Downloaded 371 times







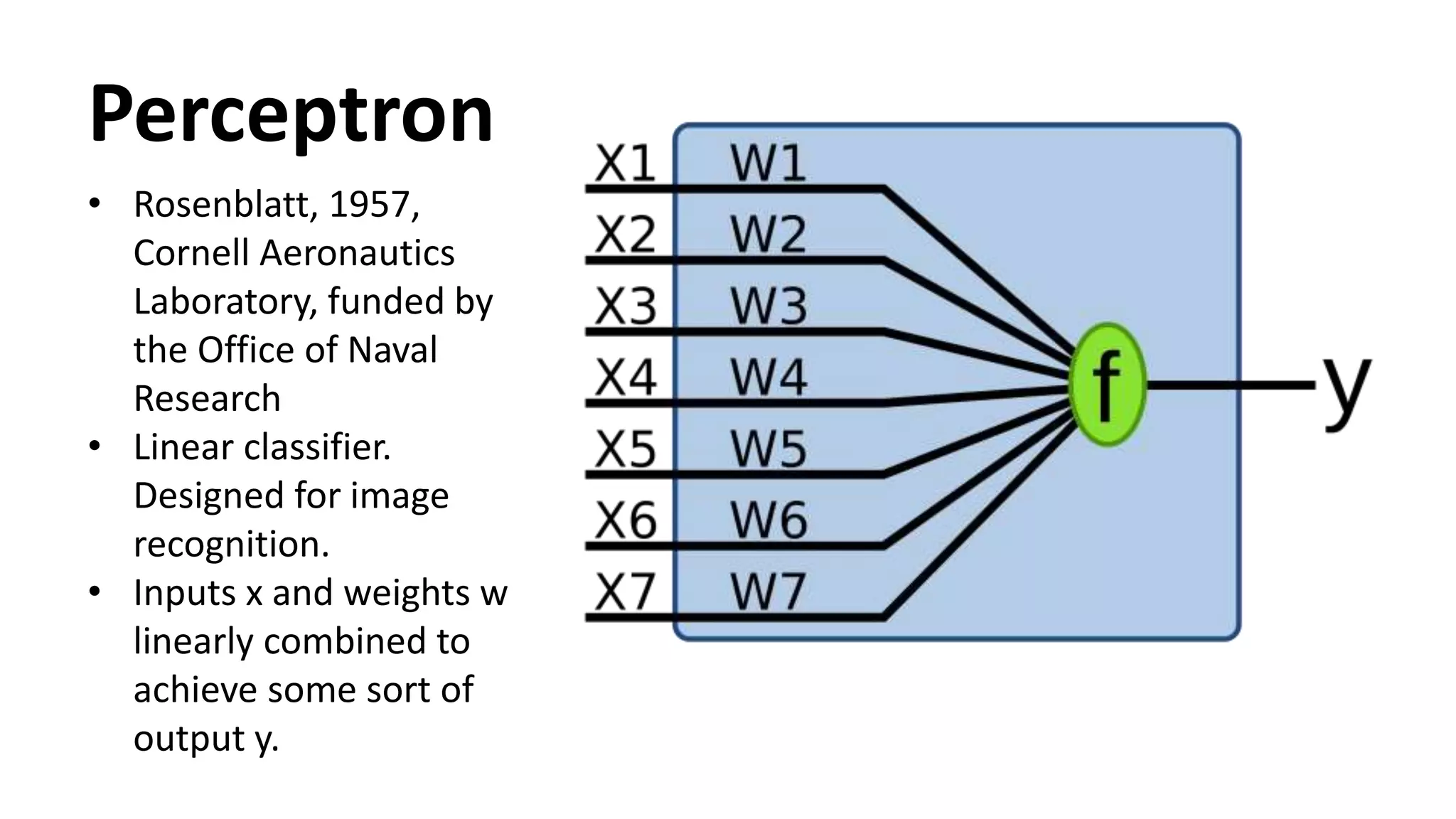
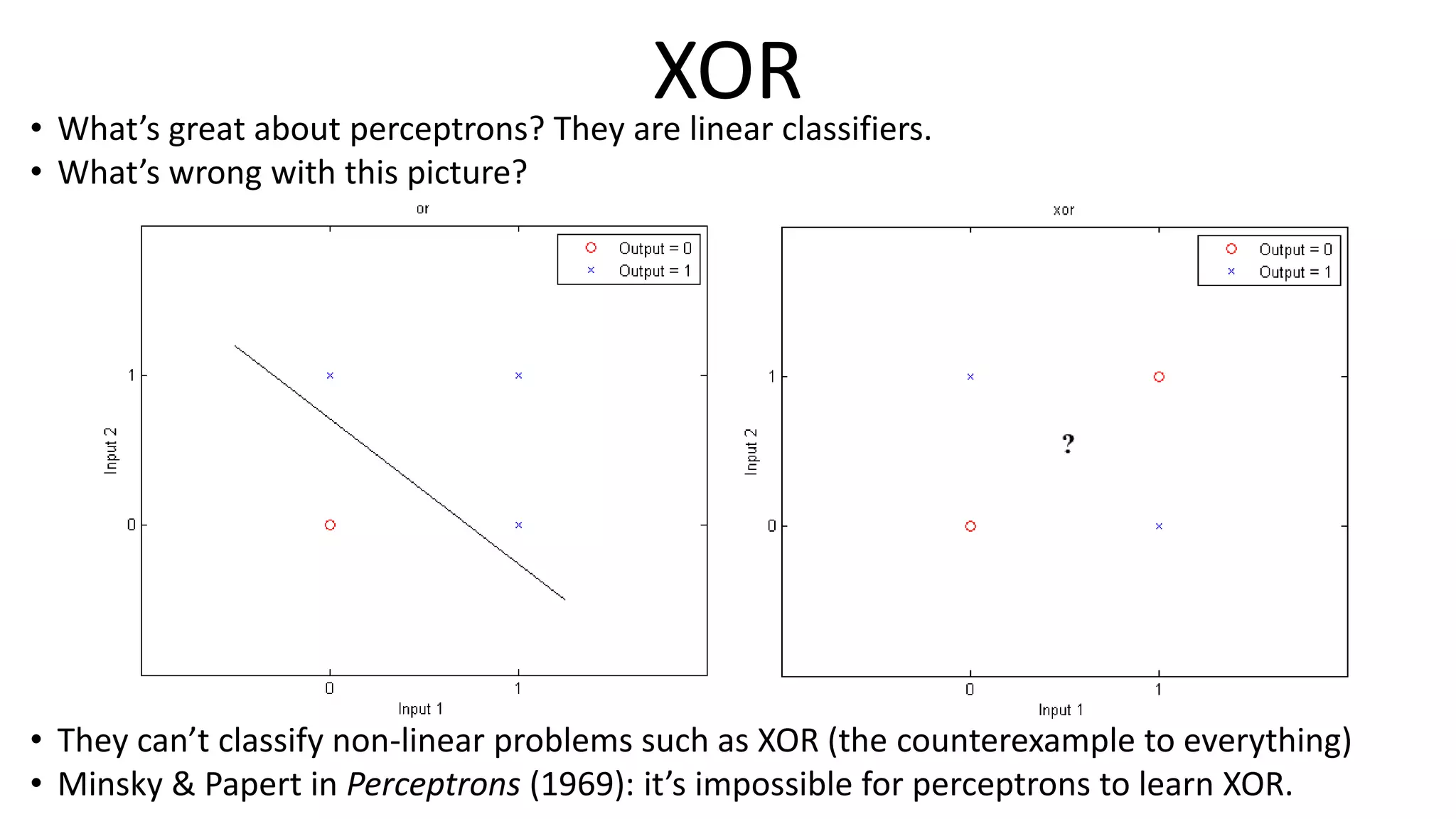
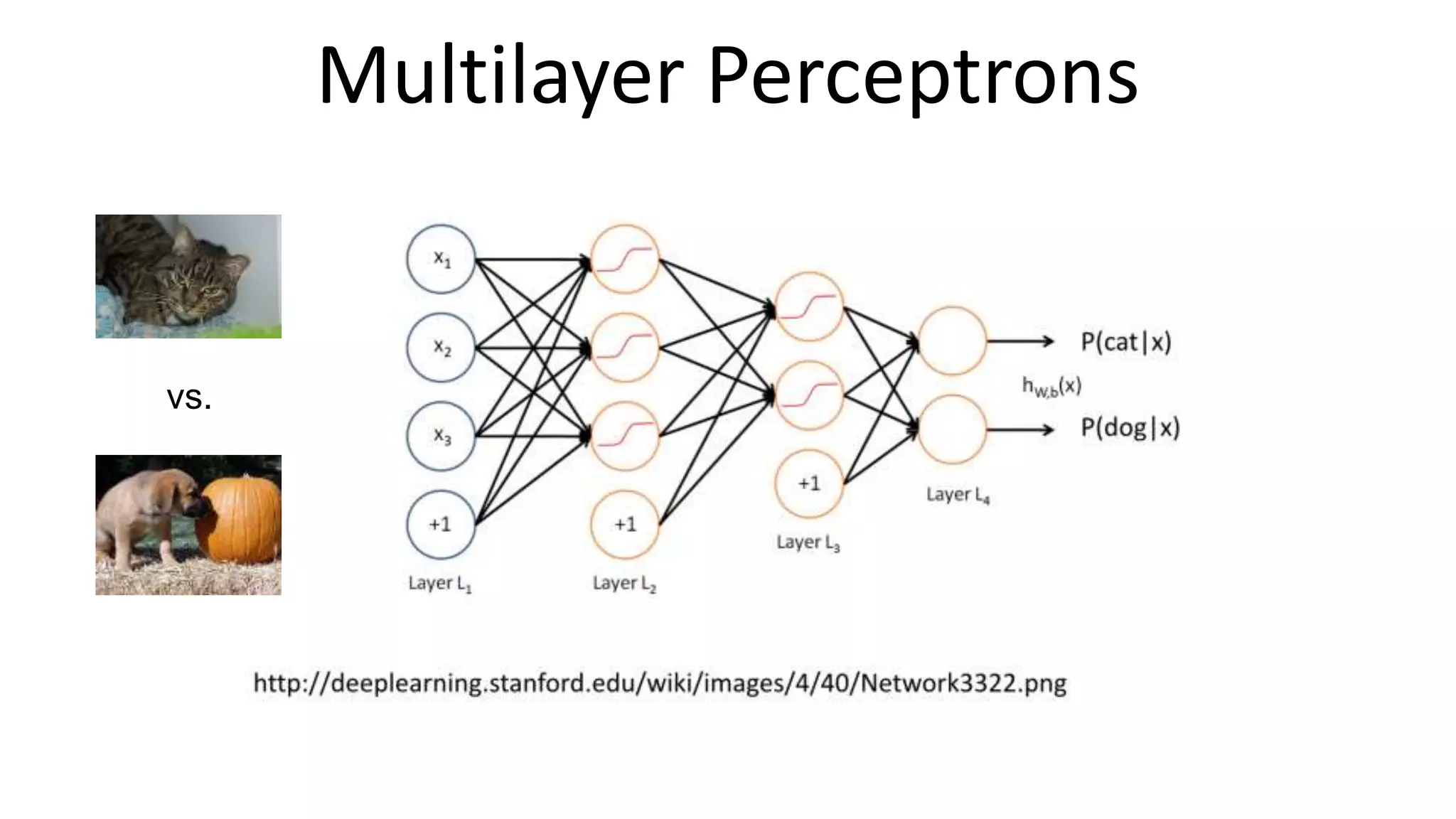


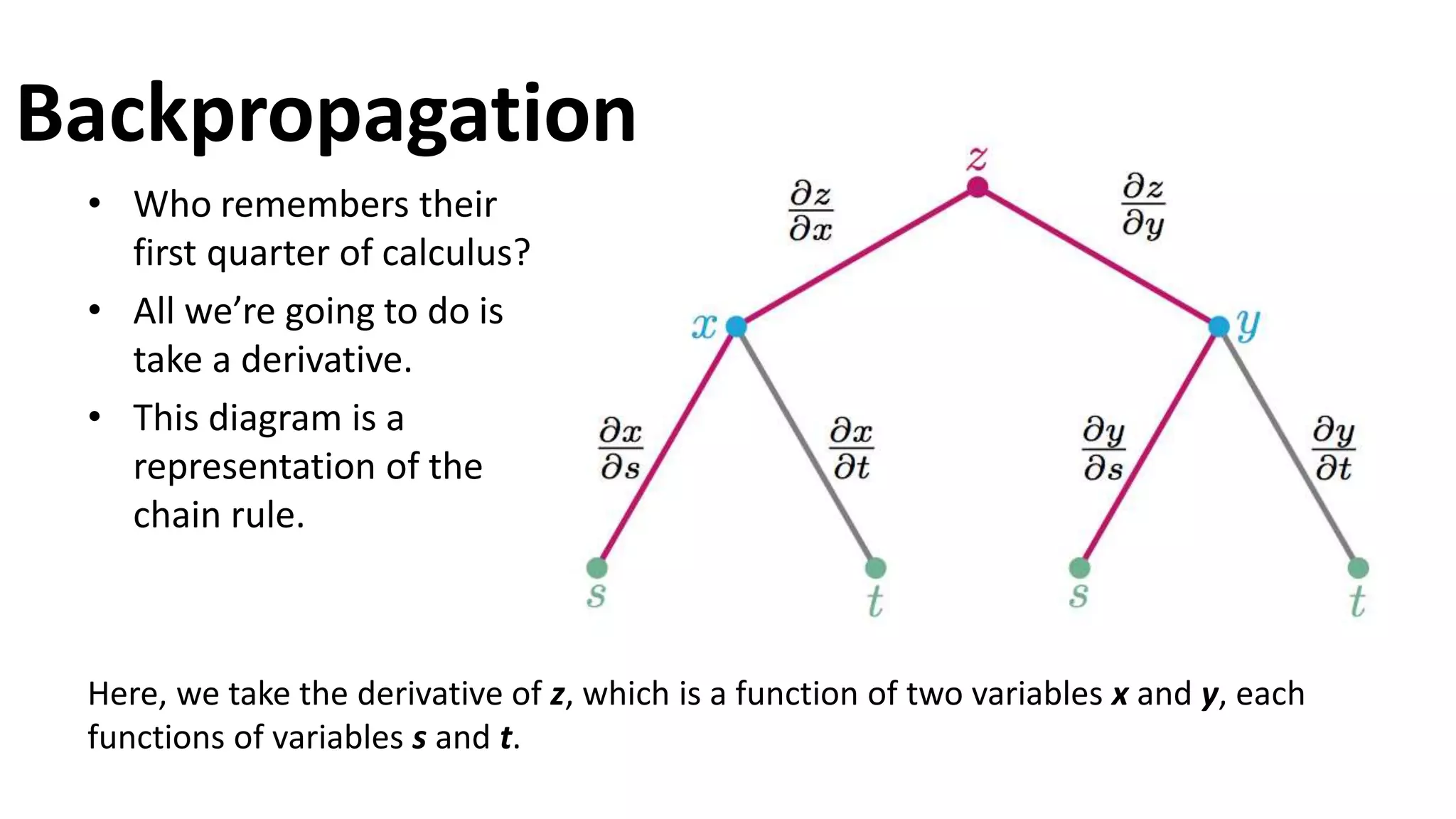















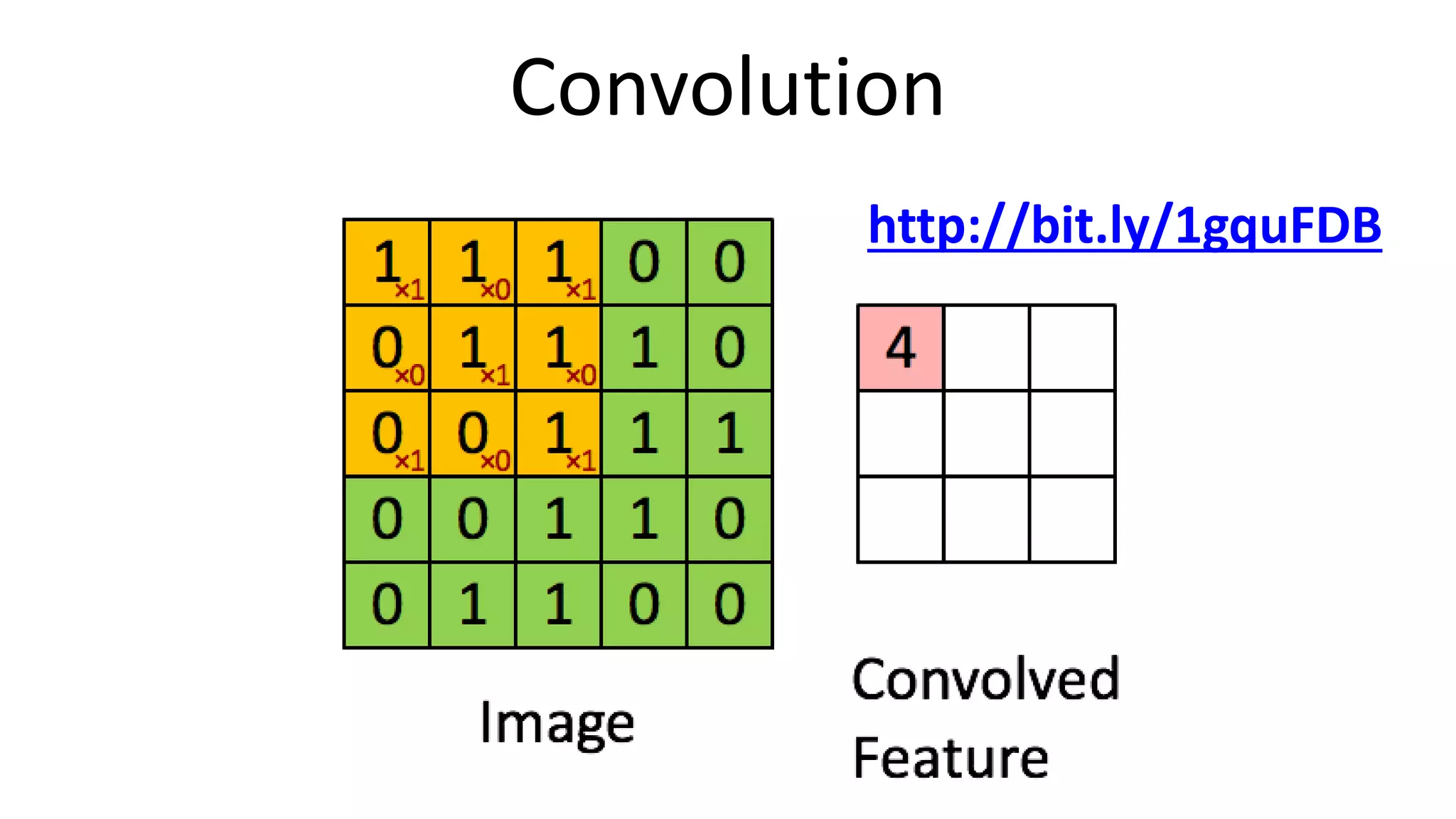


