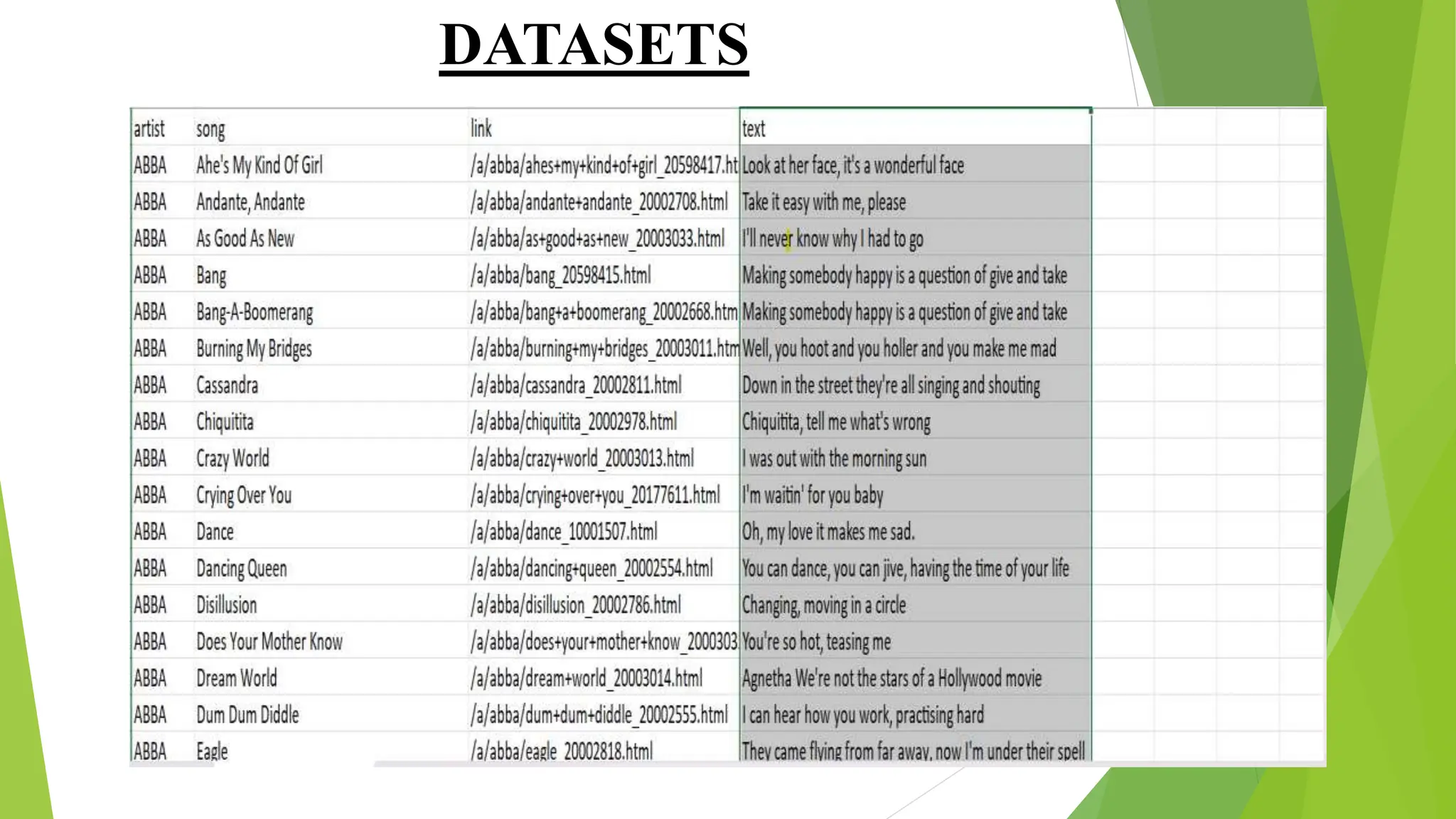
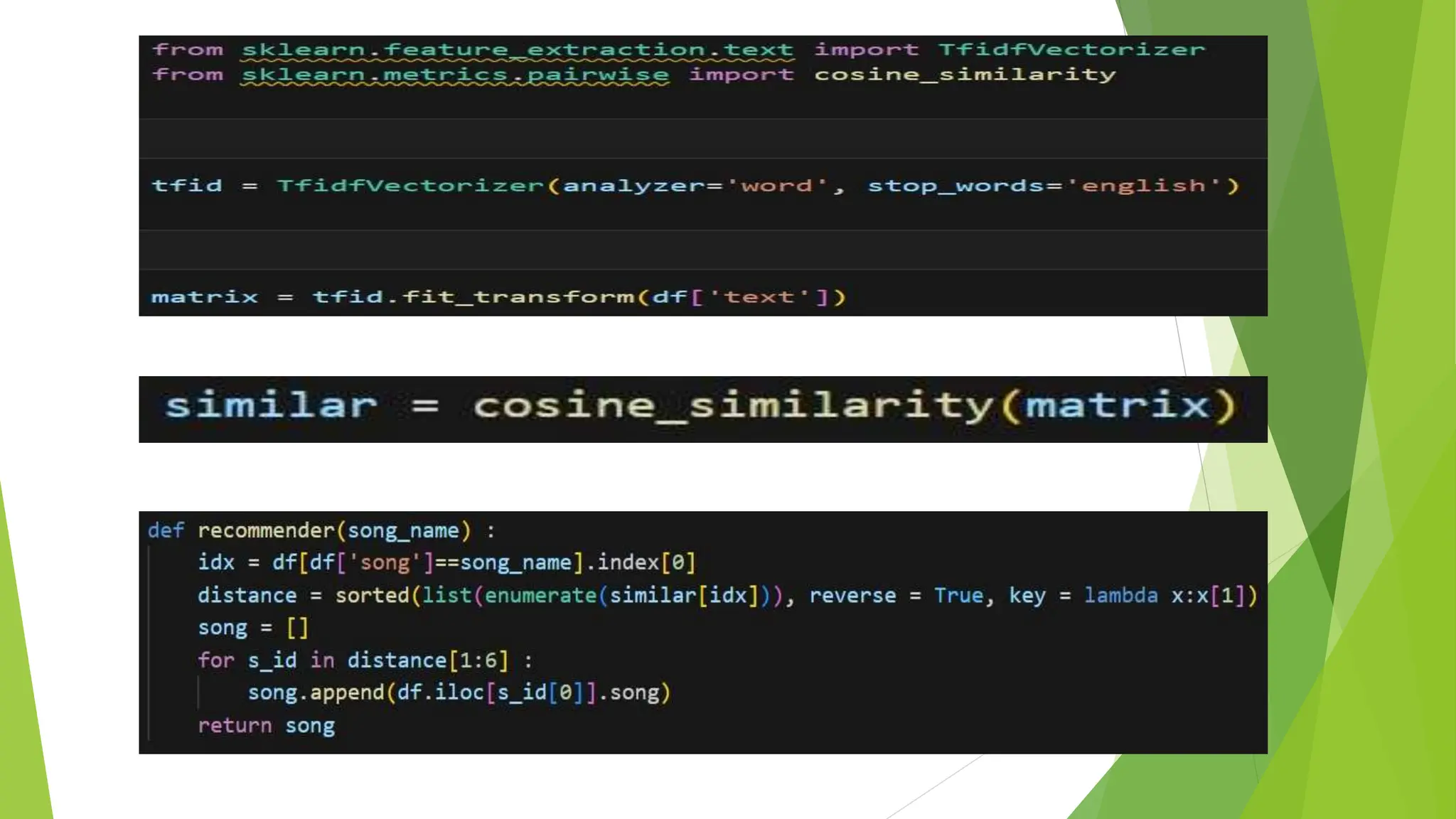
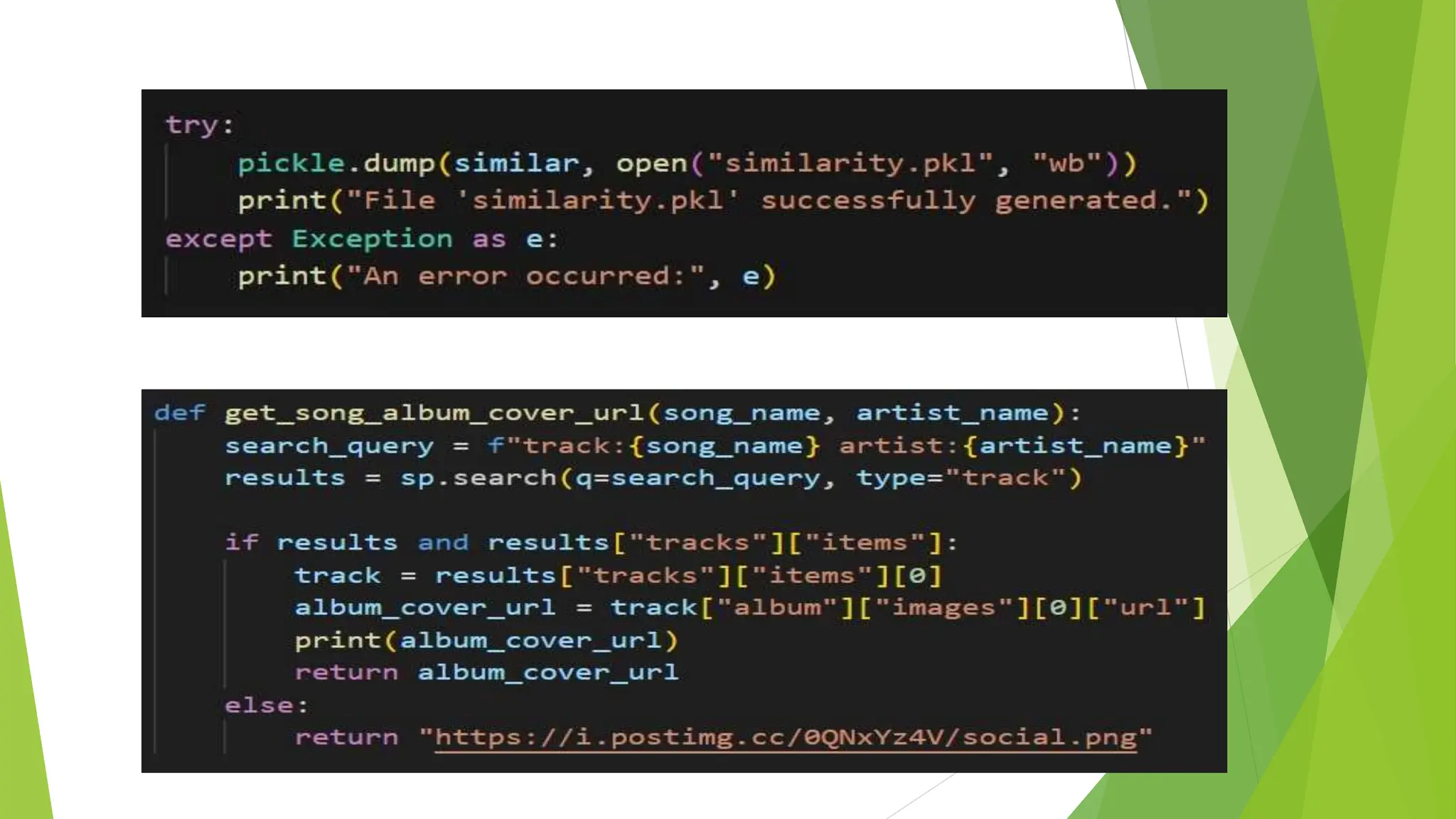
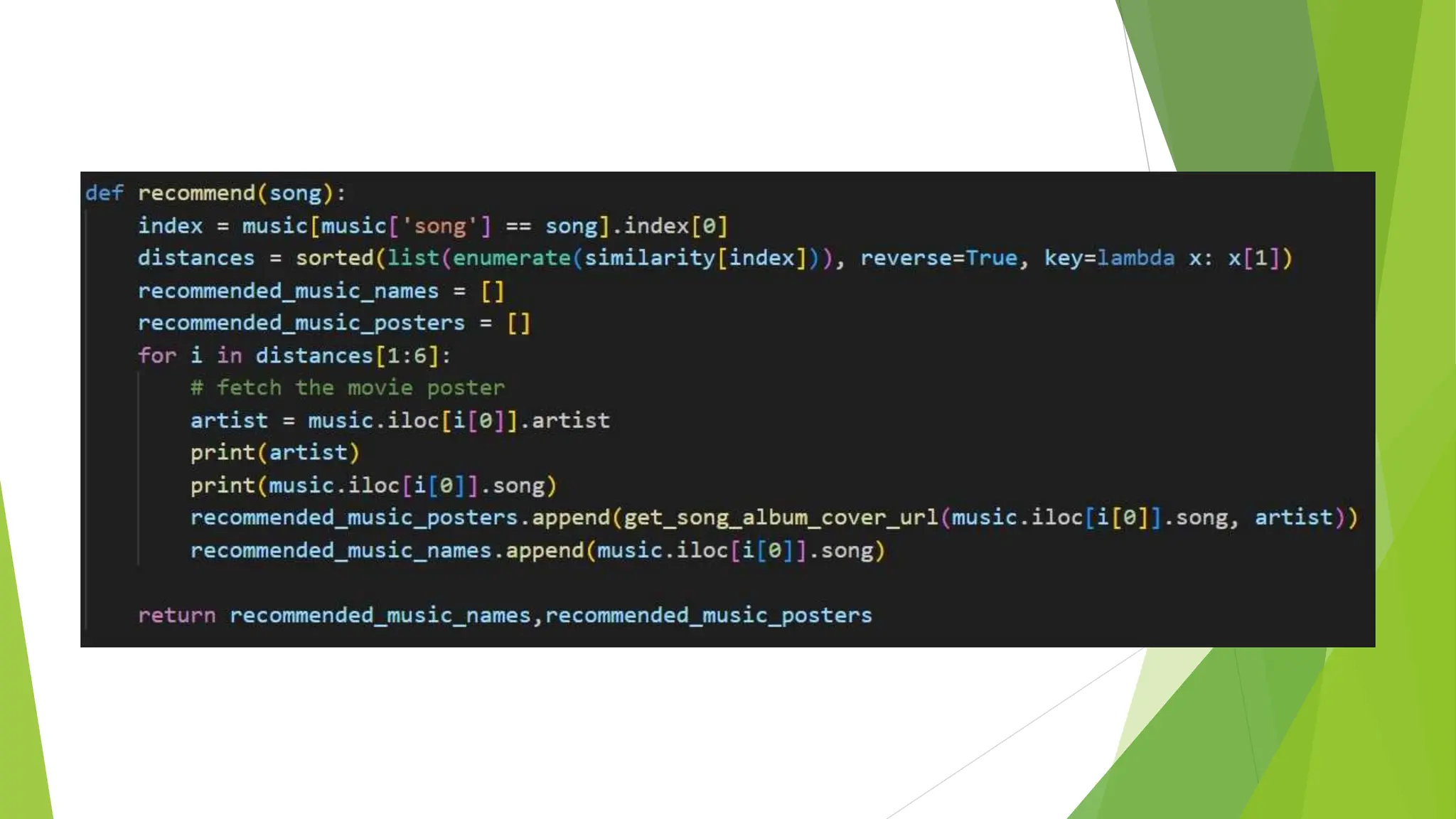
The document presents a project on developing a machine learning model for music recommendation, focusing on tokenization techniques to process user preferences and tackle data challenges. It outlines the problem statement, objectives, and methodologies including feature extraction, similarity metrics, and various recommendation techniques. The conclusion emphasizes the importance of such systems in enhancing user experiences on music streaming platforms and their relevance in both academic and practical applications of machine learning.