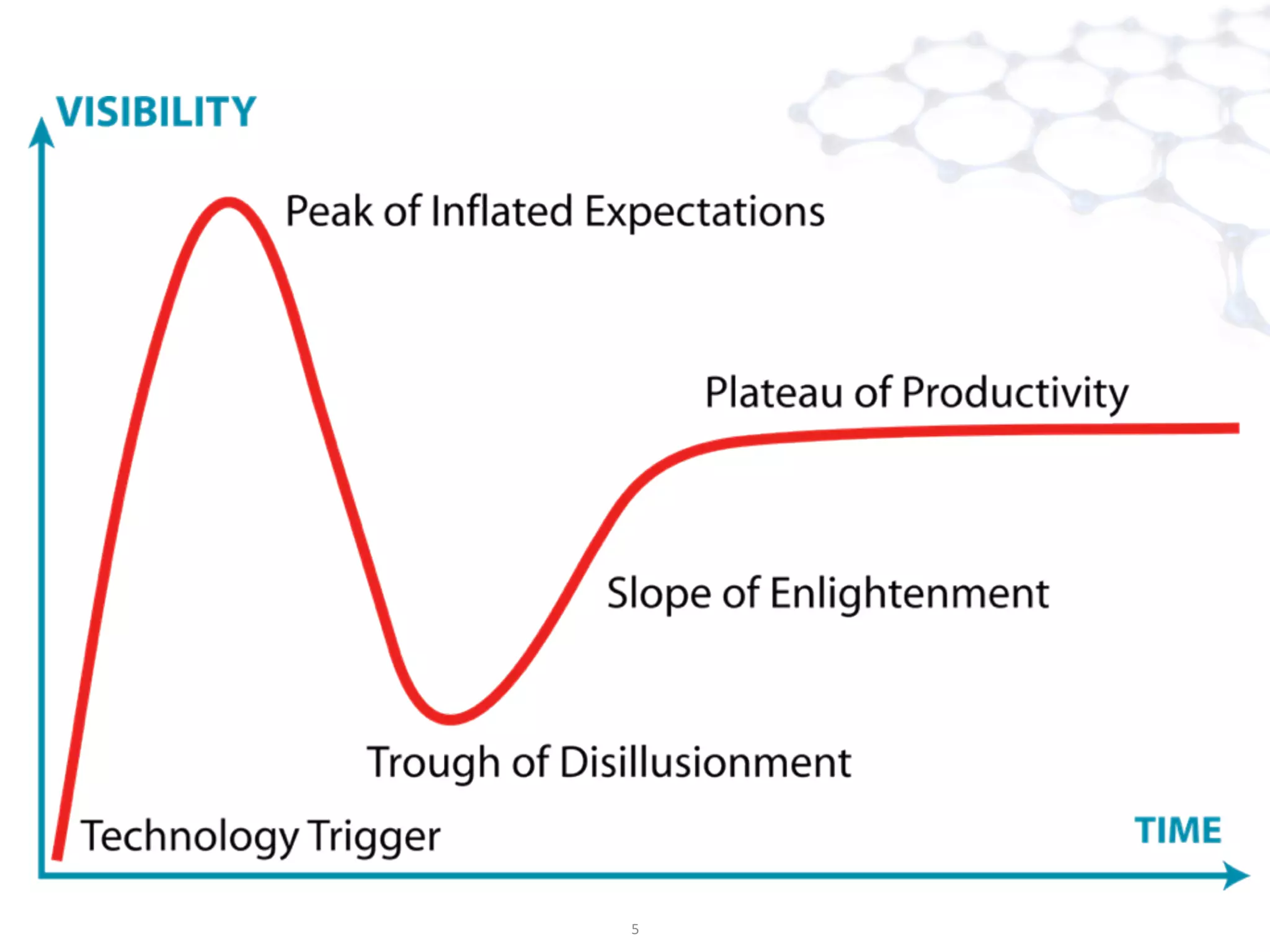
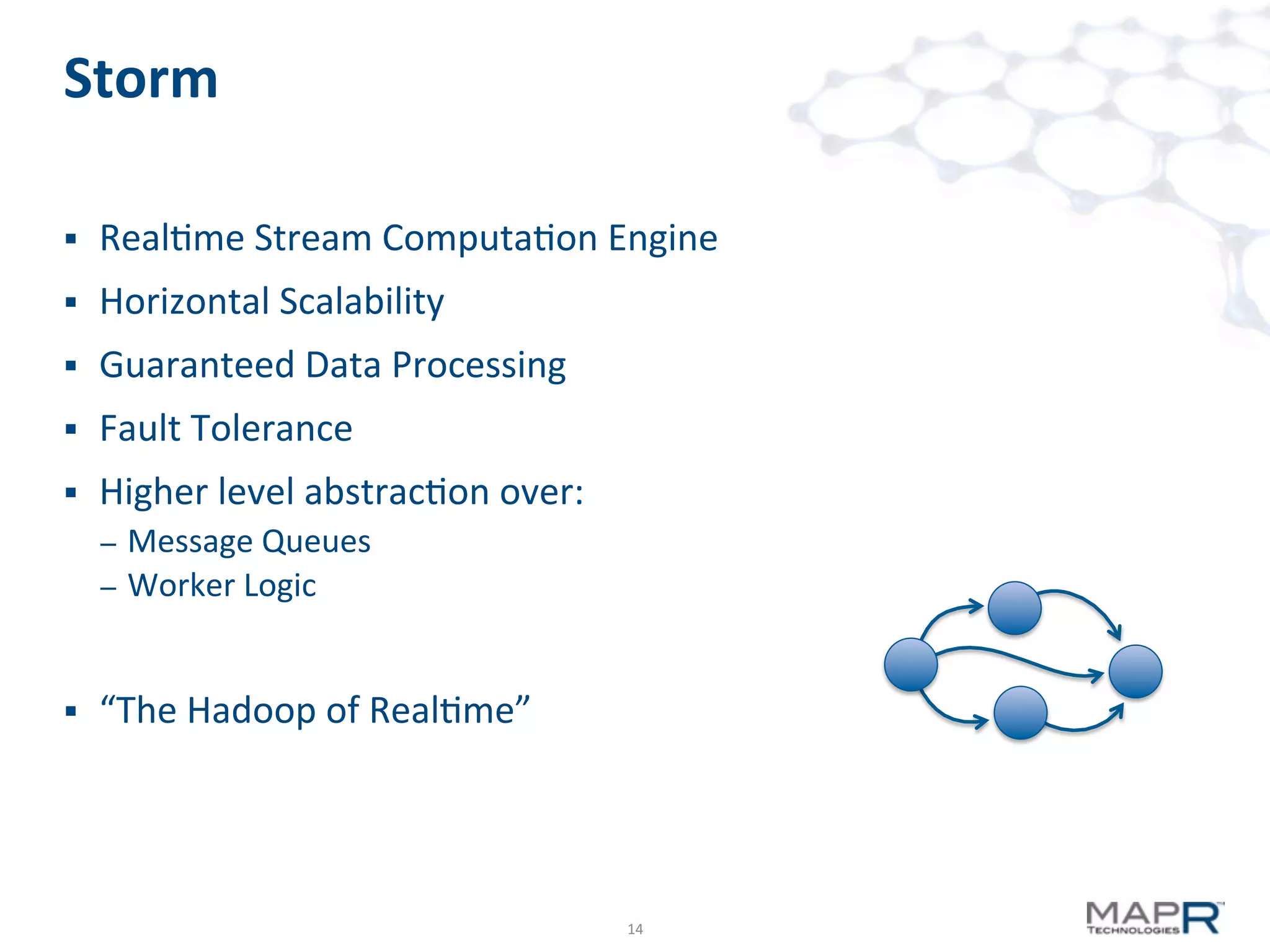
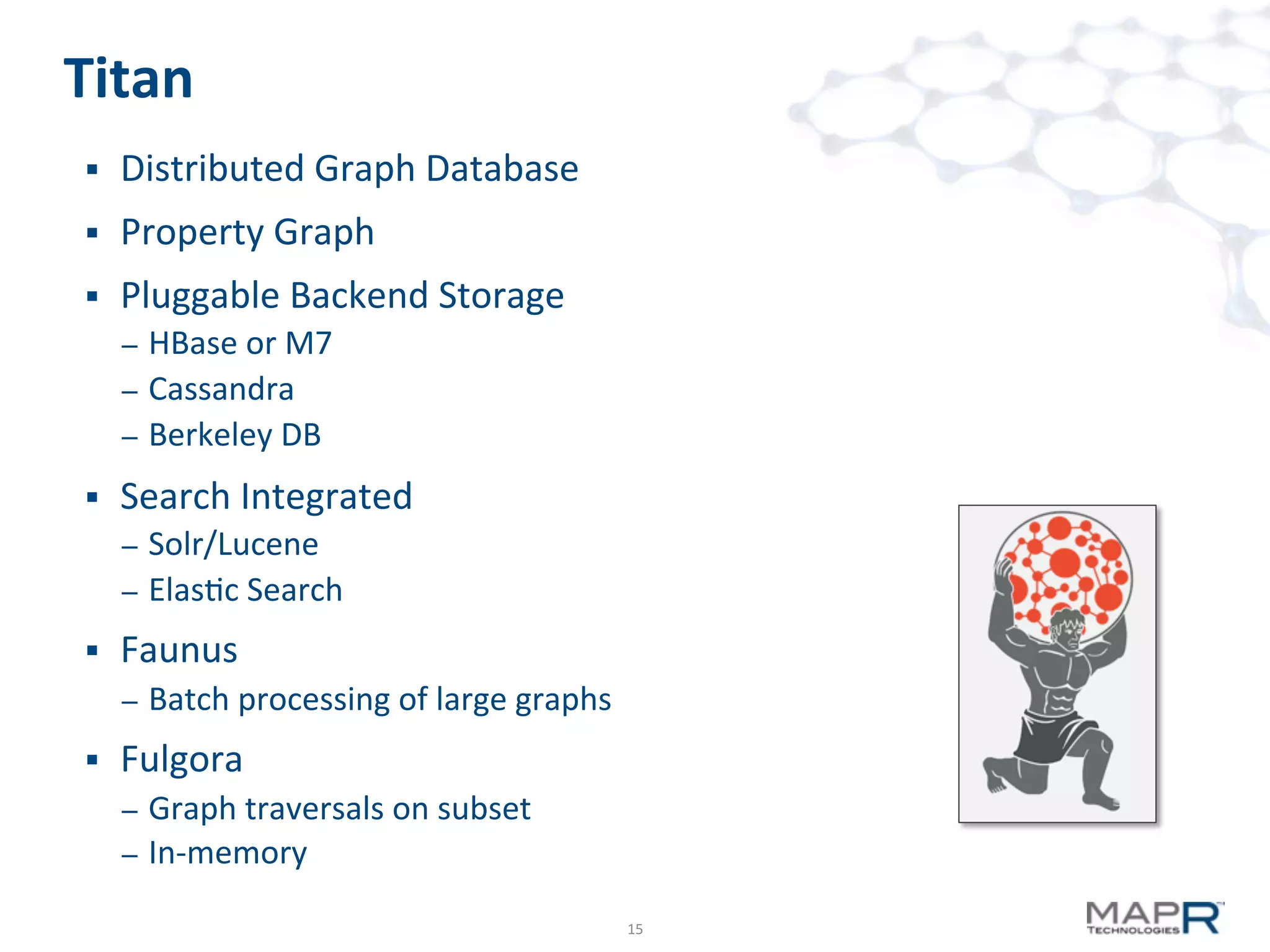
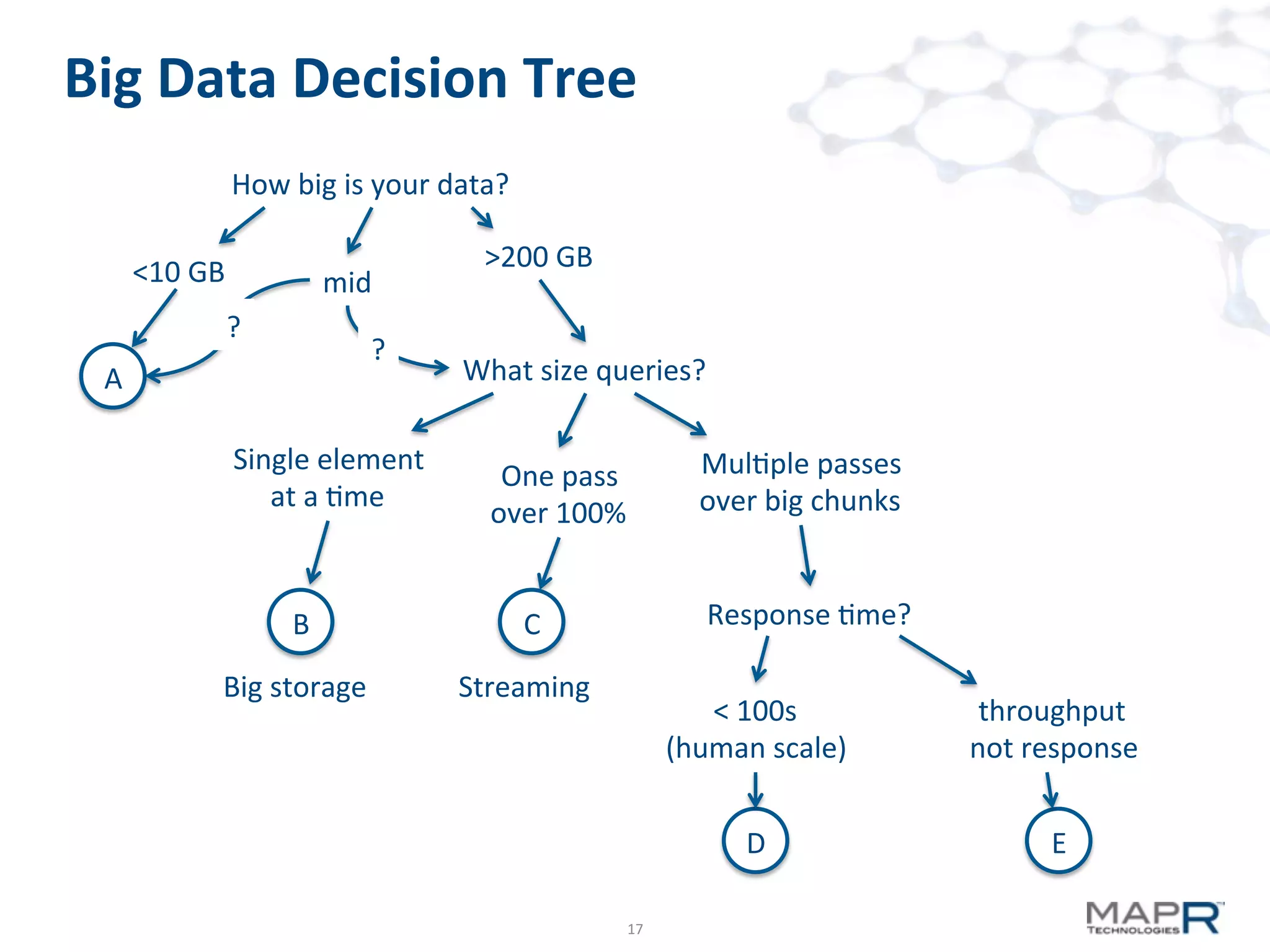
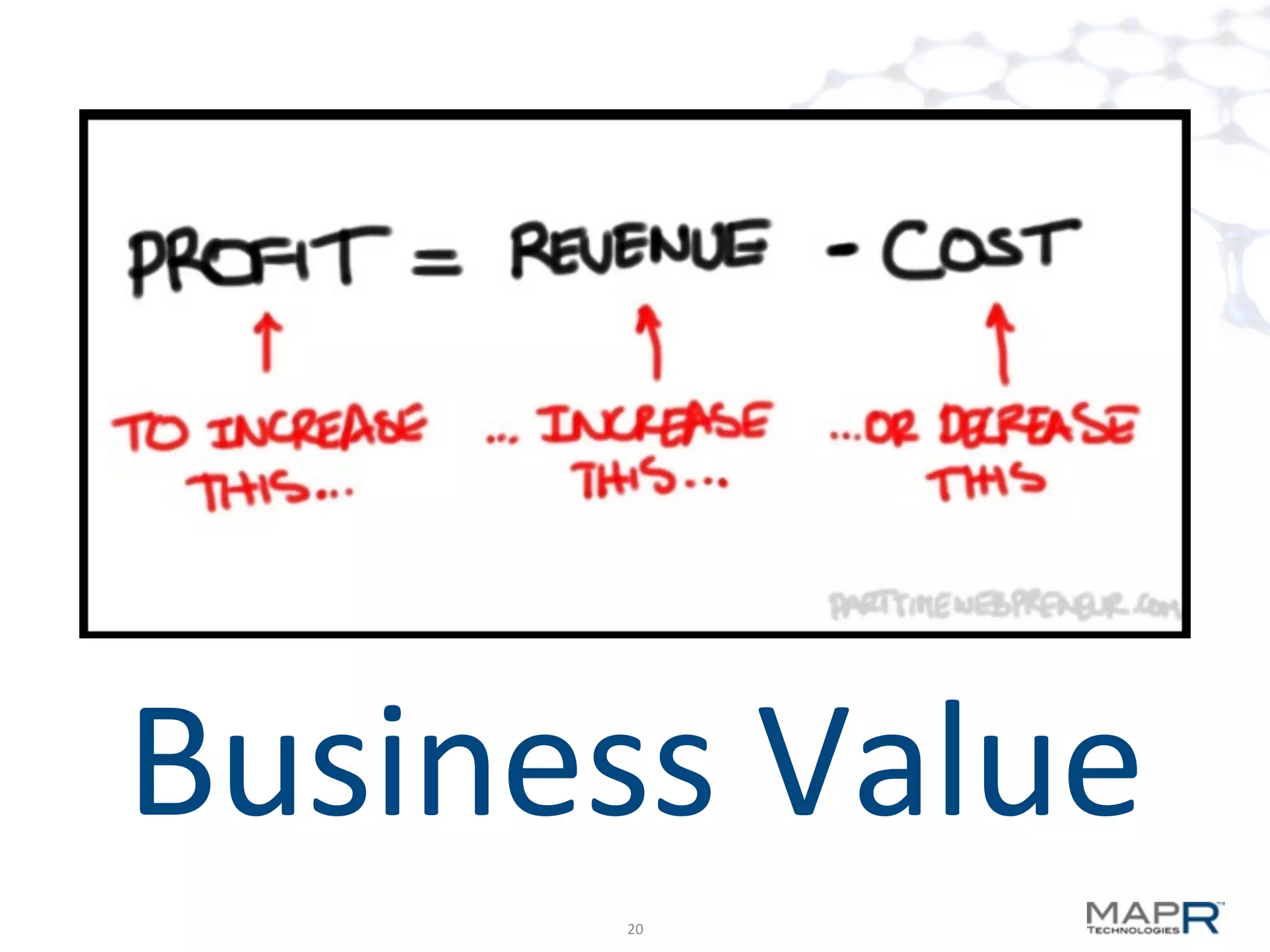