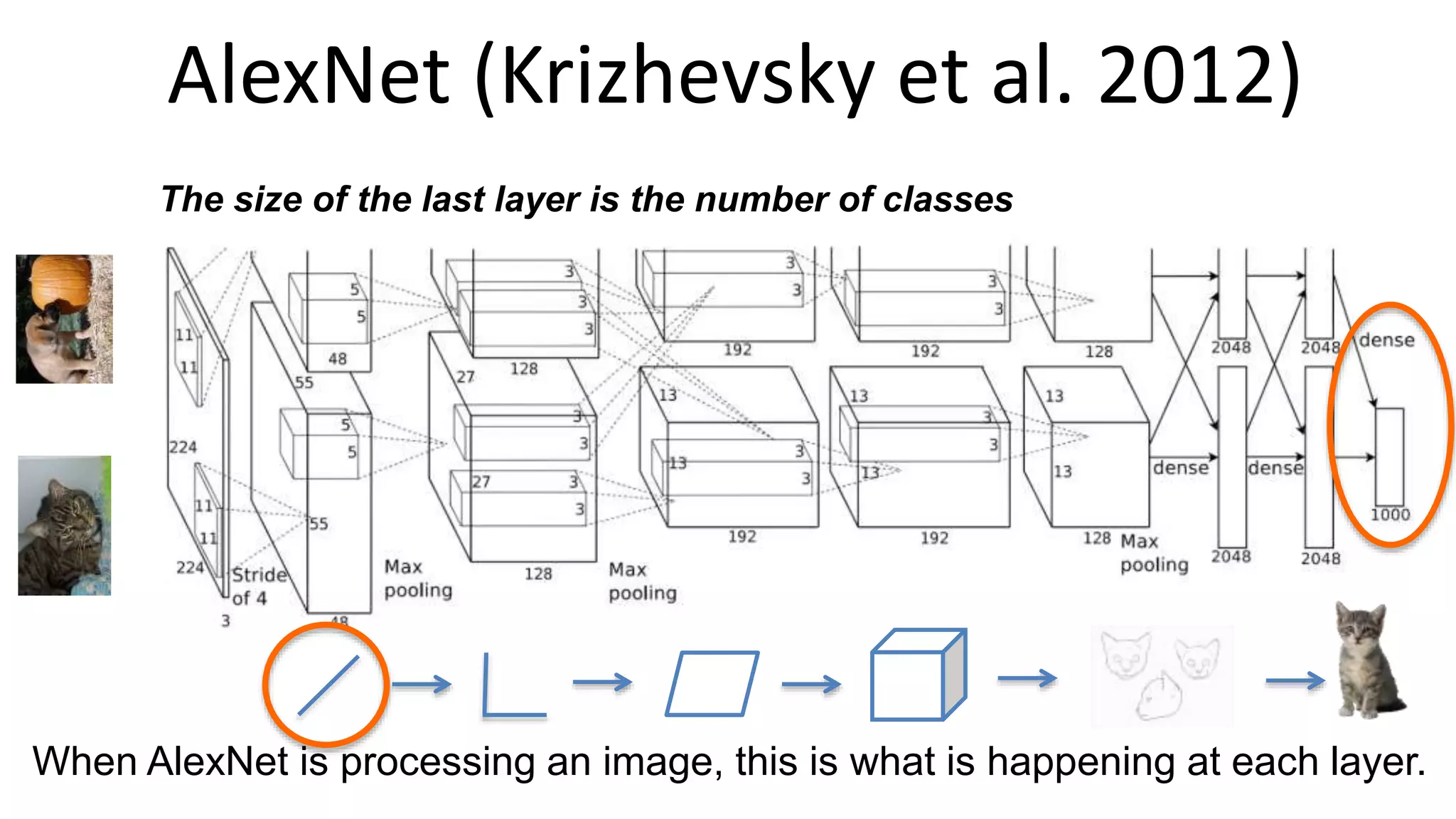
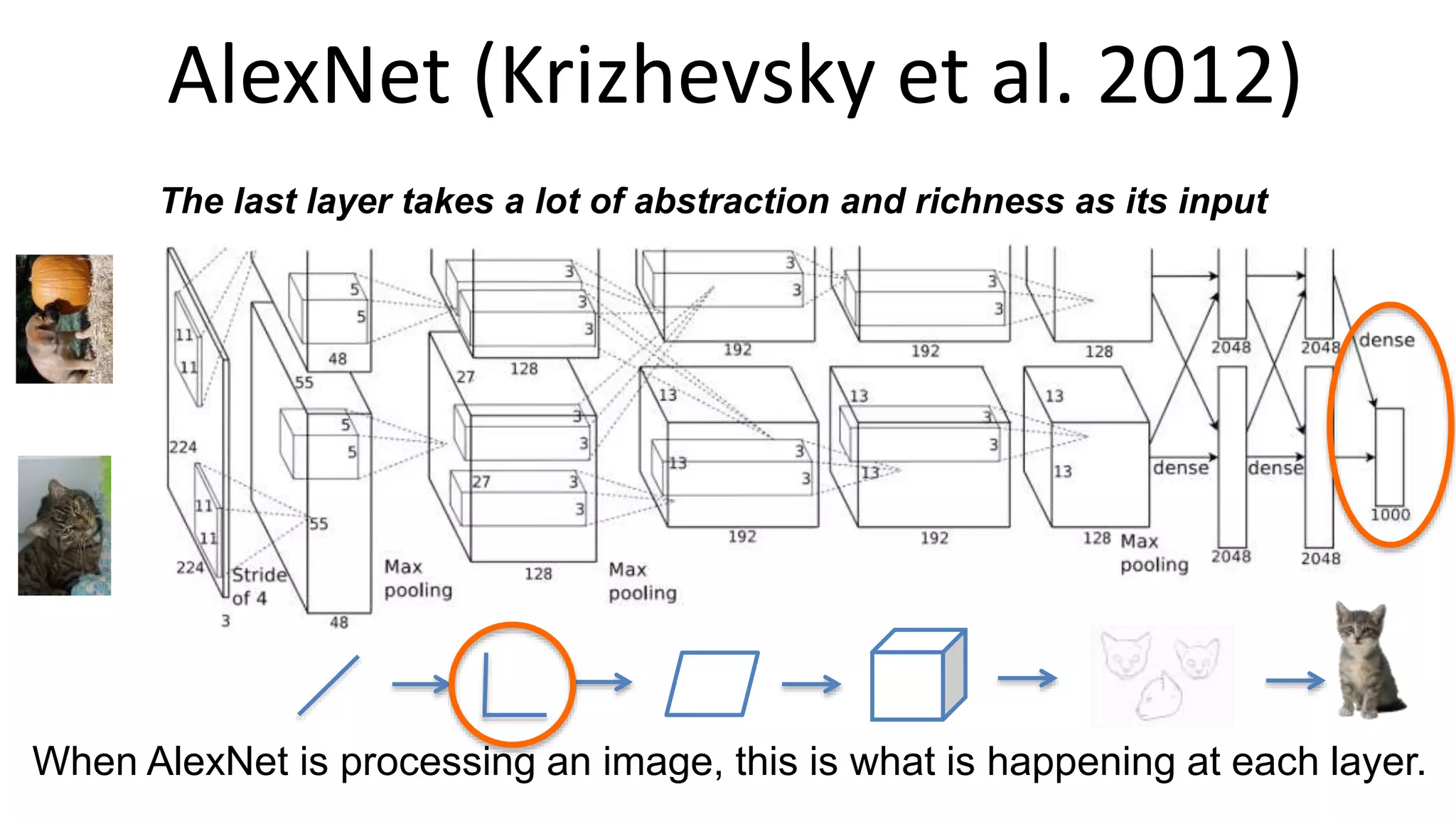
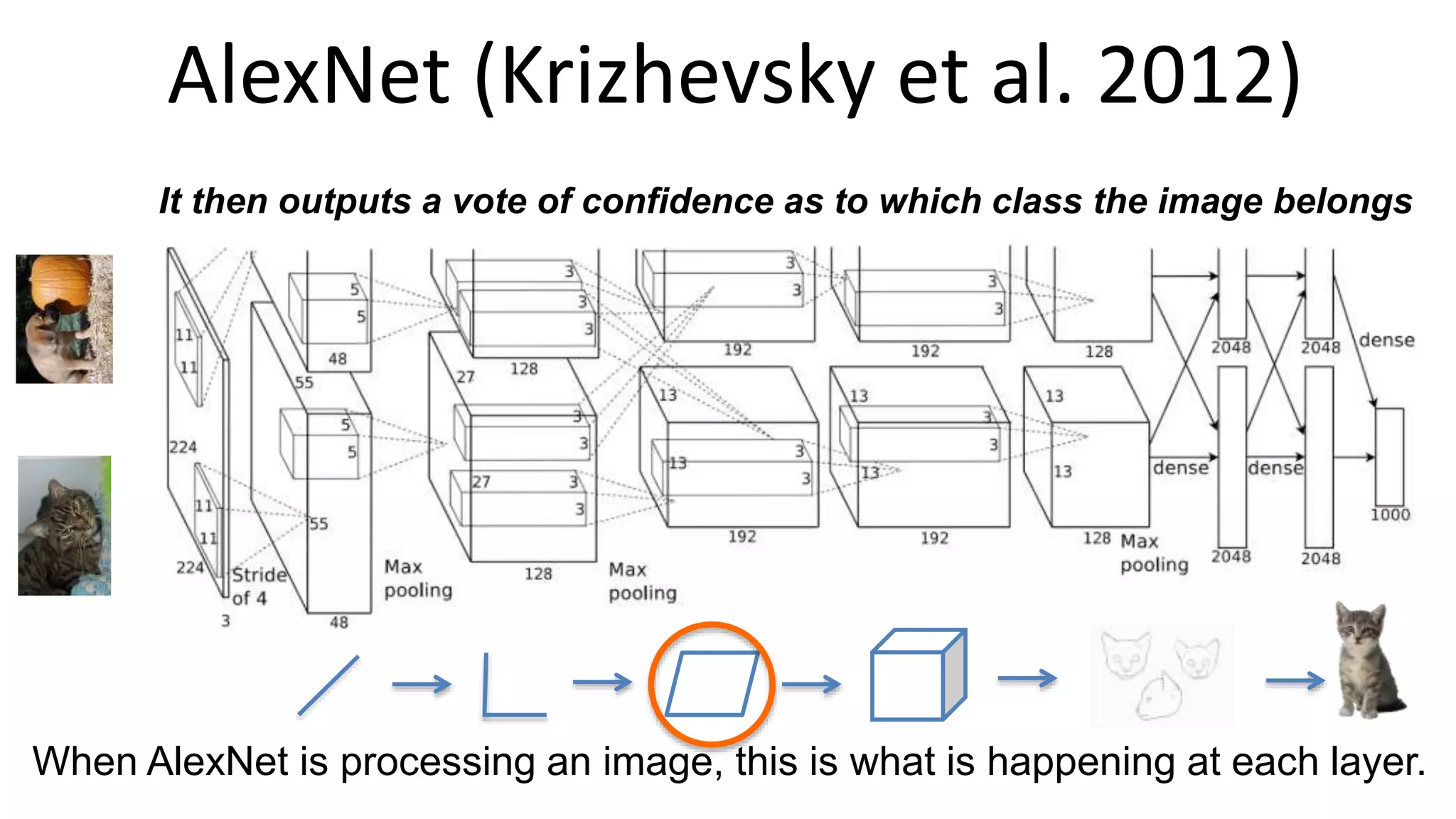
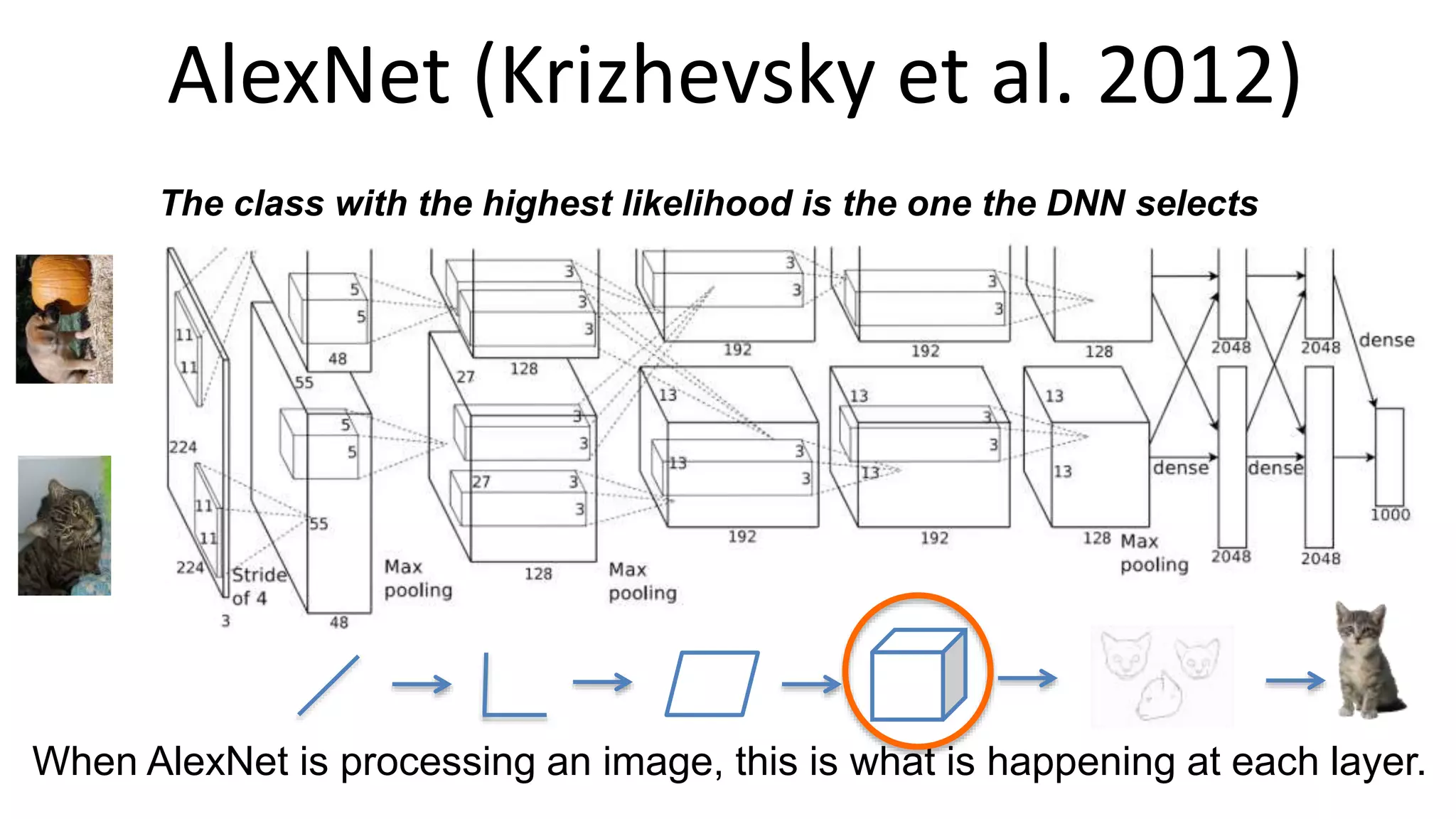
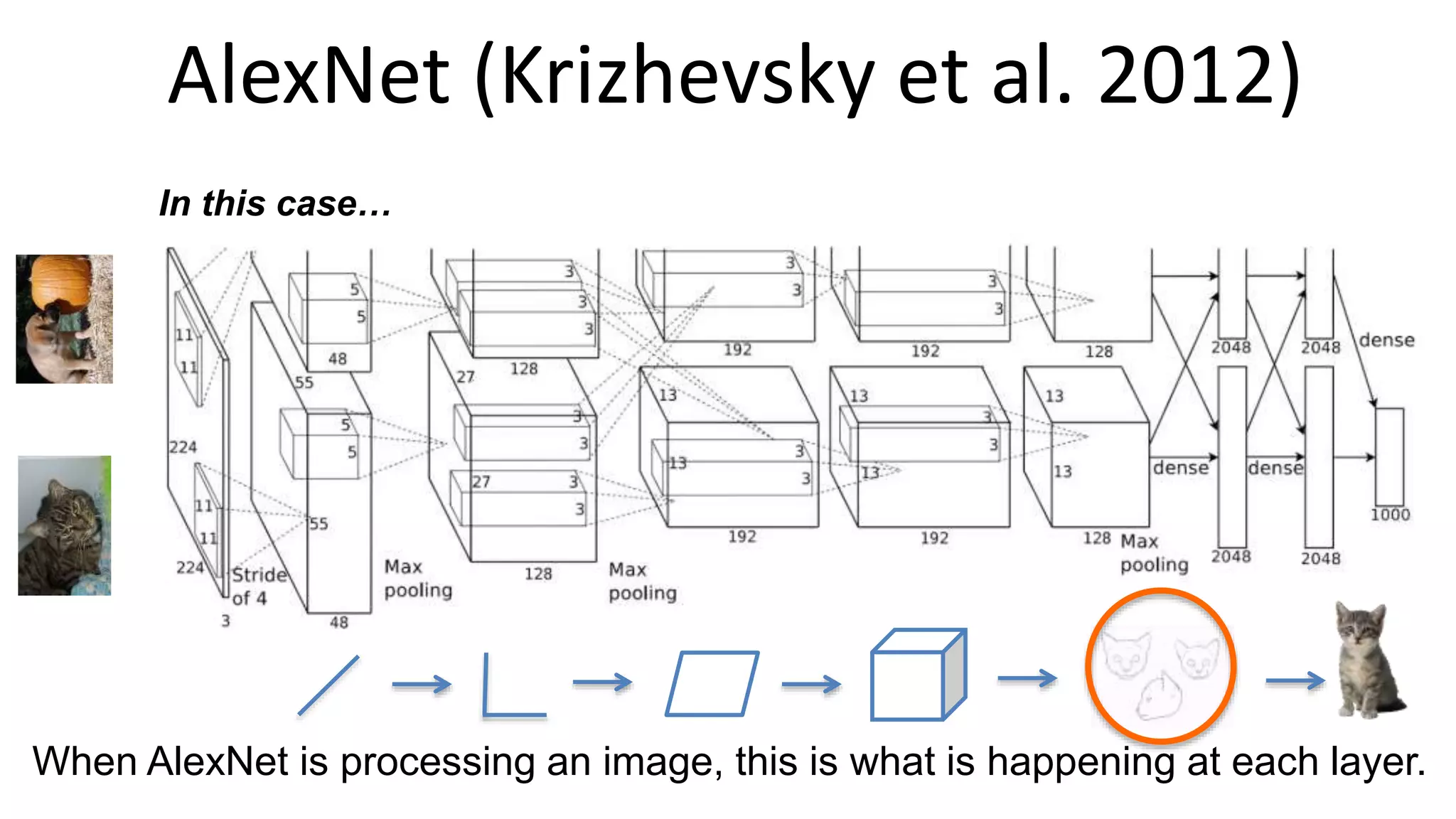
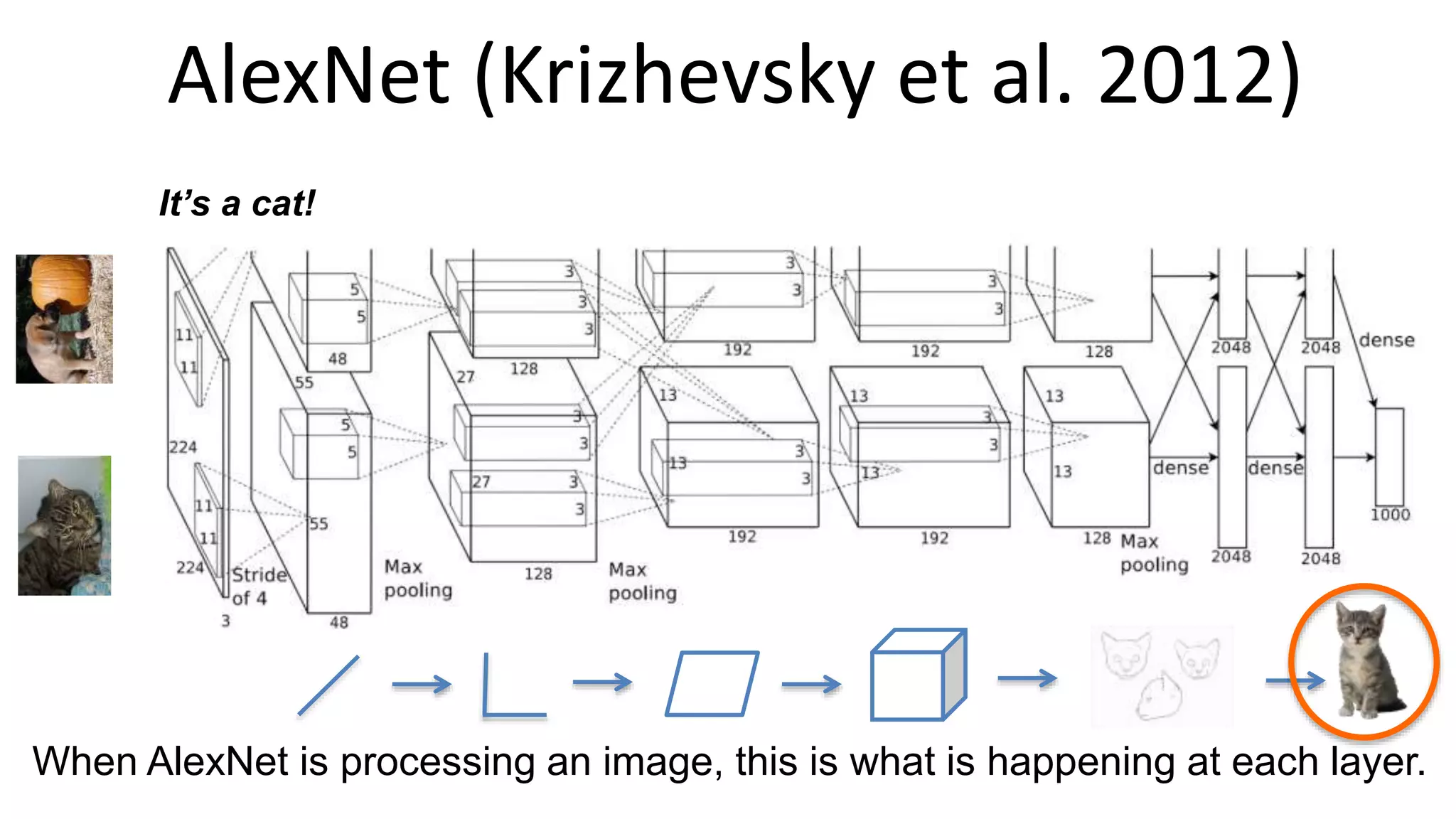







