuously till the last instruction in the
program gets executed.
• The four steps we mentioned above are instruction fetching (IF),
instruction decoding (ID), operand fetch (OF), and instruction execution
(IE).
• Each instruction of the program is fetched from the main memory, it is
decoded by the processor, and the operands mentioned in the
instructions that are required for the execution of instruction are
fetched from the main memory, and at last, the instruction is executed.
22.
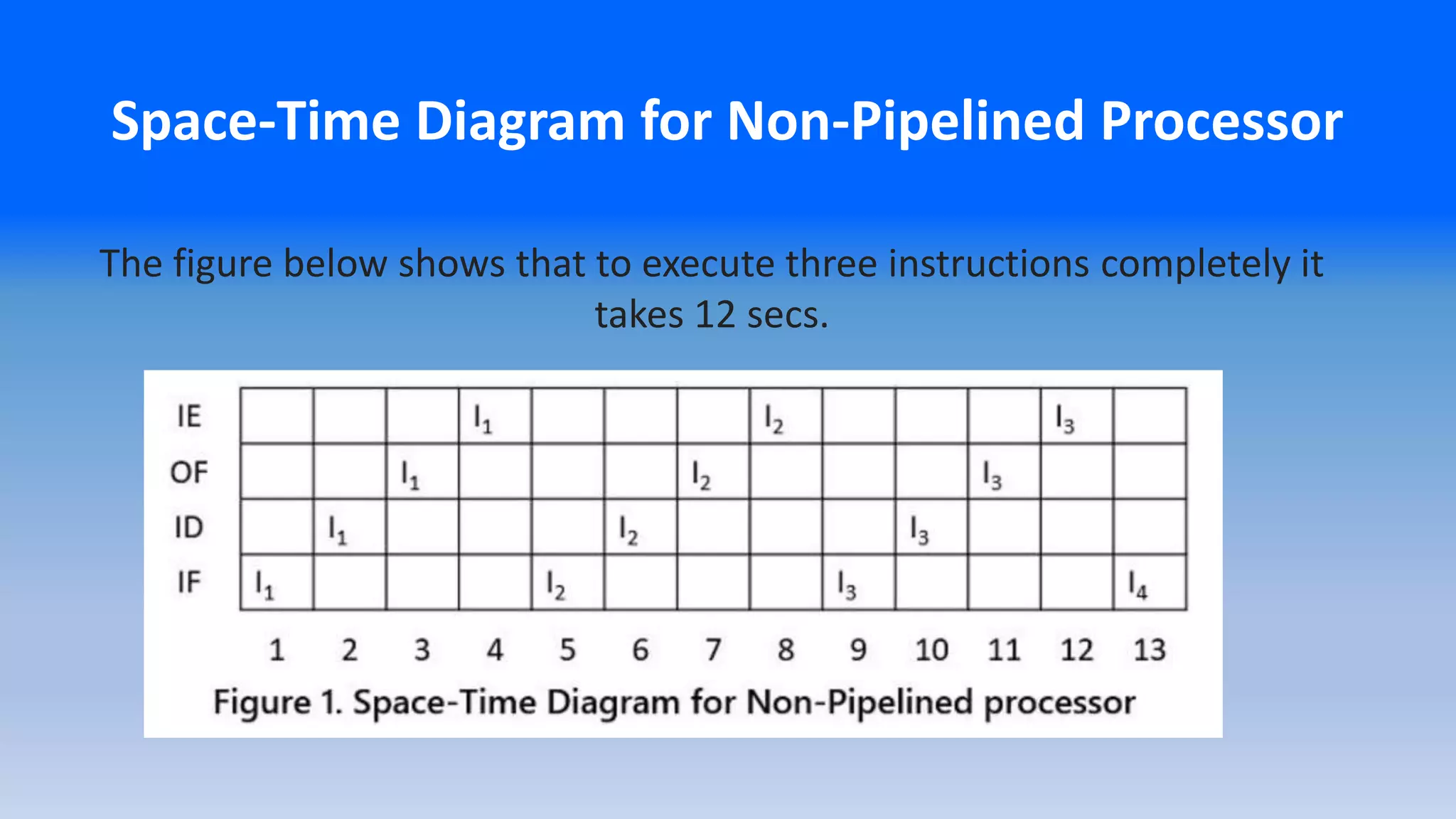
Space-Time Diagram forNon-Pipelined Processor
The figure below shows that to execute three instructions completely it
takes 12 secs.
23.
• And ifwe implement pipelining then instruction will be executed in an
overlapped fashion. As you can see that the four instructions can be
executed in 7 sec.
• Pipeline computer synchronizes operations of all stages under a
common clock. Hence, we can say that executing instructions in
pipelined fashion is more efficient.
Space-Time Diagram for Non-Pipelined Processor
Contd…