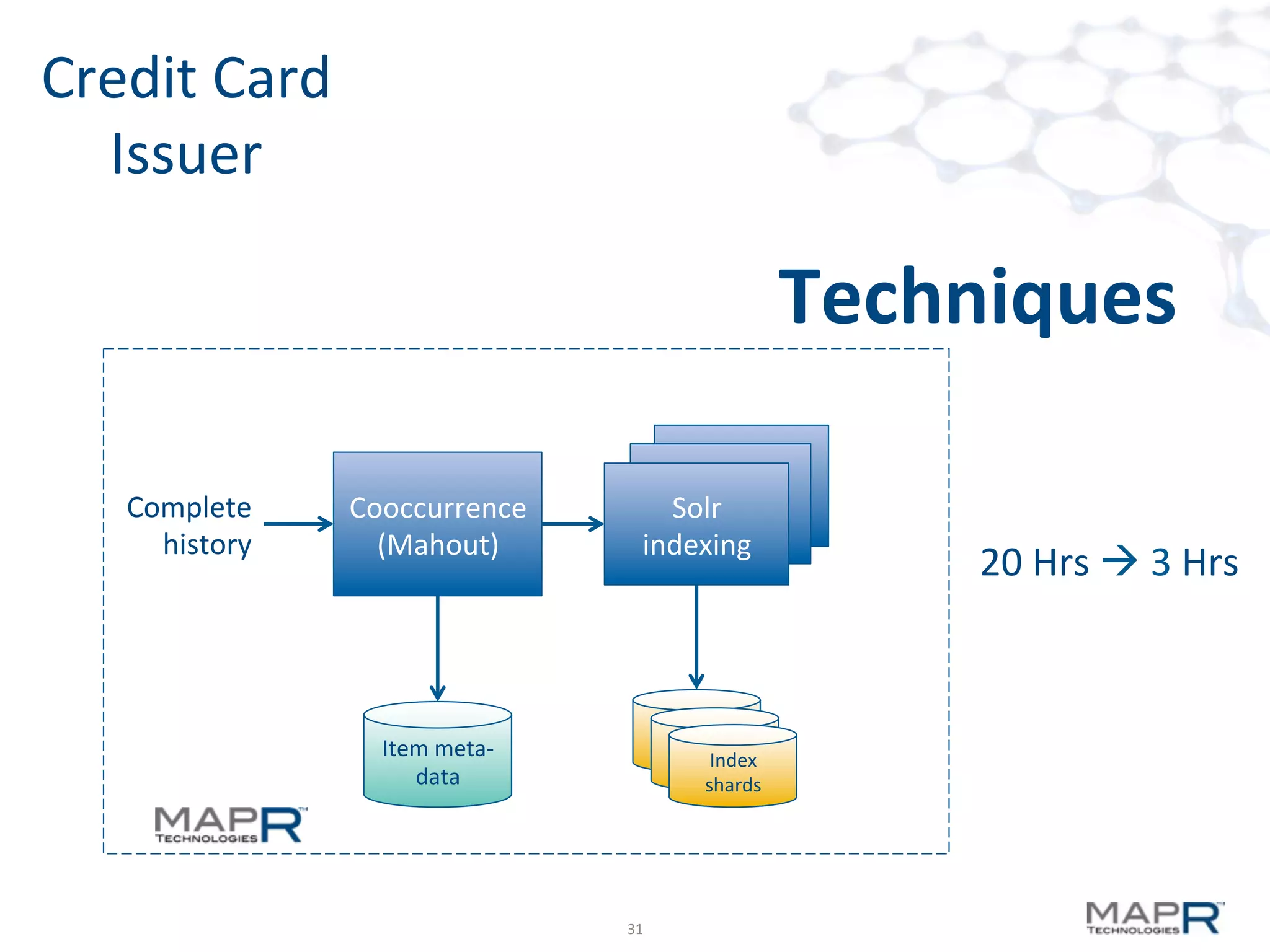
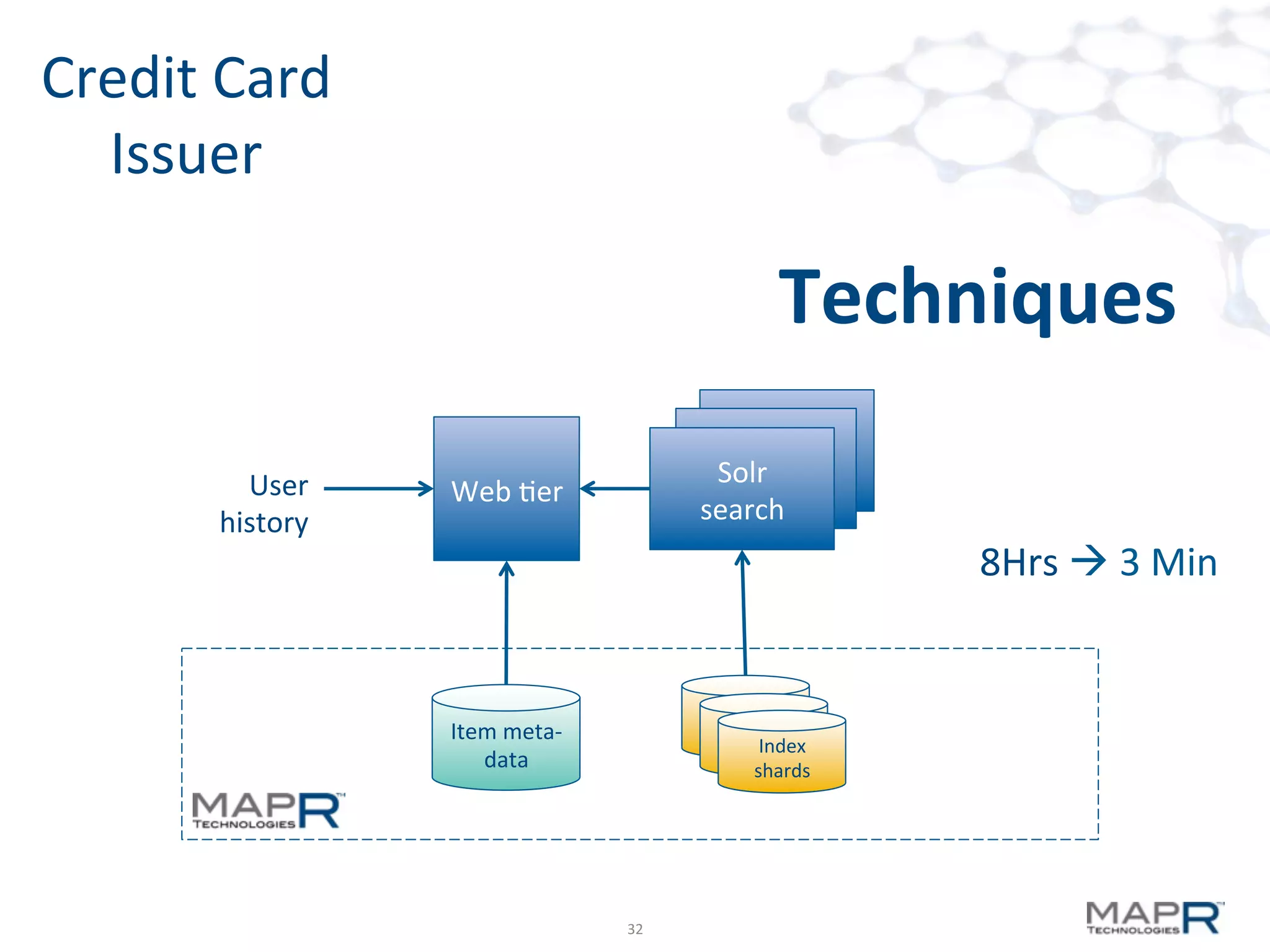
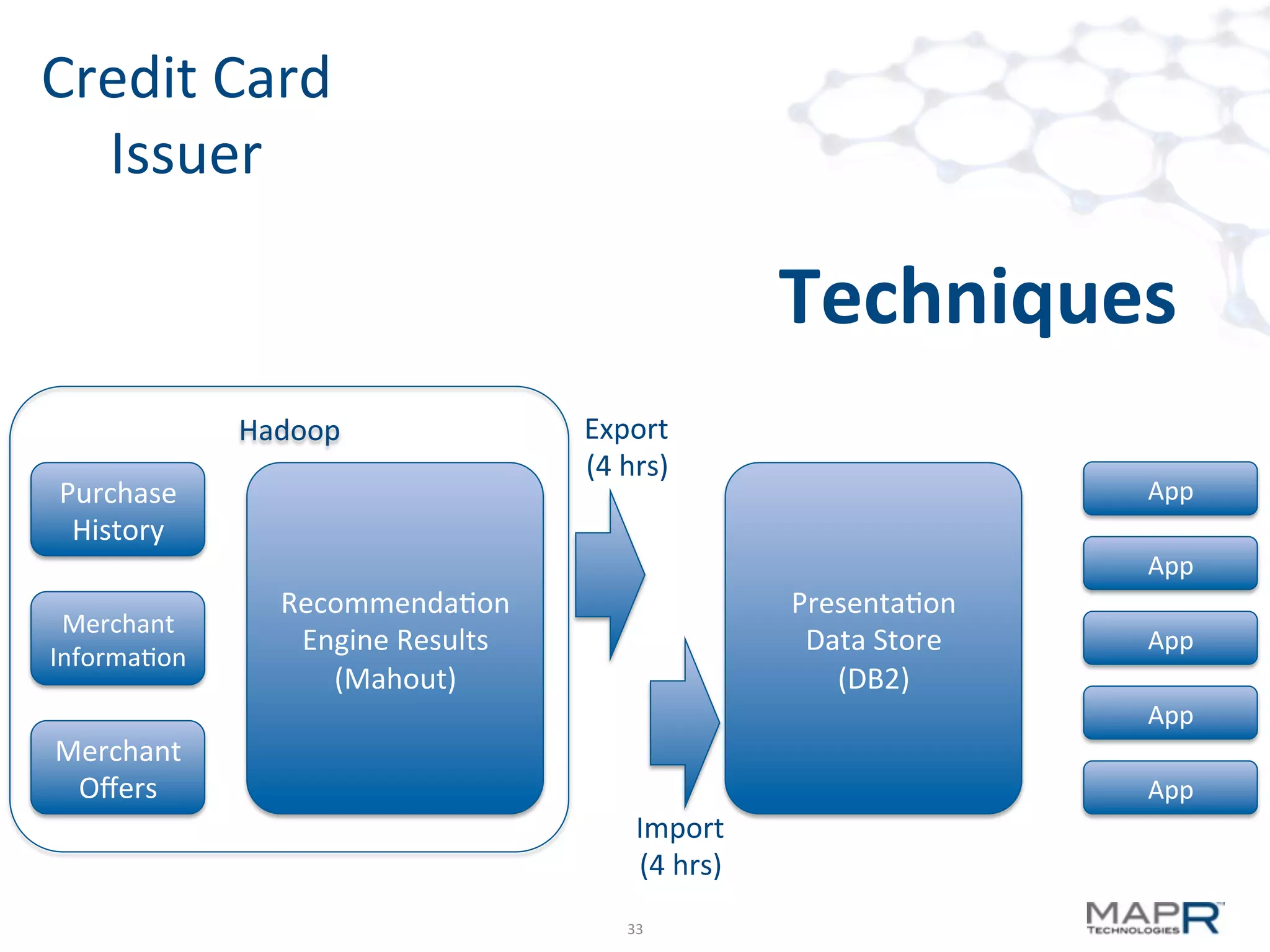
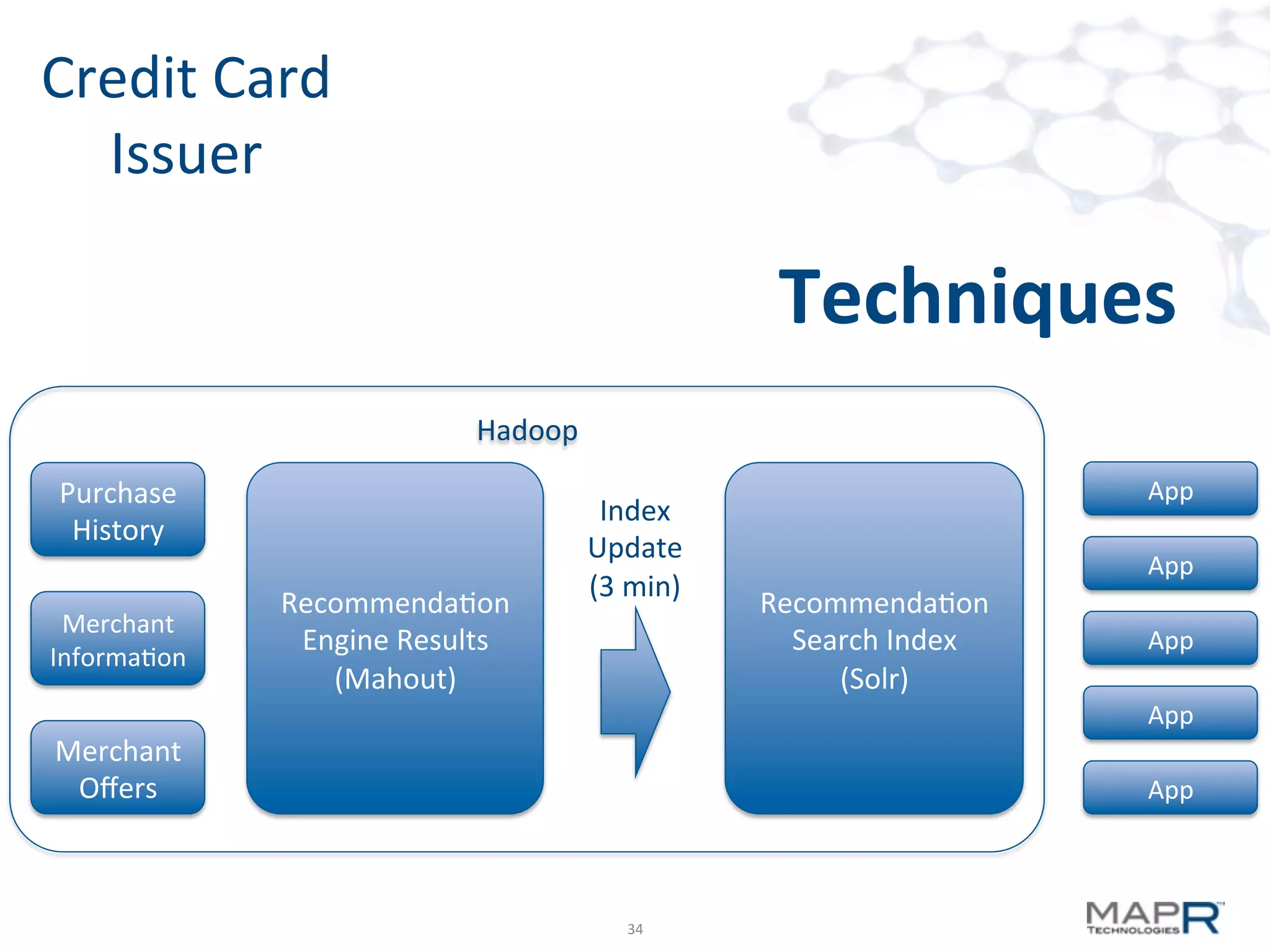
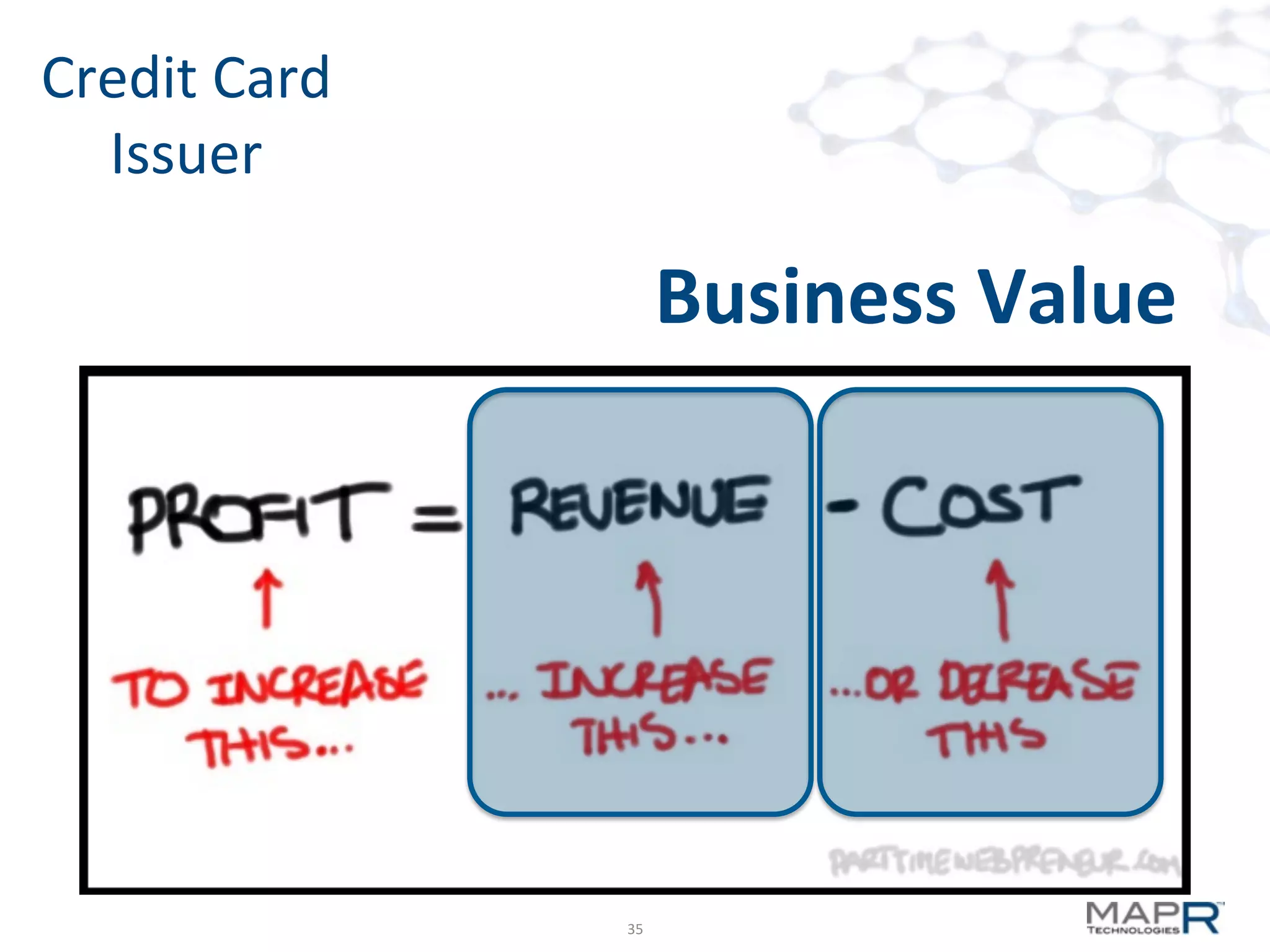