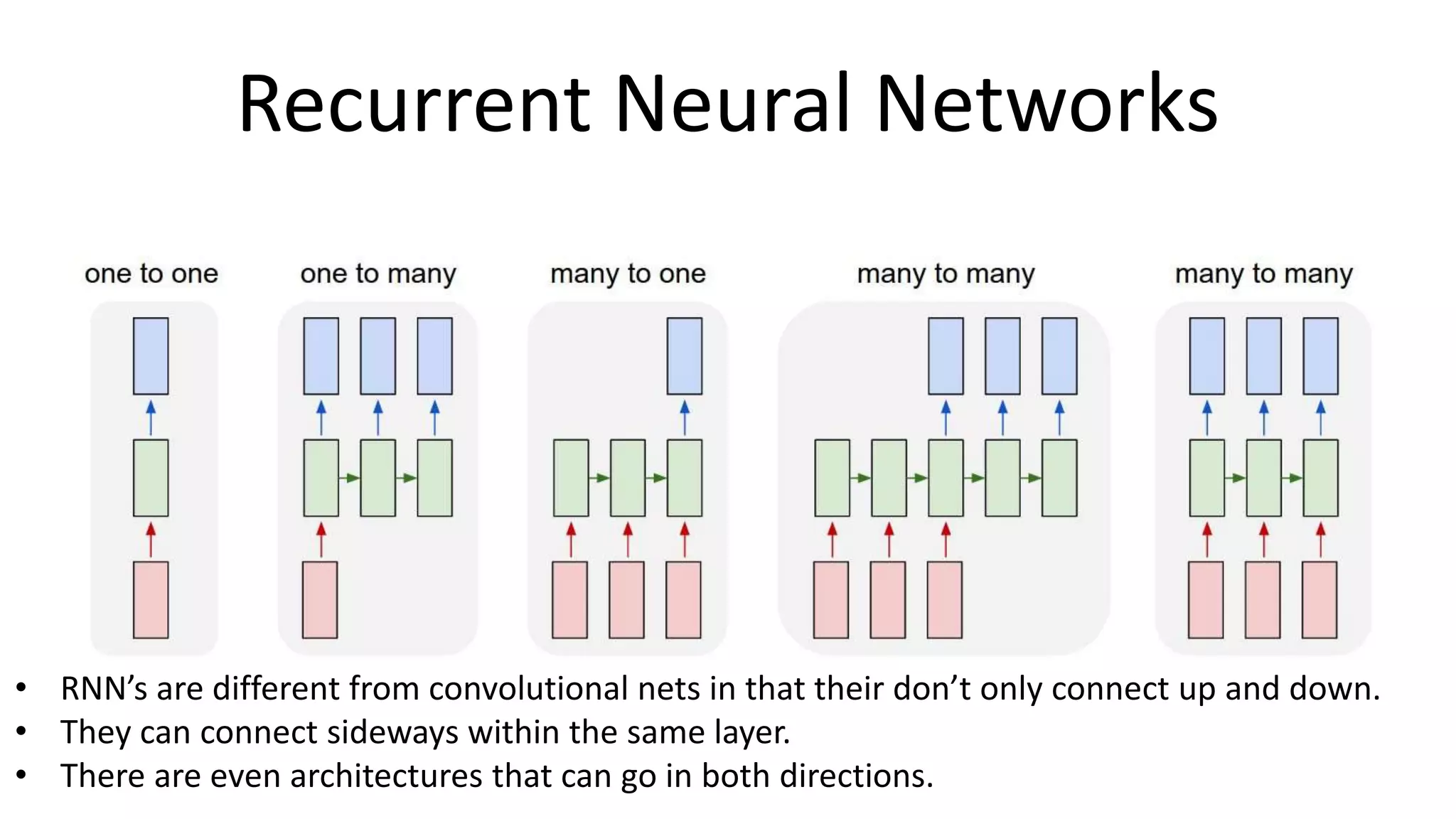
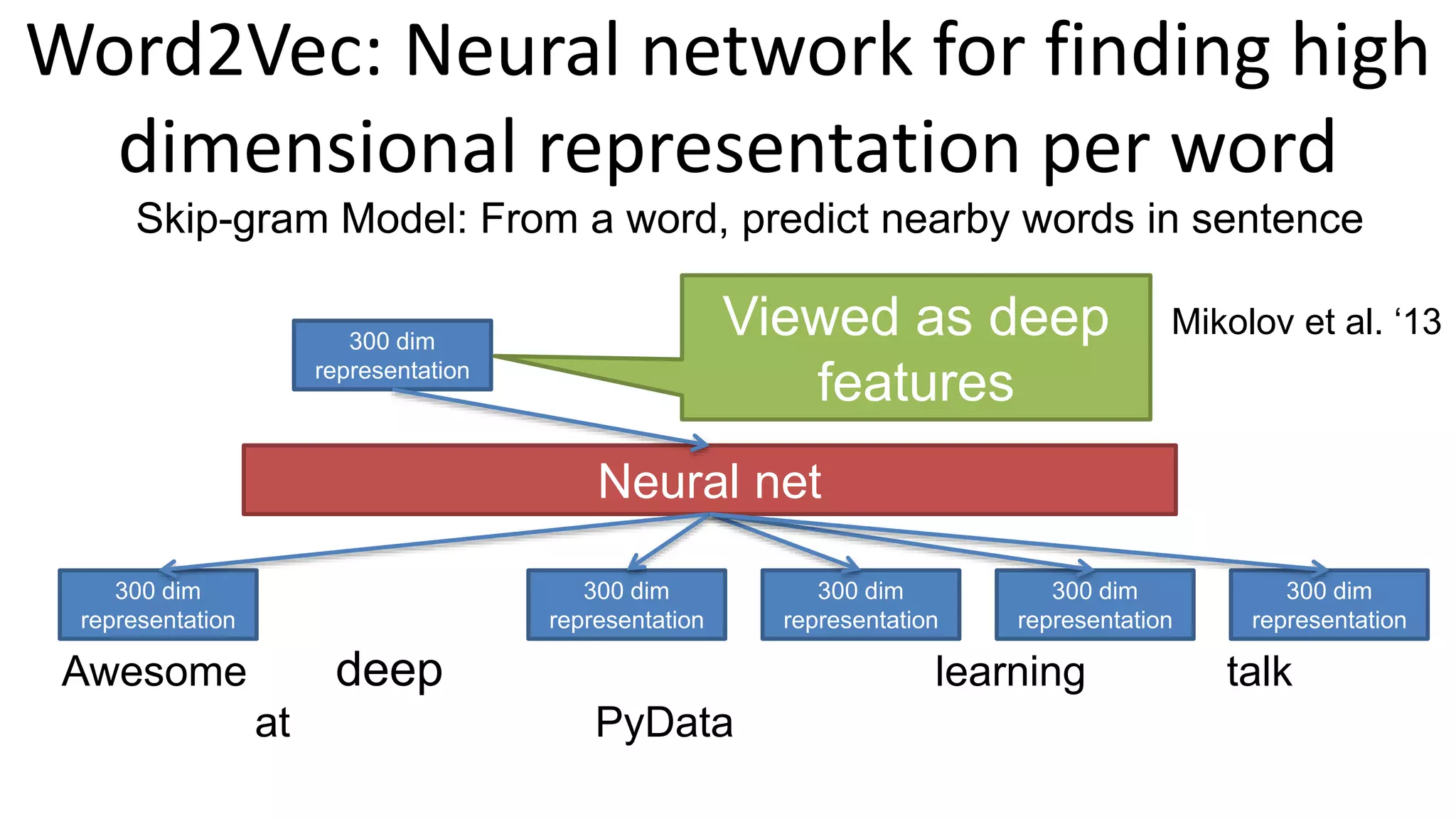
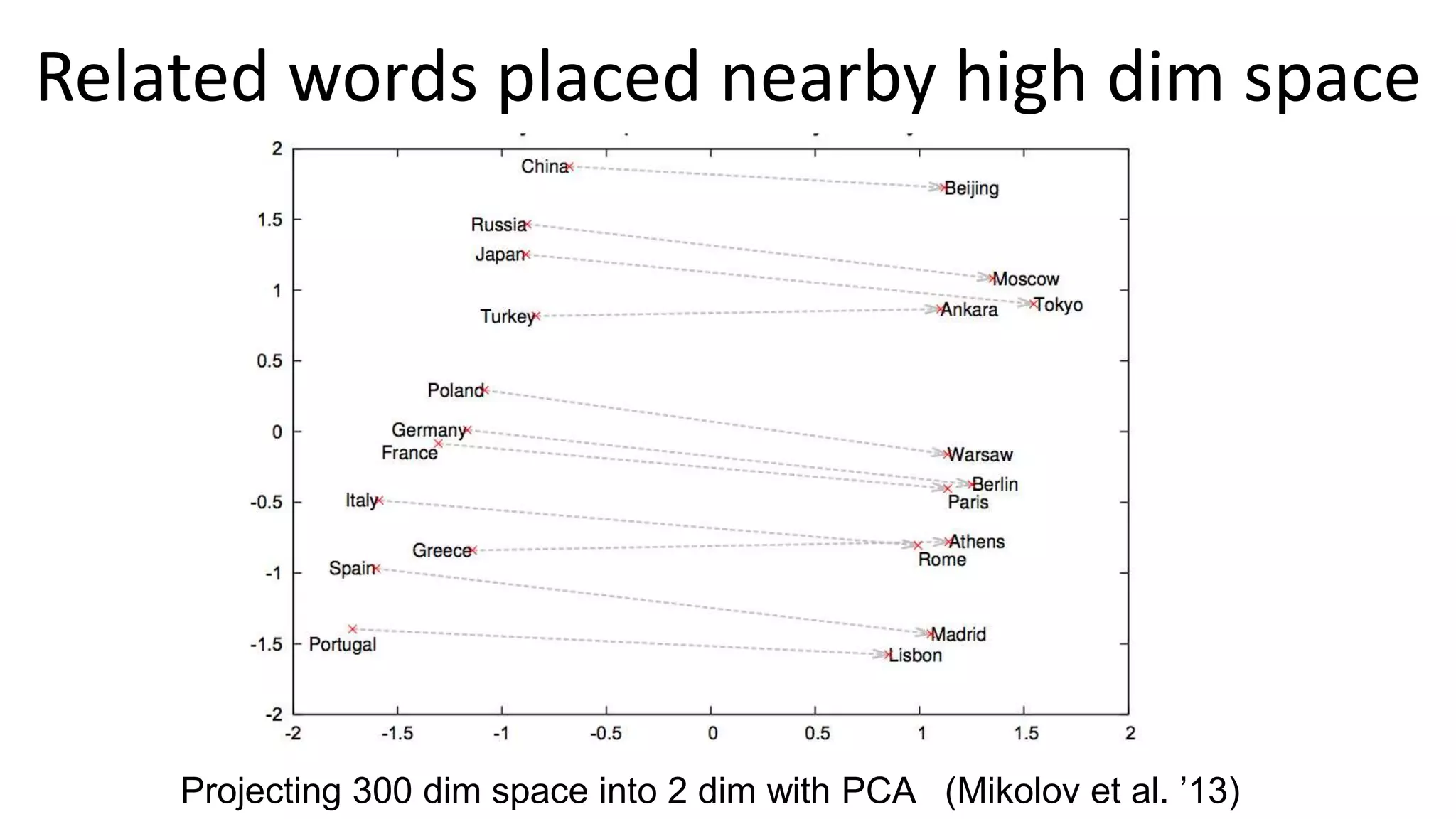






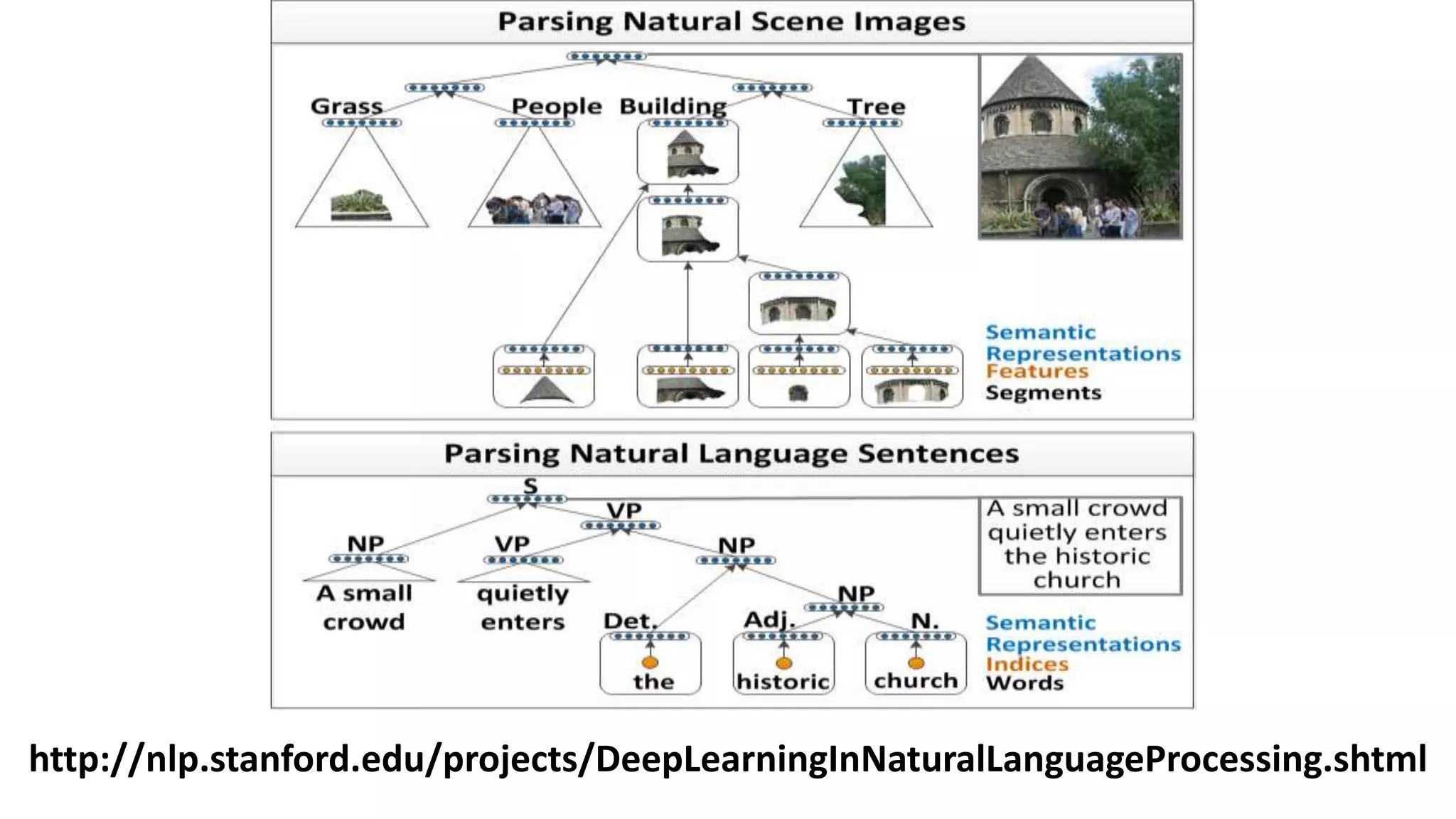

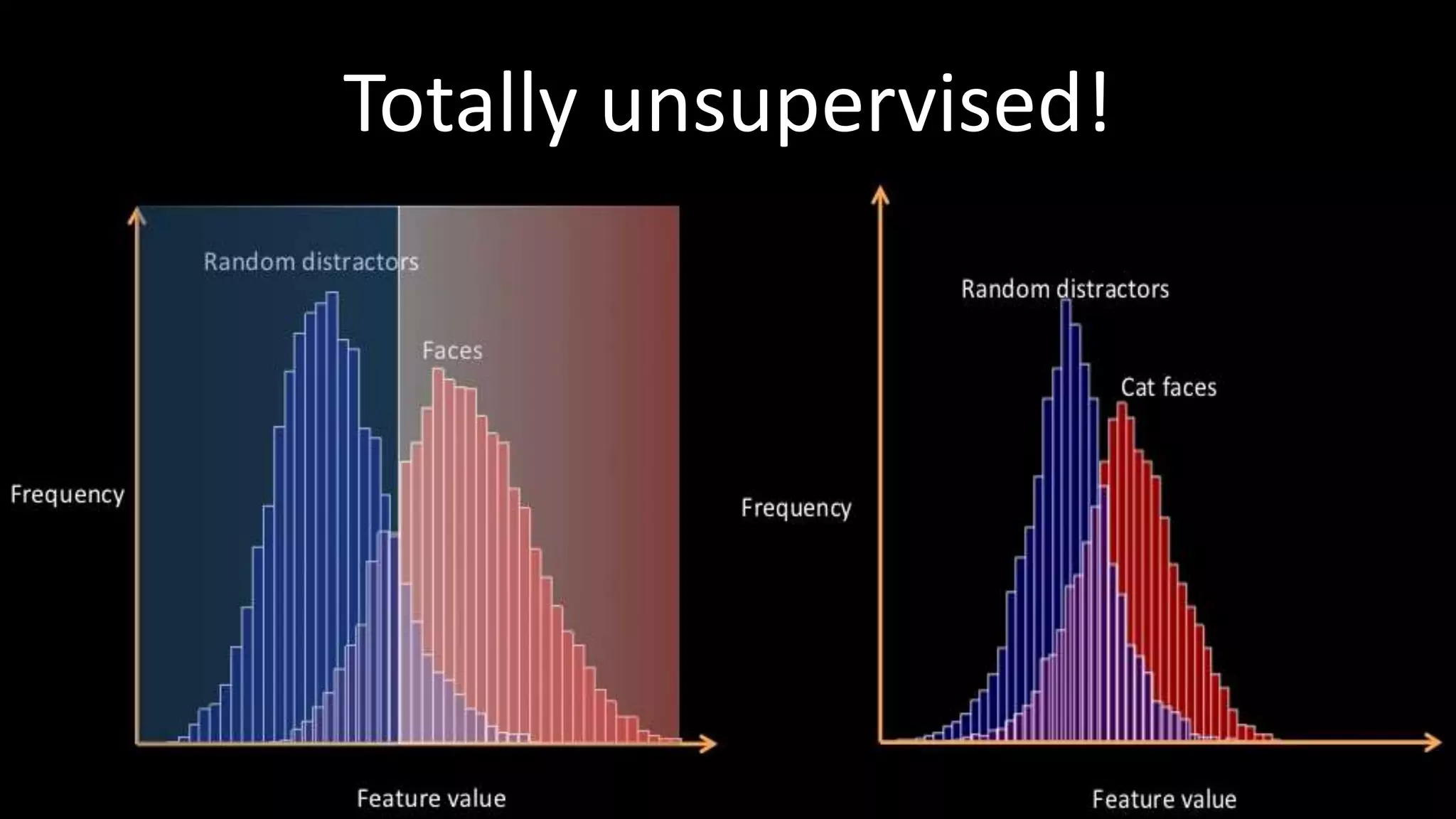


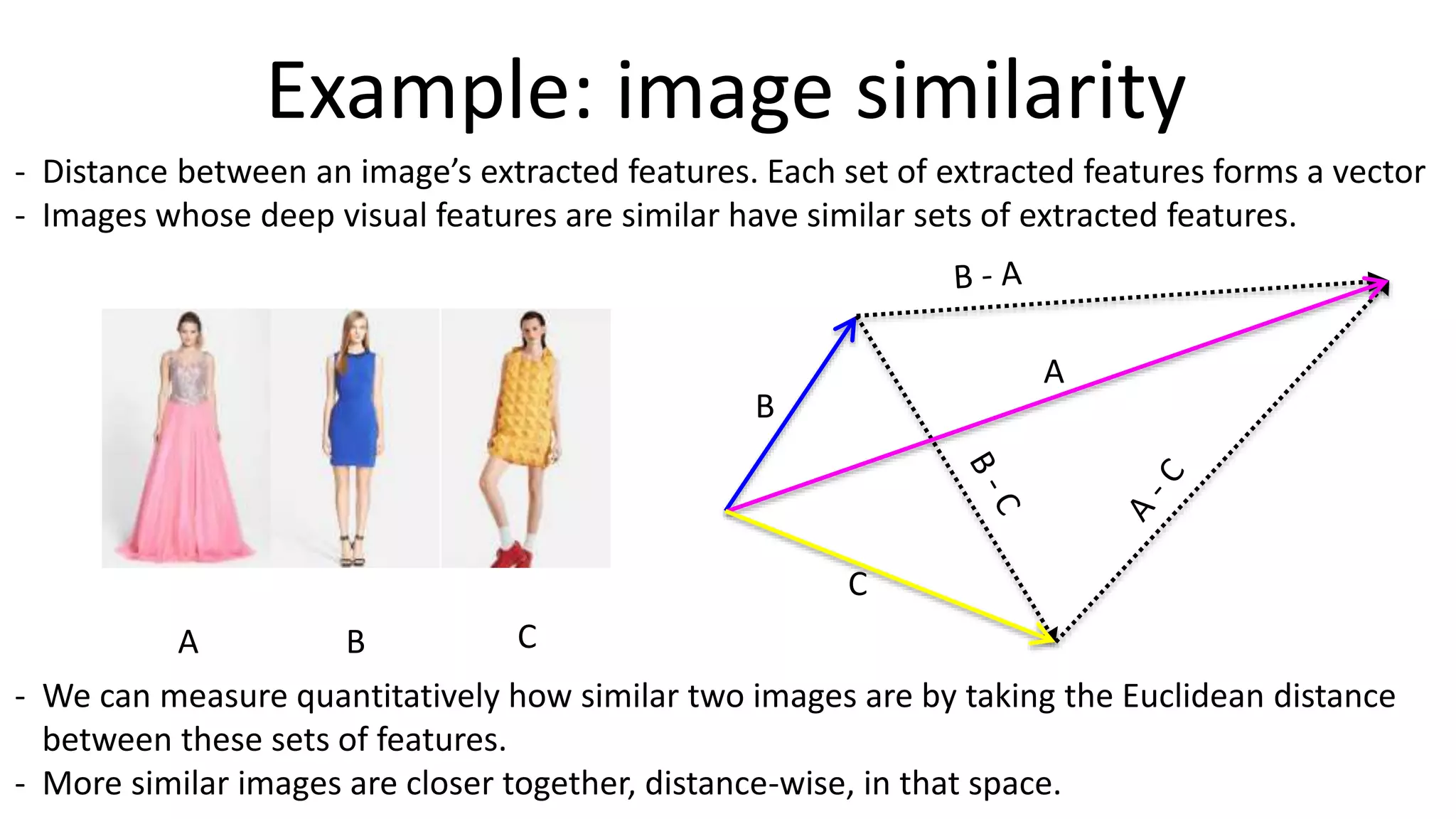
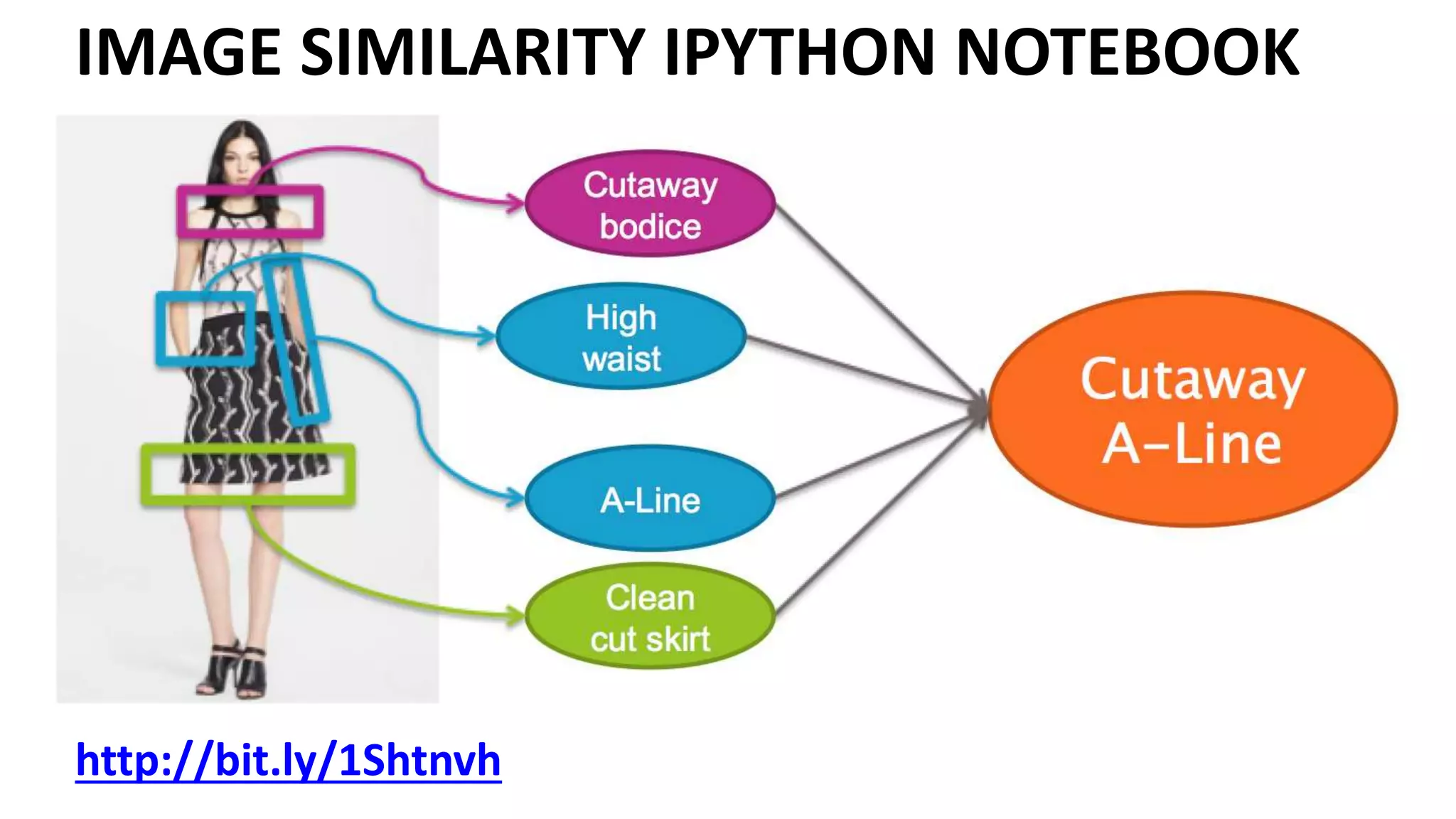


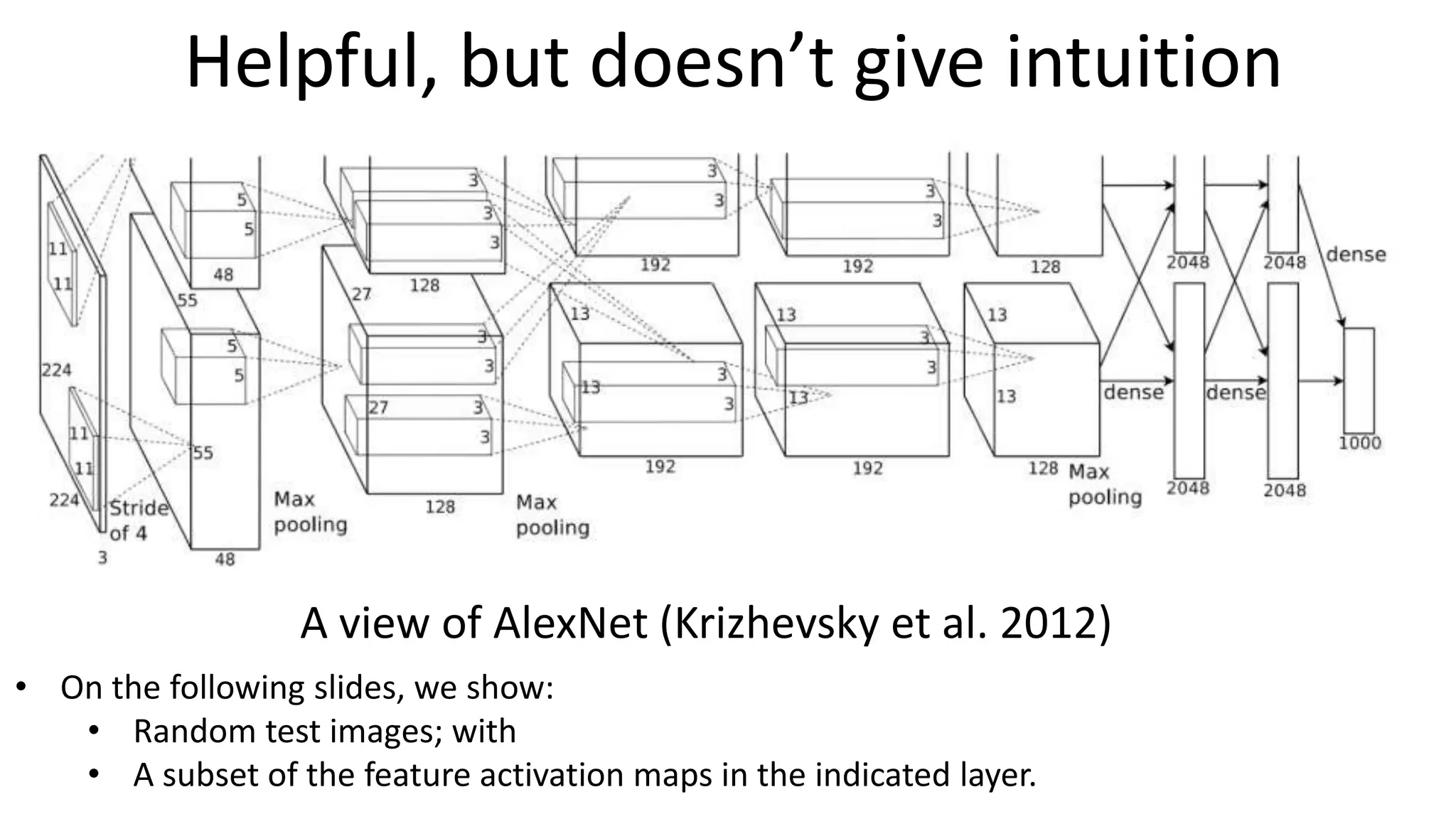
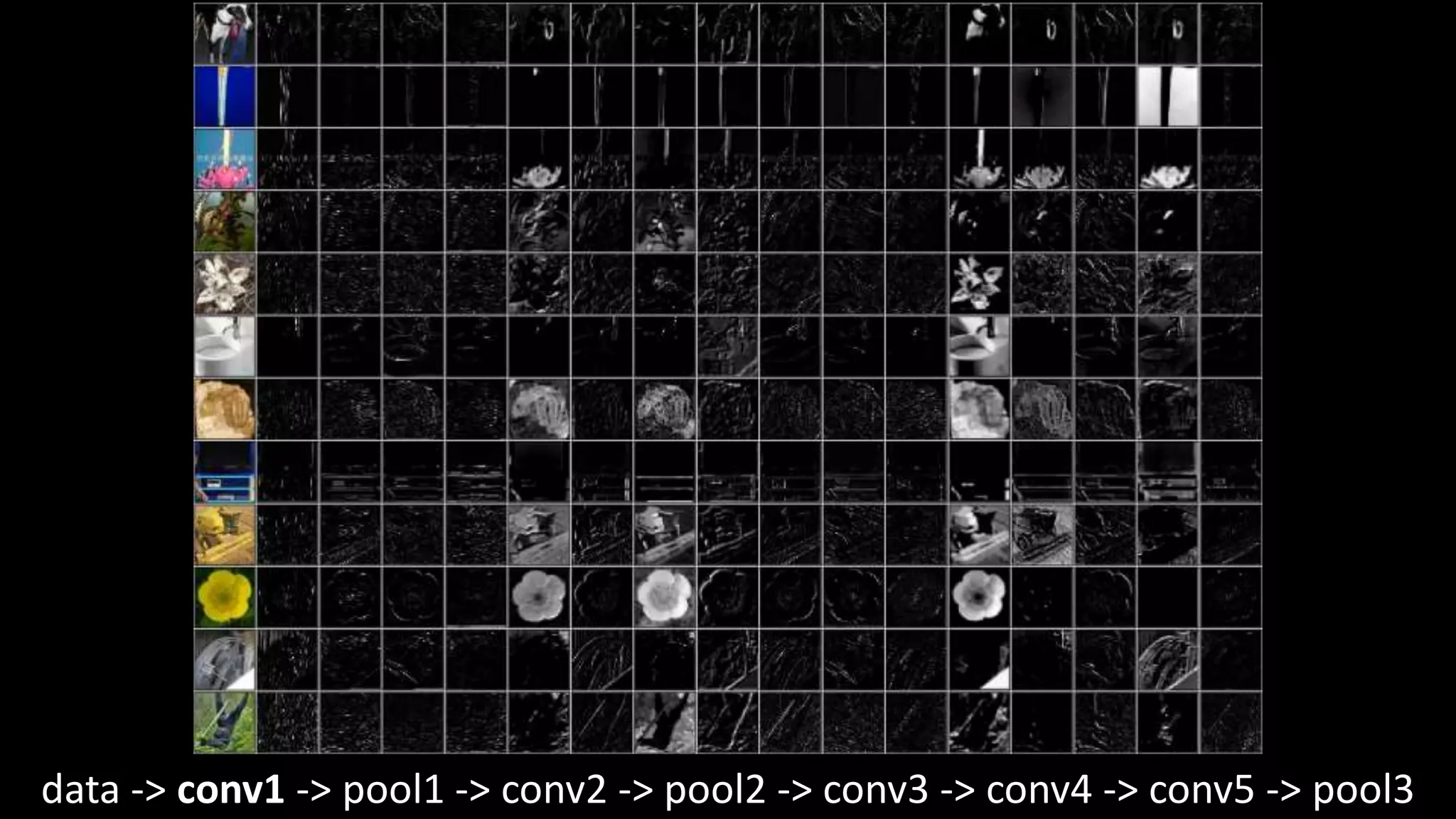















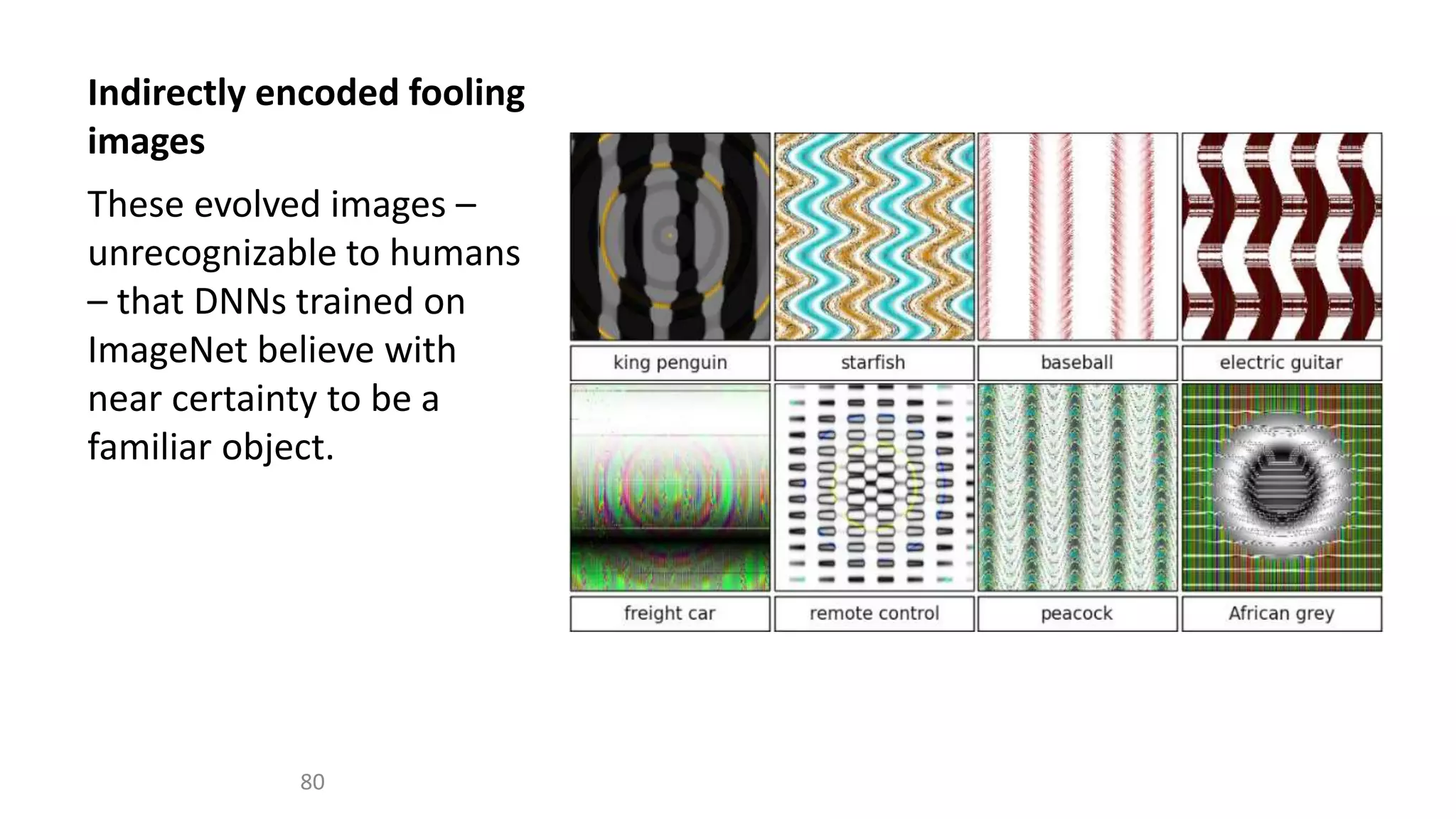

























































































The document outlines the fundamentals of deep learning, highlighting its potential applications and tools available for practitioners. It introduces key concepts such as neural networks, backpropagation, and various learning methodologies, while mentioning notable architectures like convolutional and recurrent neural networks. It also discusses recent advancements, applications in fields like computer vision and natural language processing, potential pitfalls, and concerns regarding interpretability and adversarial examples.
























































![[DSC Europe 25] Milan Misic - RAG, recommenders and face recognition applica...](https://cdn.slidesharecdn.com/ss_thumbnails/mxe0wzfeqkortbfecopo-8-251128093135-51a402bb-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Stefan_Milosevic - AI and digital twins in precision oncology...](https://cdn.slidesharecdn.com/ss_thumbnails/nnmuciuxr2ugh4d9pzkg-1-251126104228-148c7fe8-thumbnail.jpg?width=640&height=640&fit=bounds)