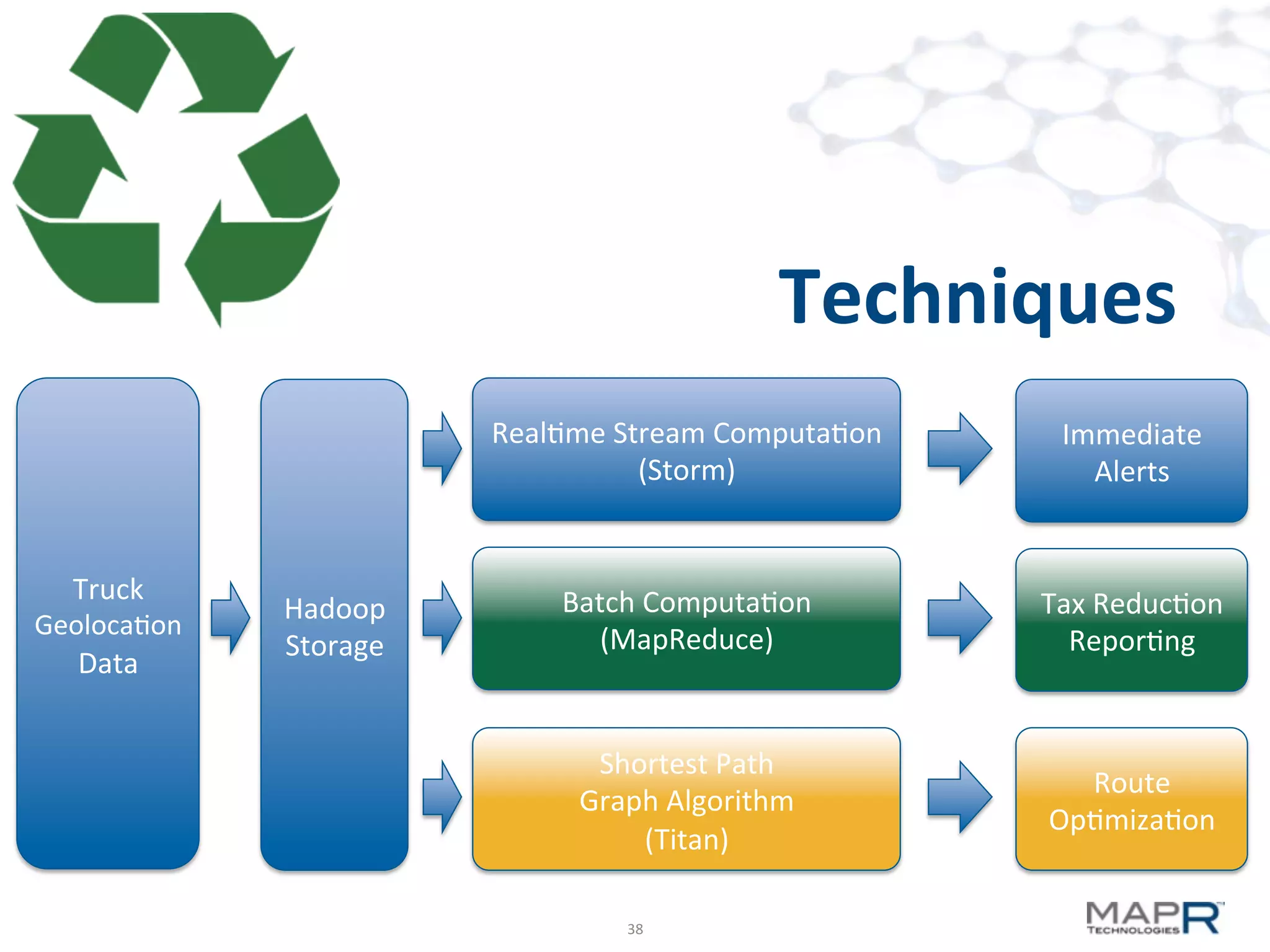
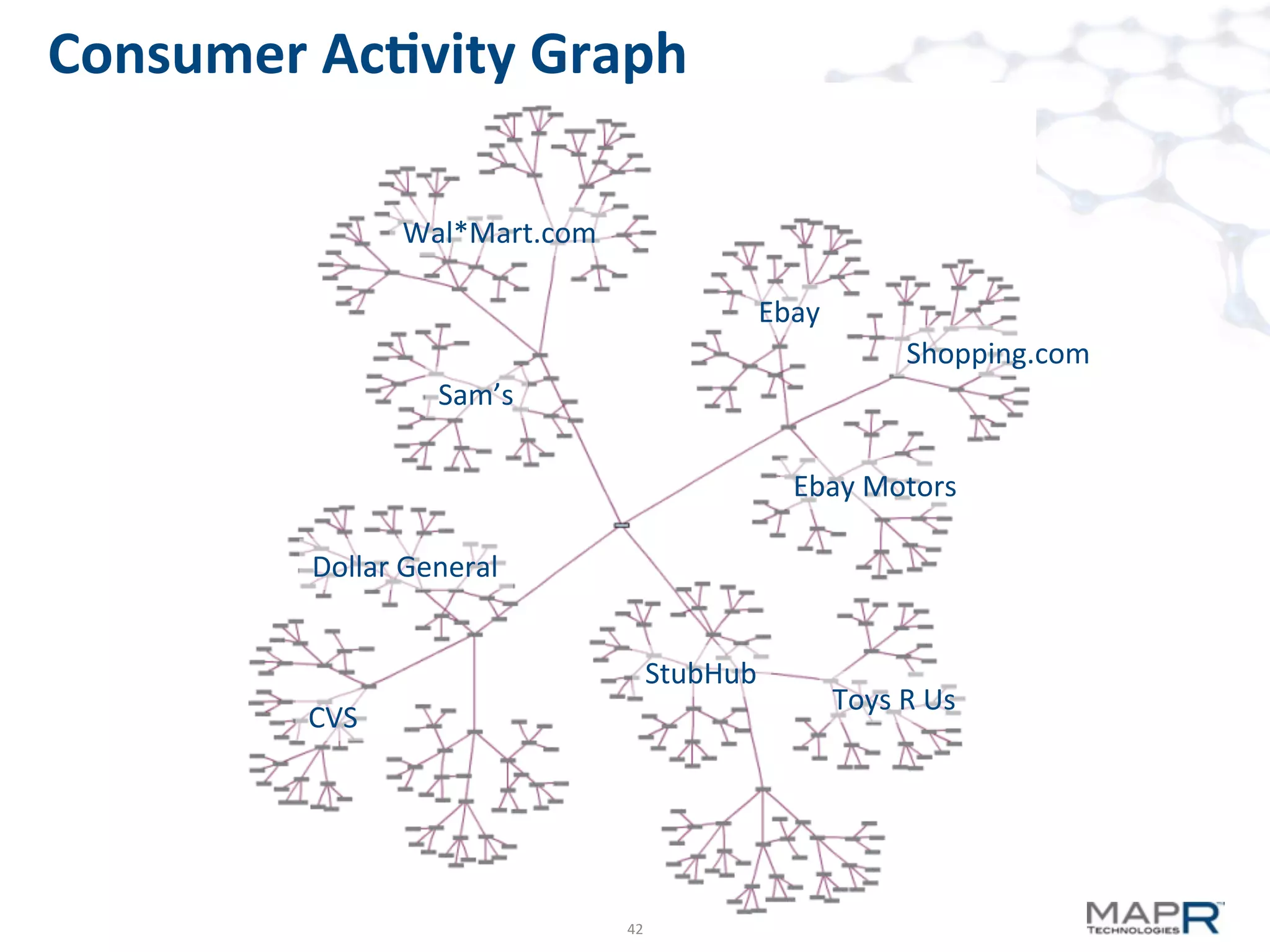
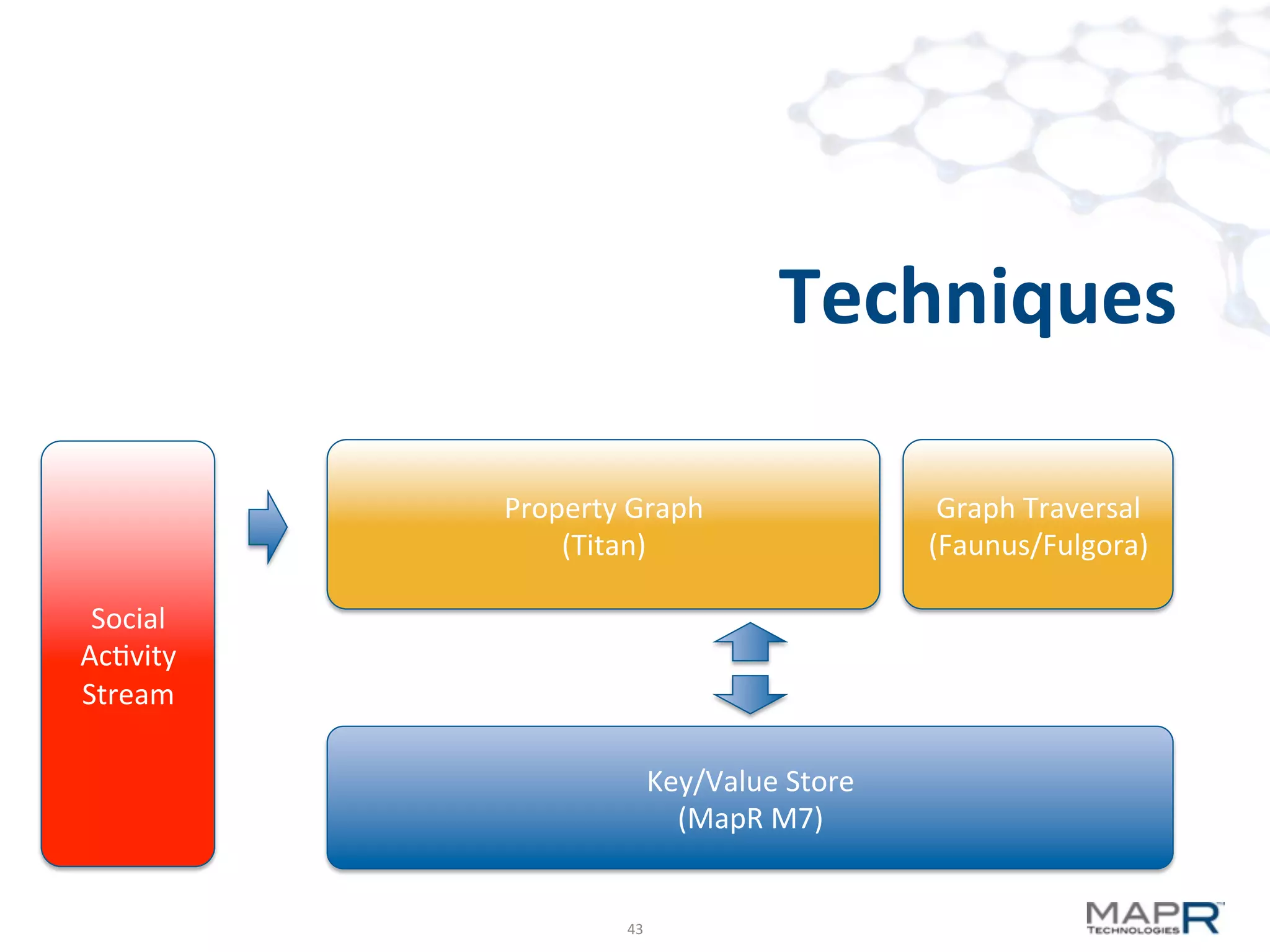
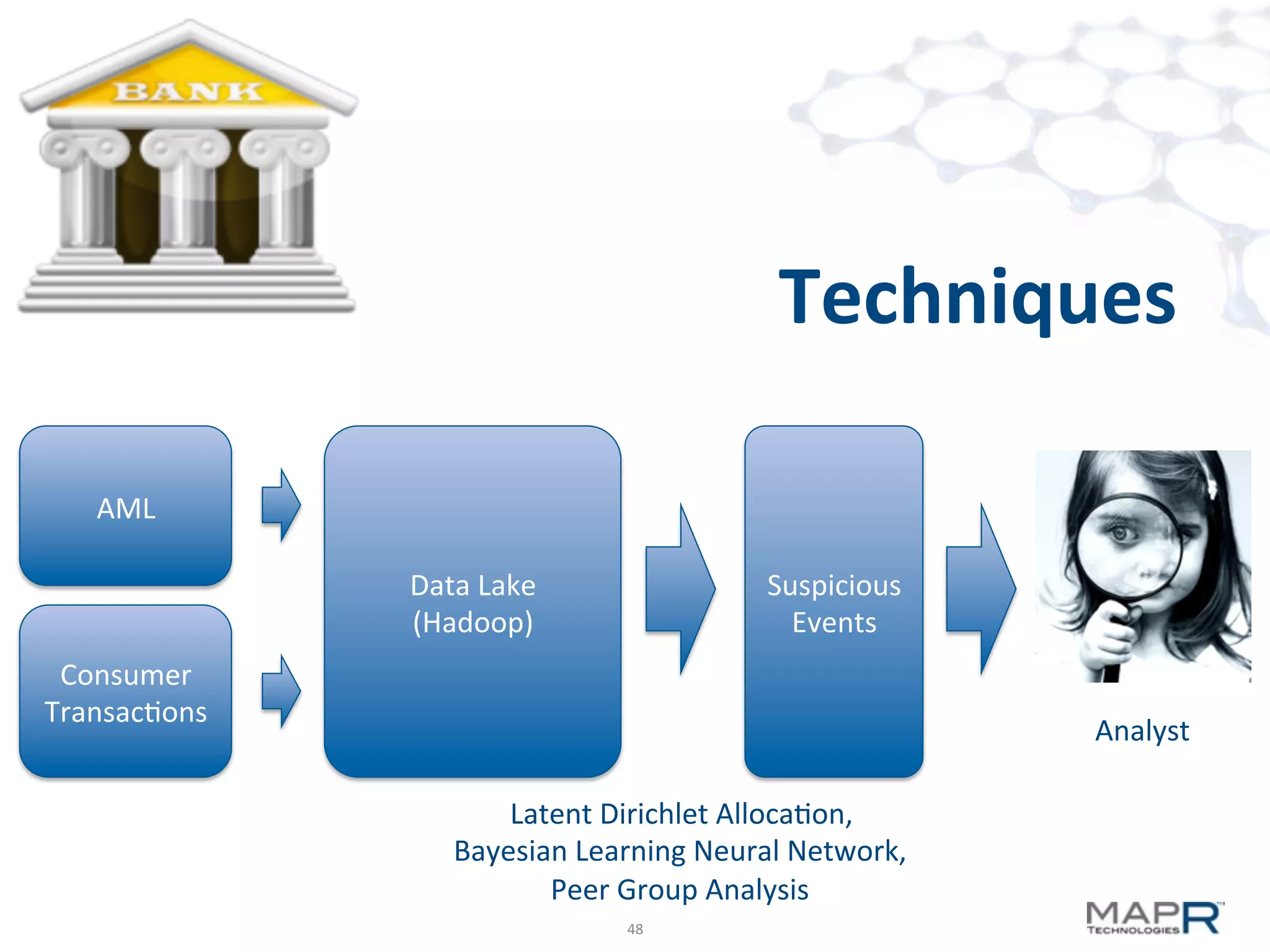
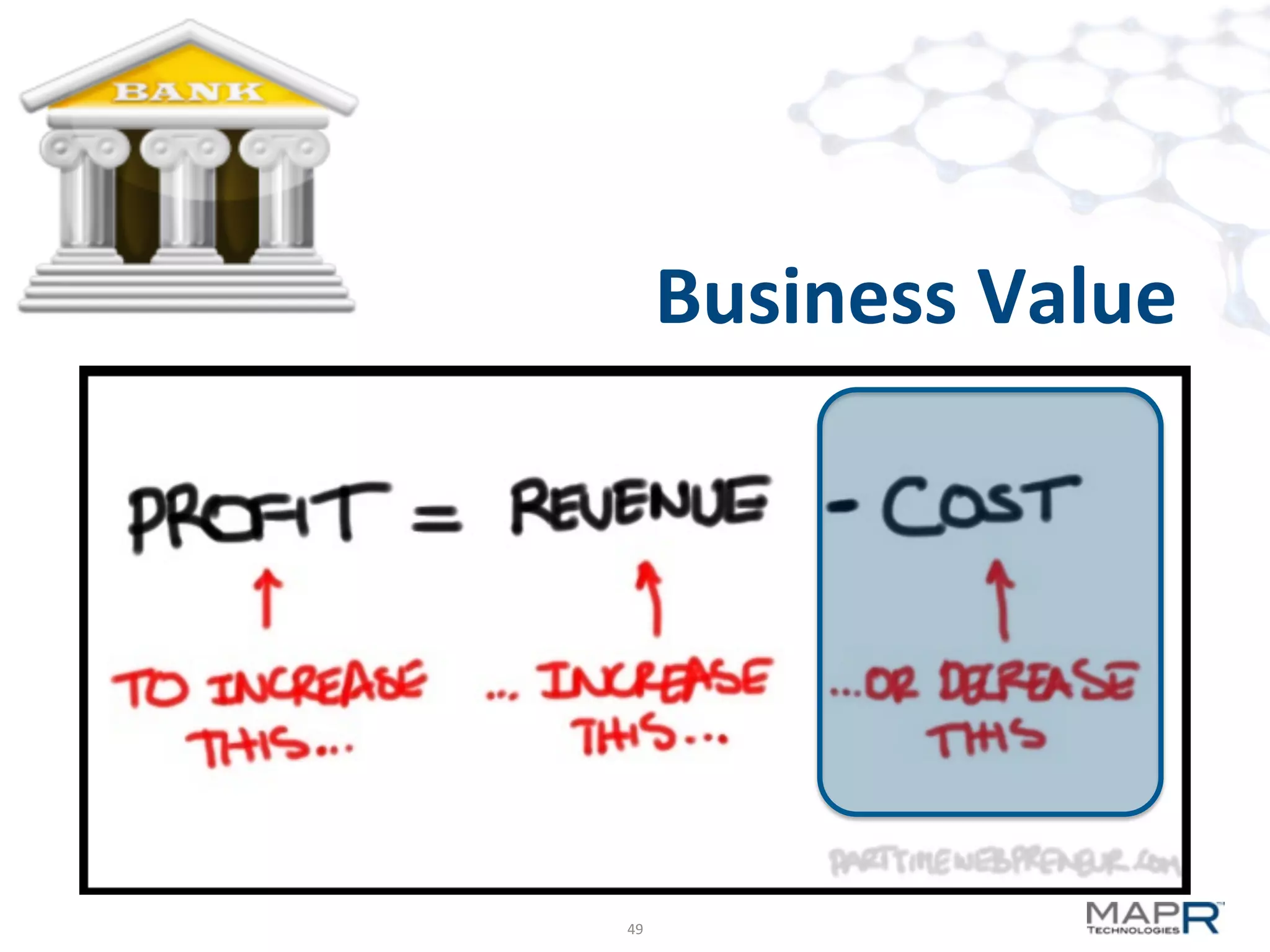
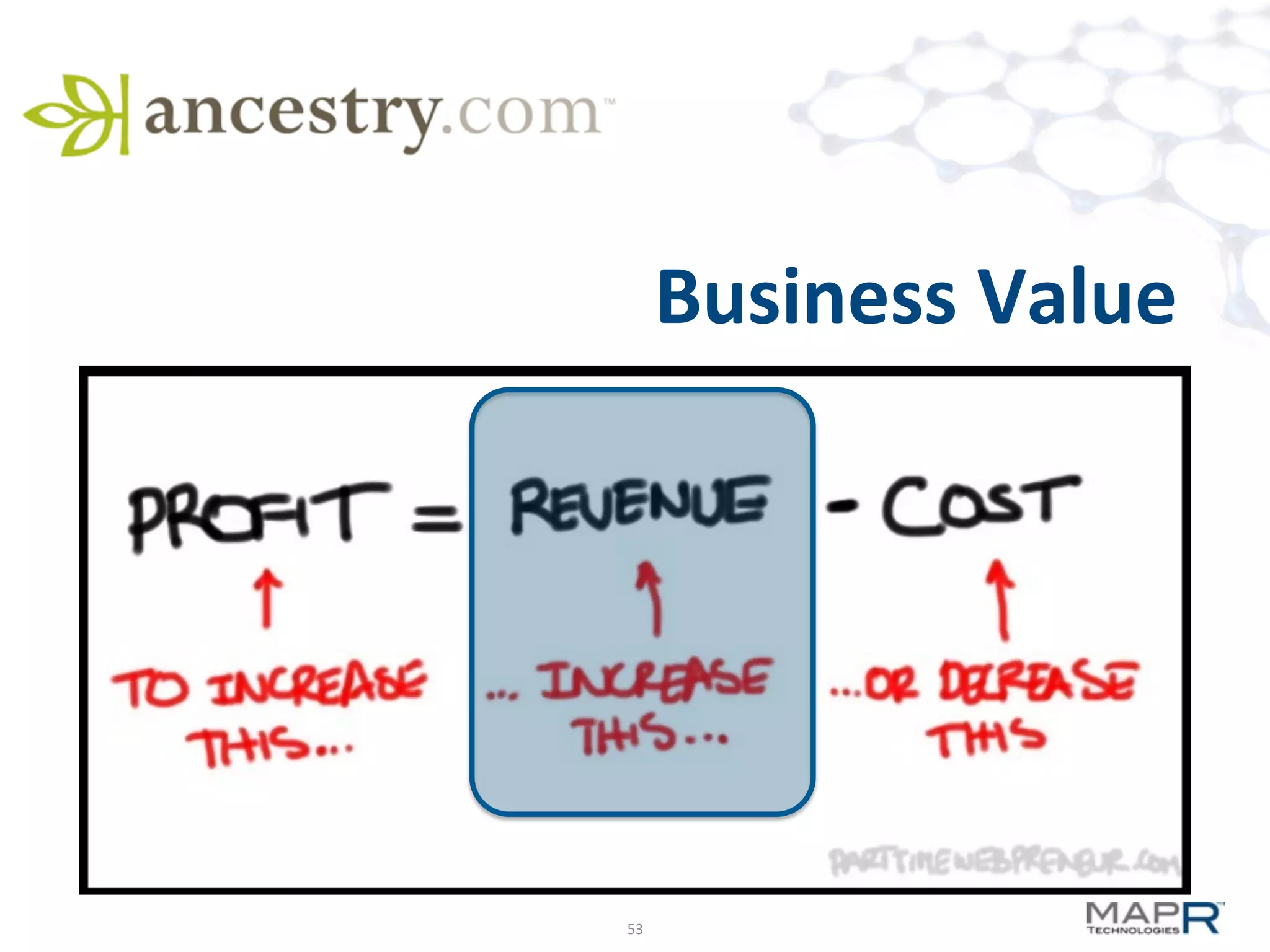
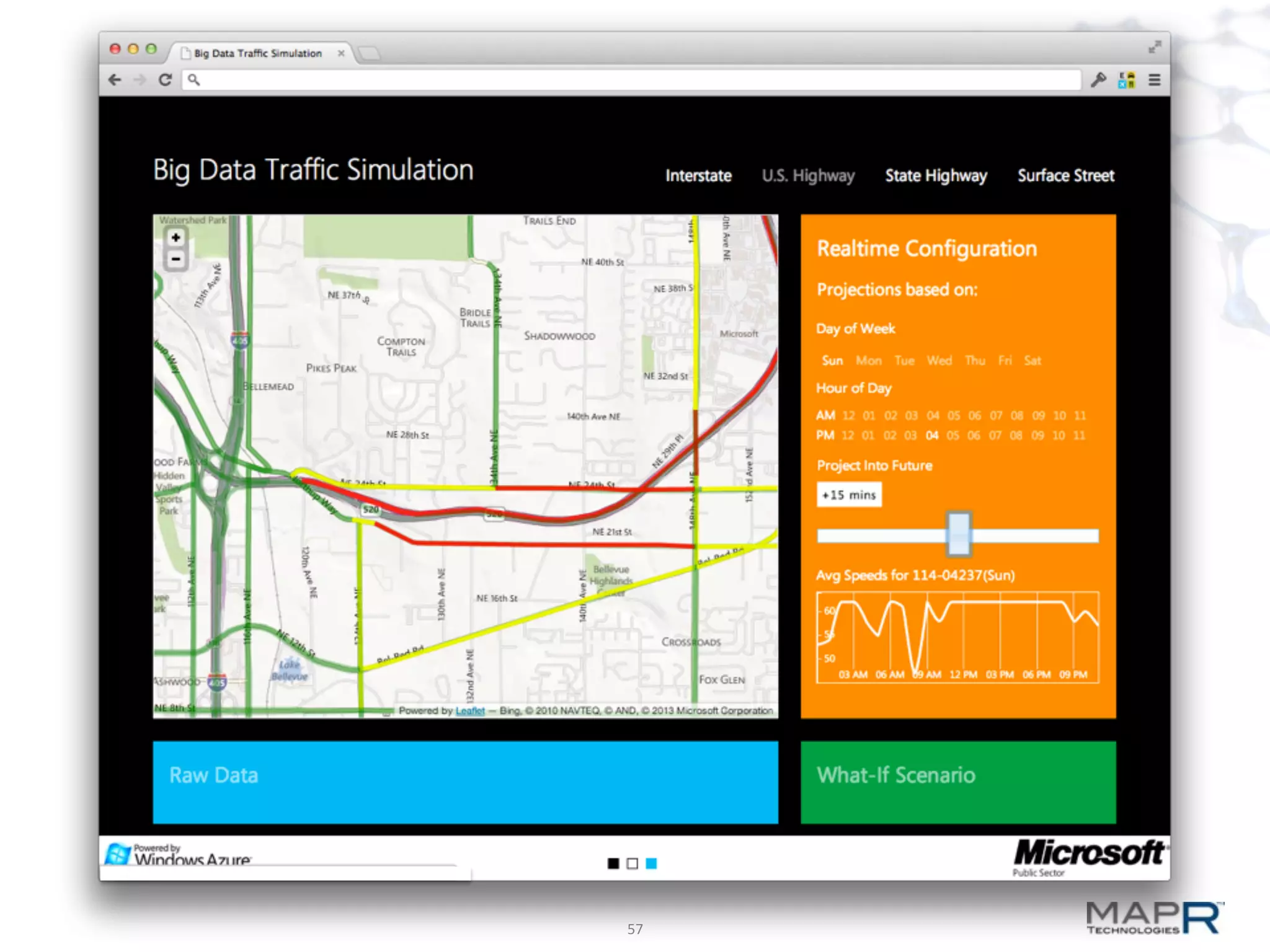
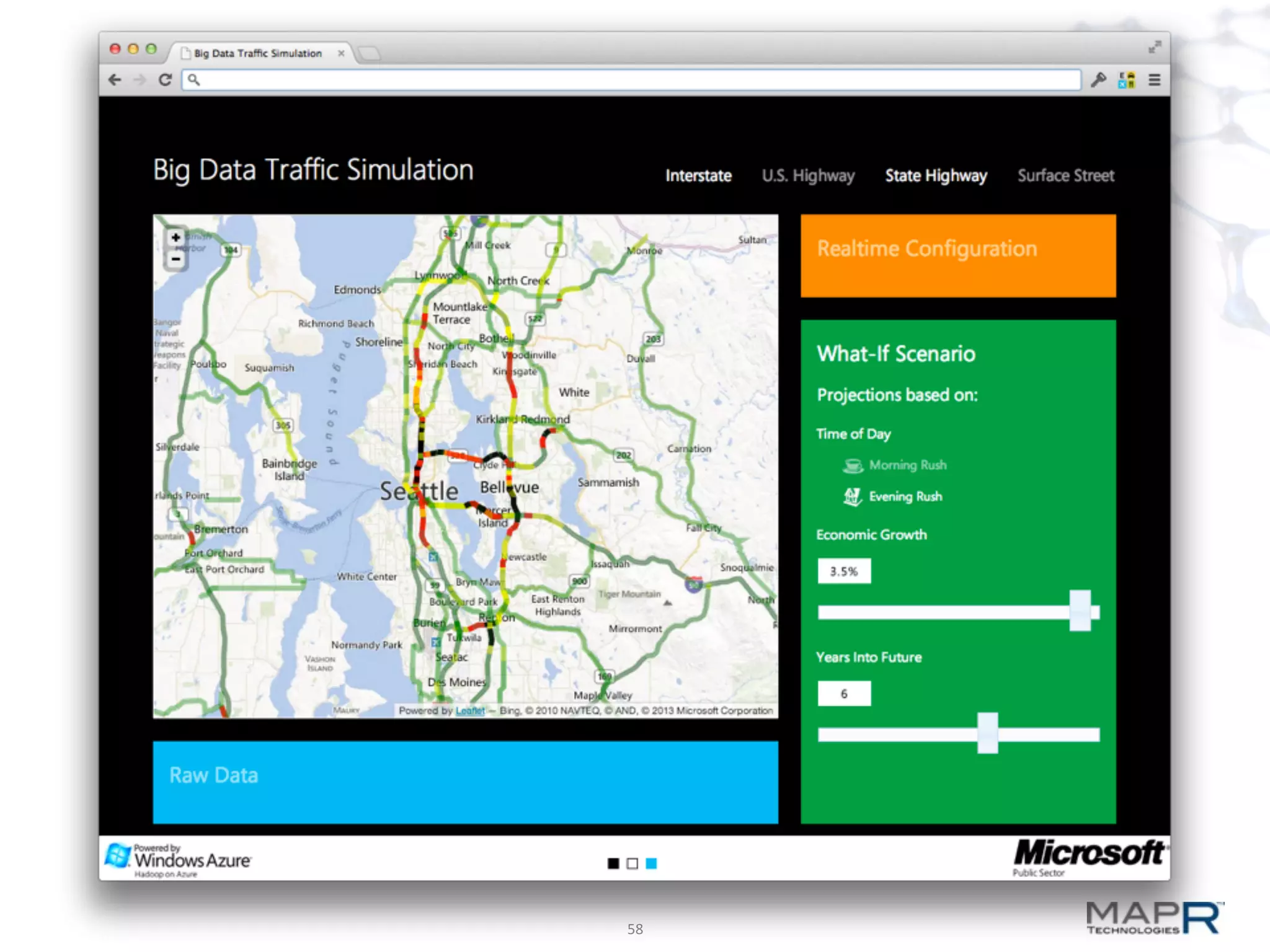
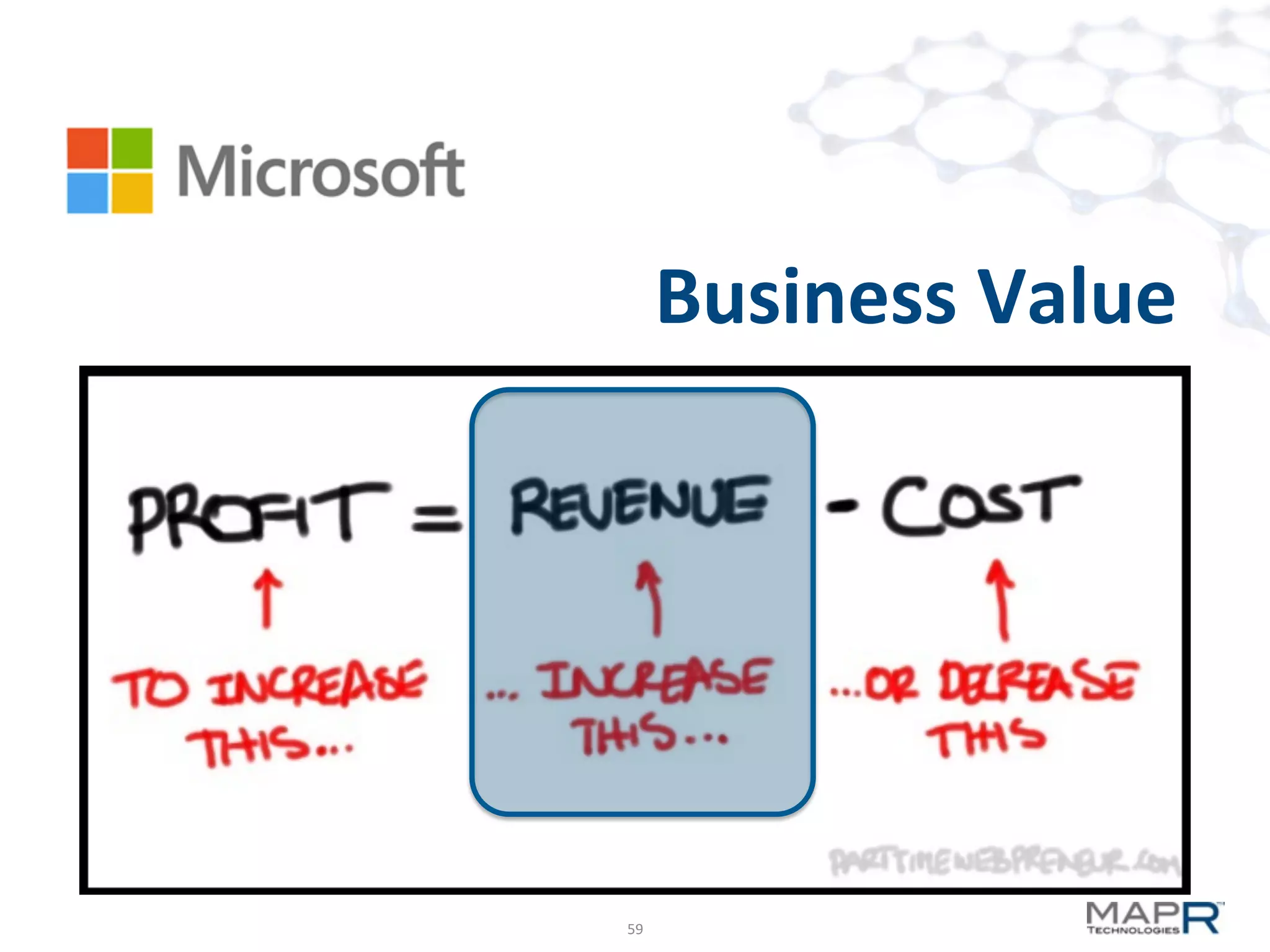
The document discusses big data analysis patterns presented by Brad Anderson at an Atlanta user group meeting. It highlights various technologies and tools, such as Apache Hadoop, Mahout, and Storm, and emphasizes the importance of defining specific business problems to select appropriate solutions for processing and analyzing large datasets. Additionally, it outlines various use cases across industries including telecommunications and finance, showcasing how big data can generate business value through effective analytics and real-time processing.











































































































































































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
